如果你想知道你的服务器正在做干什么,你就需要了解一些基本的命令,一旦你精通了这些命令,那你就是一个专业的 Linux 系统管理员。
监控命令##
iostat###
iostat命令用来显示存储系统的详细信息,通常用它来监控磁盘 I/O 的情况。要特别注意 iostat 统计结果中的 %iowait 值,太大了表明你的系统存储系统性能低下。
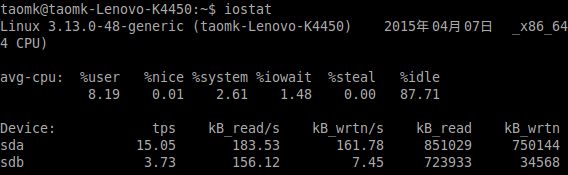
命令: iostat -m -x 1 1000
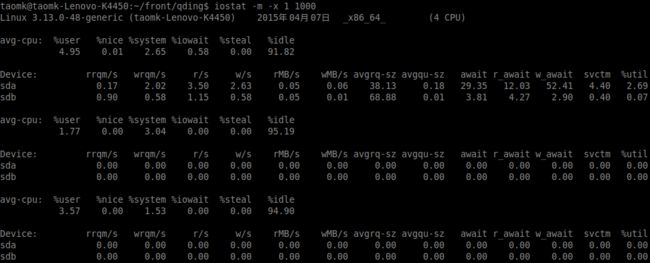
可以观察对应的CPU中的%iowait数据,除此之外iostat还提供了一些更详细的I/O状态数据,比如比较重要的有:
**avgqu-sz : ** The average queue length of the requests that were issued to the device. (磁盘队列的请求长度,正常的话2,3比较好。可以和cpu的load一样的理解)。
**await : **The average time (in milliseconds) for I/O requests issued to the device to be served. (代表一个I/O操作从wait到完成的总时间)。
svctm和%util都是代表处理该I/O请求花费的时间和CPU的时间比例。 判断是否瓶颈时,这两个参数不是主要的。
r/s w/s 和 rMB/s wMB/s 都是代表当前系统处理的I/O的一些状态,前者是我们常说的tps,后者就是吞吐量。这也是评价一个系统的性能指标。
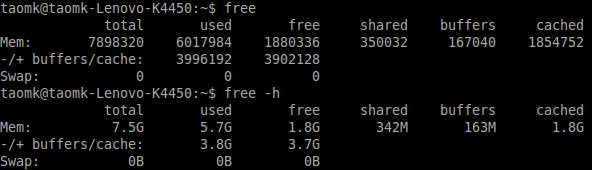
meminfo 和 free###
Meminfo 可让你获取内存的详细信息,你可以使用 cat 和 grep 命令来显示 meminfo 信息:
cat /proc/meminfo
另外你可以使用 free 命令来显示动态的内存使用信息,free 只是给你大概的内存信息,而 meminfo 提供的信息更加详细。
mpstat###
mpstat是MultiProcessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
mpstat的语法如下:mpstat [-P {|ALL}] [internal [count]],参数的含义如下:
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal 相邻的两次采样的间隔时间
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。

命令:mpstat -P ALL 1 1000
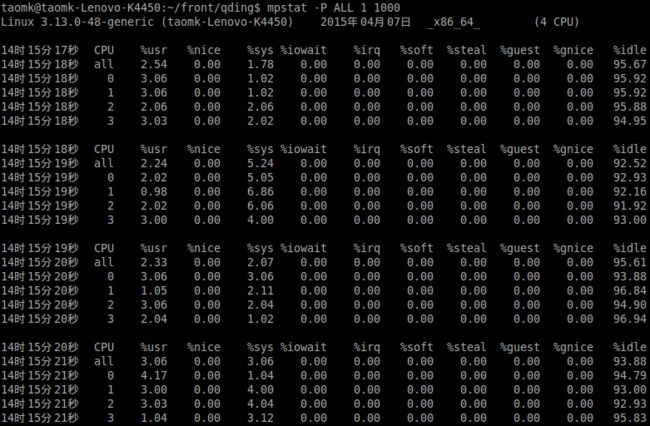
CPU 处理器ID
user 在internal时间段里,用户态的CPU时间(%),不包含 nice值为负 进程 (usr/total)*100
nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
system 在internal时间段里,核心时间(%) (system/total)*100
iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
irq 在internal时间段里,硬中断时间(%) (irq/total)*100
soft 在internal时间段里,软中断时间(%) (softirq/total)*100
idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%)(idle/total)*100
intr/s 在internal时间段里,每秒CPU接收的中断的次数intr/total)*100
CPU总的工作时间=total_cur=user+system+nice+idle+iowait+irq+softirq
total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq
user=user_cur – user_pre
total=total_cur-total_pre
其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。
注意:这里面的%iowait列,CPU等待I/O操作所花费的时间。这个值持续很高通常可能是I/O瓶颈所导致的。通过这个参数可以比较直观的看出当前的I/O操作是否存在瓶颈。
netstat###
Netstat 和 ps 命令类似,是 Linux 管理员基本上每天都会用的工具,它显示了大量跟网络相关的信息,例如 socket 的使用、路由、接口、协议、网络等等,下面是一些常用的参数:
-a Show all socket information
-r Show routing information
-i Show network interface statistics
-s Show network protocol statistics
nmon###
Nmon, 是 Nigel's Monitor 的缩写,是一个使用很普遍的开源工具,用以监控 Linux 系统的性能。Nmon 监控多个子系统的性能数据,例如处理器的使用率、内存使用率、队列、磁盘I/O统计、网络I/O统计、内存页处理和进程信息。Nmon 也提供了一个图形化的工具:
要运行 nmon,你可以在命令行中启动它,然后选择要监控的子系统,这些子系统都对应有一个快捷键,例如输入 c 可查看 CPU 信息,m用于查看内存,d用来查看磁盘信息等,你也可以使用 -f 命令将 nmon 的执行结果保存到一个 CSV 文件中,便于日后分析。
在每日的监控工作中,我发现 nmon 是我最常用的工具。
pmap###
pmap 命令用来报告每个进程占用内存的详细情况,可用来看是否有进程超支了,该命令需要进程 id 作为参数。
ps 和 pstree###
ps 和 pstree 命令是 Linux 系统管理员最好的朋友,都可以用来列表正在运行的所有进程。ps 告诉你每个进程占用的内存和 CPU 处理时间,而 pstree 显示的信息没那么详细,但它以树形结构显示进程之间的依赖关系,包括子进程信息。一旦发现某个进程有问题,你可以使用 kill 来杀掉它。
命令:ps -mp pid -o THREAD,tid,time 或者 ps -Lfp pid
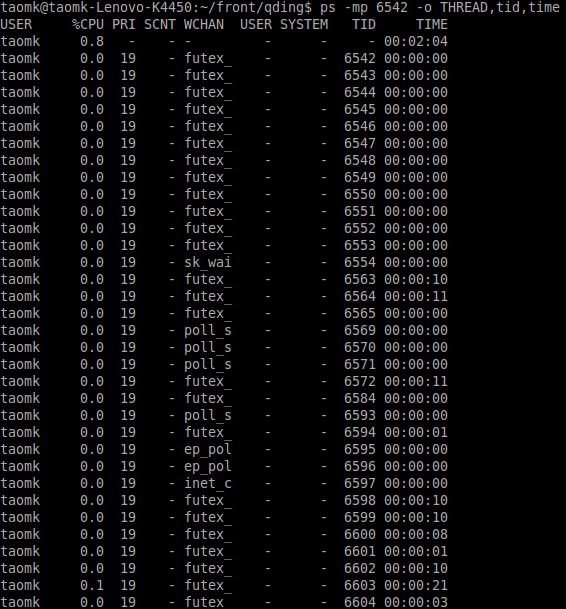
这个命令的作用,主要是可以获取到对应一个进程下的线程的一些信息。 比如你想分析一下一个java进程的一些运行瓶颈点,可以通过该命令找到所有当前Thread的占用CPU的时间,也就是这里的最后一列。
比如这里找到了一个TID : 6603,所占用的TIME时间最高。通过 printf "%x\n" 6603 首先转化成16进制, 继续通过jstack命令dump出当前的jvm进程的堆栈信息。 通过Grep命令即可以查到对应16进制的线程id信息,很快就可以找到对应最耗CPU的代码块在哪。
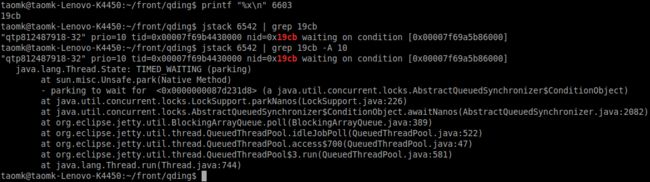
简单的解释下,jstack下这一串线程信息内容:
"qtp812487918-32" prio=10 tid=0x00007f69b4430000 nid=0x19cb waiting on condition [0x00007f69a5b86000]
**nid : **对应的linux操作系统下的tid,就是前面转化的16进制数字
tid:这个是jvm的jmm内存规范中的唯一地址定位,如果你详细分析jvm的一些内存数据时用得上
pidstat###
命令: pidstat -p pid -u -d -t -w -h 1 1000
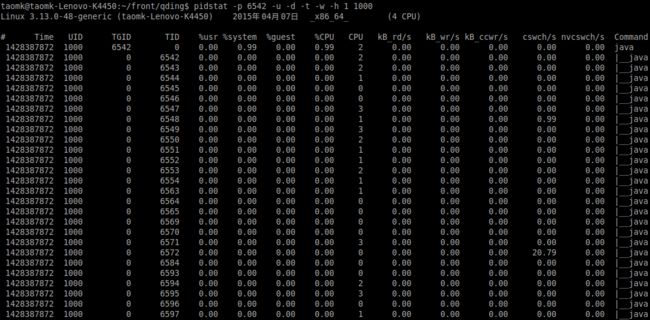
相当实用的一个命令,可以基于当个进程分析对应的性能数据,包括CPU,I/O,IR , CS等,可以方便开发者更加精细化的观察系统的运行状态。不过pidstat貌似是在2.6内核的一些较新的版本才有,需要安装sysstat包。在ubuntu下,可以通过sudo apt-get install sysstat进行安装。
pidstat强大之处在于它不仅可以监视进程的性能情况,也可以监视线程的性能情况。
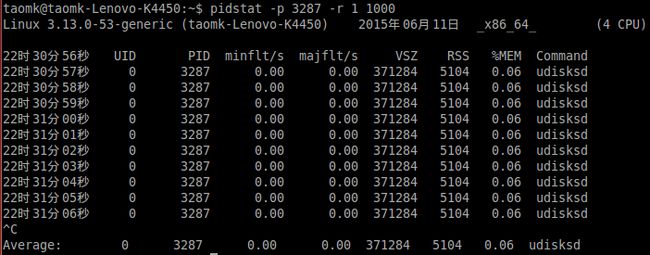
命令:pidstat -p 3287 -r 1 1000 查看进程内存监控
dstat###
命令:dstat -y --tcp 1 1000
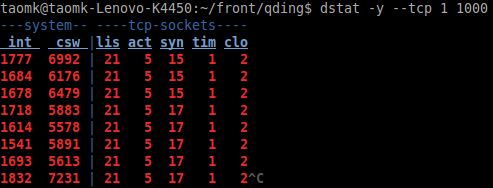
通过dstat --tcp可以比较方便的看到当前的tcp的各种状态,不需要每次netstat -nat去看
tcpdump###
tcpdump 是一个简单、可靠的网络监控工具,用来做基本的协议分析,看看那些进程在使用网络以及如何使用网络。当然,如果你要获取跟详细的信息,你应该使用 Wireshark。
top###
top 命令显示当前的活动进程,默认它是按消耗 CPU 的厉害程度进行排序,每5秒钟刷新一次列表,你也可以选择不同的排序方式,例如 m 是按内存占用方式进行排序的快捷键。
命令:top -Hp pid
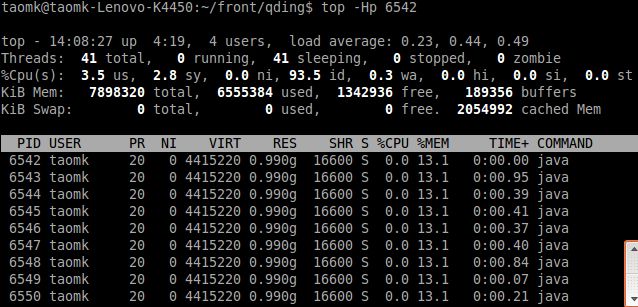
可以实时的跟踪并获取指定进程中最耗cpu的线程。再用ps命令中提到的jstack方法提取到对应的线程堆栈信息。
默认情况下,Top 被调用时使用交互模式。在此模式下,Top 无限期运行,并可以通过按键重新定义 Top 的运行方式。但是,有时你需要对 Top 的输出进行后续处理,但这在此模式下难以实现。解决方法?使用批处理模式。
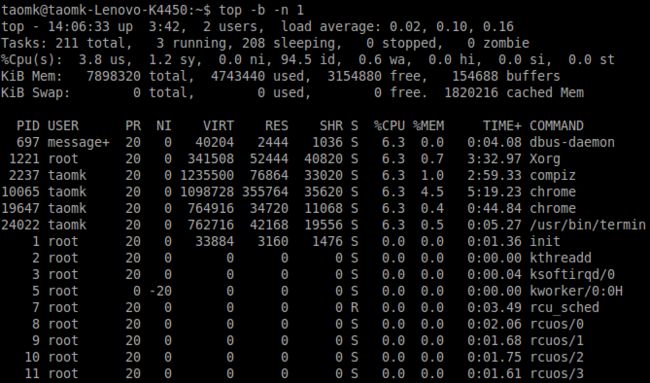
命令:top -b
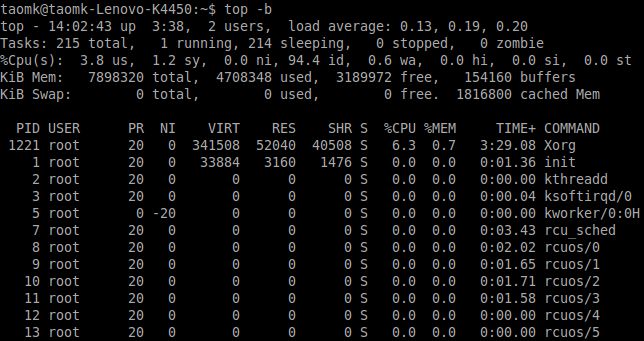
哈,等等,它是不断重复运行的,同交互模式一样。不用担心,你可以使用 -n 限制重复数量。所以,如果你希望获得一次性结果,键入:
命令:top -b -n 1
这一模式的真正优势在于你可以很容易的与 at 或 cron 命令结合。它们的结合,使得 Top 可以在特定时间对资源使用状态进行快照。例如,使用 at ,我们可以设定 top 在一分钟之后运行。
cat ./test.at
TERM=linux top -b -n 1 >/tmp/top-report.txt
at -f ./test.at now+1minutes
细心的读者可能会问“在创建新任务时,为什么我需要在调用 Top 之前设置环境变量 TERM?”。答案是,Top 运行时需要此变量,但“at”在定时调用时并不会保留它。同上面那样简单的设置可以确保 Top 正常运行。
如何监控制定进程
有时,我们只对几个进程感兴趣,可能只是全部进程中的4个或5个。例如,如果你想要监测进程标识(PID)为4360和4358的进程,你需要键入:top -p 19647,10065
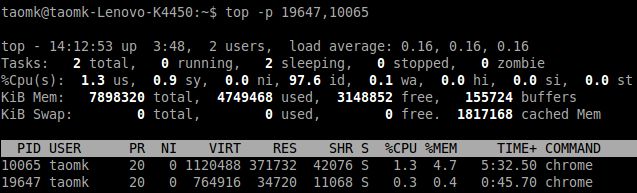
看起来很简单,只需要使用 -p 列出所有需要的 PID,并使用逗号间隔或简单的多次使用 -p即可。
另一种可能是监测拥有特定用户标识(UID)的进程。应对此需求,你可以使用 -u 或 -U 选项。假设用户“johndoe”的 UID 为500,键入:top -u taomk
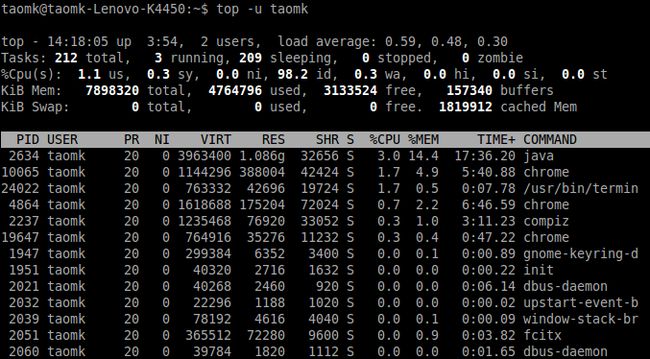
或:top -U taomk
结论是,你既可以纯使用用户名,也可使用数字 UID。“-u,-U?这两者不同?”是的。同多数其它 GNU 工具一样,选项是大小写敏感的。-U 意味着 Top 将会搜索有效的、真实的、被保存的以及文件系统的 UID 进行匹配,而 -u 仅匹配有效的用户id。要知道,每一个 Linux 进程在运行时都是用有效用户标识(effective UID),而其中有些并不等同真实用户标识。多数情况是,对类似文件系统权限或操作系统功能这项的有效用户标识感兴趣的人将会检查它,而不是 UID。
不同于 -p 仅用于命令行选项,-U 和 -u 都可以在交互模式中使用。同你猜测的一样,键入‘U’或‘u’可以依据用户名过滤进程。同样的规则依然适用,‘u’为有效用户标识,‘U’为 真实/有效/保存/文件系统用户名。你将被要求键入用户名或数字 UID。
sar###
sar命令也是Linux系统中重要的性能监测工具之一,它可以周期性地对内存和CPU使用情况进行采样。
命令:sar -u 1 3 查看CPU使用率

命令:sar -r 1 3 查看内存使用率

命令:sar -b 1 3 查看I/O使用率

uptime###
uptime 命令告诉你这台服务器从开机启动到现在已经运行了多长时间了。同时也包含了从启动到现在服务器的平均负载情况:

vmstat###
你可以使用 vmstat 来监控虚拟内存,一般 Linux 上的开发者喜欢使用虚拟内存来获得最佳的存储性能。该命令报告关于内核线程、虚拟内存、磁盘、陷阱和 CPU 活动的统计信息。由 vmstat 命令生成的报告可以用于平衡系统负载活动。系统范围内的这些统计信息(所有的处理器中)都计算出以百分比表示的平均值,或者计算其总和。
vmstat:可以查看内存,交互区分,I/O操作,上下文切换,时钟中断以及CPU的使用情况。

命令:vmstat 1 3

其他命令###
netstat -natp : 查看对应的网络链接,关注下Recv-Q , Send-Q , State。
lsof -p pid : 查找对应pid的文件句柄
lsof -i : 80 : 查找对应端口被哪个进程占用
lsof /tmp/1.txt :查找对应文件被哪个进程占用
tcpdump / wireshark :抓包分析工具
jstat / jmap / jstack / jps :等一系列的java监控命令
CPU命令##
查看系统内核信息###
命令:uname -a
命令:uname -r
查看系统发行版信息###
命令:cat /etc/issue
命令:cat /proc/version
查看系统CPU逻辑核数###
命令:cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
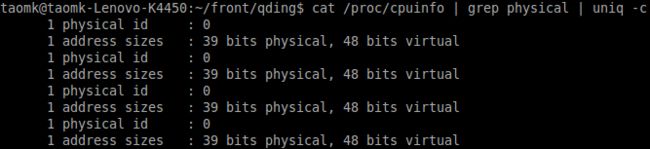
查看系统CPU物理核数###
命令:cat /proc/cpuinfo | grep physical | uniq -c
命令:grep "model name" /proc/cpuinfo

查看系统CPU运行位数###
命令:getconf LONG_BIT
说明:当前CPU运行在64bit模式下
查看系统CPU是否支持64位计算###
命令:cat /proc/cpuinfo | grep flags | grep ' lm ' | wc -l
说明:结果大于0, 支持64bit计算. lm指long mode, 支持lm则是64bit
查看系统Shell脚本###
#!/bin/bash
hostname=`hostname`
ip_addr=`ifconfig | grep inet | grep Bcast | tr -s " "`
os_name=`cat /etc/issue | head -n1`
os_bit=`getconf LONG_BIT`
cpu=`cat /proc/cpuinfo | grep name | cut -f2 -d: | head -n1`
cpu_core=`cat /proc/cpuinfo | grep name | cut -f2 -d: | wc -l`
memory_kb=`cat /proc/meminfo | grep MemTotal | awk '{print $(NF-1)}'`
memory_mb=`expr $memory_kb / 1024`
memory_gb=`expr $memory_mb / 1024`
memory="$memory_gb GB; $memory_mb MB; $memory_kb KB"
memory_cmd='free -m'
echo "hostname : $hostname"
echo "ip_addr : $ip_addr"
echo
echo "os_name : $os_name"
echo "os_bit : $os_bit bit"
echo "cpu : $cpu"
echo "cpu_core : $cpu_core"
echo
echo "memory : $memory"
$memory_cmd
cat /proc/cpuinfo命令###
- processor:逻辑处理器的id。
- physical id:物理封装的处理器的id。
- core id:每个核心的id。
- cpu cores:位于相同物理封装的处理器中的内核数量。
- siblings:位于相同物理封装的处理器中的逻辑处理器的数量。
查看物理CPU的个数:cat /proc/cpuinfo |grep "physical id"|sort |uniq| wc -l
查看逻辑CPU的个数:cat /proc/cpuinfo |grep "processor"|wc -l
查看CPU是几核:cat /proc/cpuinfo |grep "cores"|uniq
查看CPU的主频:cat /proc/cpuinfo |grep MHz|uniq
日期时间##
date命令###
查看当前系统时间:date

修改当前系统时间:date -s "2009-07-28 15:32:00"
解压缩命令##
tar解压###
tar -zvxf httpd-2.2.11.tar.gz:解压.tar.gz格式的文件;
tar xvf wordpress.tar:解压tar格式的文件;
tar -tvf myfile.tar:查看tar文件中包含的文件;
tar xjf www.tar.bz2:解压tar.bz2格式;
tar压缩###
tar cf toole.tar tool:把tool目录打包为toole.tar文件;
tar cfz vpser.tar.gz tool:把tool目录打包且压缩为vpser.tar.gz文件,因为.tar文件几乎是没有压缩过的,MT的.tar.gz文件解压成.tar文件后差不多是10MB;
tar jcvf /var/bak/www.tar.bz2 /var/www/:创建.tar.bz2文件,压缩率高;
gzip -d ge.tar.gz:解压.tar.gz文件为.tar文件;
unzip phpbb.zip:解压zip文件,windows下要压缩出一个.tar.gz格式的文件还是有点麻烦的;
find命令##
列出当前目录的文件树:
find . -print 2 > /dev/null | awk '!/\.$/ {for (i=1;iwho命令##
查看用户所在哪些终端:who | awk '{print $1 "\t" $6}'

查看硬件配置##
uname -a:查看内核/操作系统/CPU信息
head -n 1 /etc/issue:查看操作系统版本
cat /proc/cpuinfo:查看CPU信息
hostname:查看计算机名
lspci -tv:列出所有PCI设备
lsusb -tv:列出所有USB设备
lsmod:列出加载的内核模块
**env **:查看环境变量资源free -m:查看内存使用量和交换区使用量
df -h:查看各分区使用情况
du -sh <目录名>:查看指定目录的大小
grep MemTotal /proc/meminfo:查看内存总量
grep MemFree /proc/meminfo:查看空闲内存量
uptime:查看系统运行时间、用户数、负载
cat /proc/loadavg:查看系统负载磁盘和分区mount | column -t:查看挂接的分区状态
fdisk -l:查看所有分区
swapon -s:查看所有交换分区
hdparm -i /dev/hda:查看磁盘参数(仅适用于IDE设备)
dmesg | grep IDE:查看启动时IDE设备检测状况网络ifconfig:查看所有网络接口的属性
iptables -L:查看防火墙设置
**route -n **:查看路由表
netstat -lntp:查看所有监听端口
netstat -antp:查看所有已经建立的连接
**netstat -s **:查看网络统计信息进程ps -ef:查看所有进程
top:实时显示进程状态用户
w:查看活动用户
id <用户名>:查看指定用户信息
last:查看用户登录日志
cut -d: -f1 /etc/passwd:查看系统所有用户
cut -d: -f1 /etc/group:查看系统所有组
crontab -l:查看当前用户的计划任务服务
chkconfig --list:列出所有系统服务
chkconfig --list | grep on:列出所有启动的系统服务程序rpm -qa:查看所有安装的软件包
重启命令##
shutdown###
shutdown命令安全地将系统关机。有些用户会使用直接断掉电源的方式来关闭linux,这是十分危险的。因为linux与windows不同,其后台运行着许多进程,所以强制关机可能会导致进程的数据丢失﹐使系统处于不稳定的状态﹐甚至在有的系统中会损坏硬件设备。
而在系统关机前使用shutdown命令﹐系统管理员会通知所有登录的用户系统将要关闭。并且login指令会被冻结﹐即新的用户不能再登录。直接关机或者延迟一定的时间才关机都是可能的﹐还可能重启。这是由所有进程〔process〕都会收到系统所送达的信号〔signal〕决定的。这让像vi之类的程序有时间储存目前正在编辑的文档﹐而像处理邮件〔mail〕和新闻〔news〕的程序则可以正常地离开等等。
shutdown执行的工作是送信号〔signal〕给init程序﹐要求它改变runlevel。Runlevel 0被用来停机〔halt〕﹐runlevel 6是用来重新激活〔reboot〕系统﹐而runlevel 1则是被用来让系统进入管理工作可以进行的状态﹔这是预设的﹐假定没有-h也没有-r参数给shutdown。要想了解在停机〔halt〕或者重新开机〔reboot〕过程中做了哪些动作﹐你可以在这个文件/etc/inittab里看到这些runlevels相关的资料。
shutdown 参数说明:
[-t] 在改变到其它runlevel之前﹐告诉init多久以后关机。
[-r] 重启计算器。
[-k] 并不真正关机﹐只是送警告信号给每位登录者〔login〕。
[-h] 关机后关闭电源〔halt〕。
[-n] 不用init﹐而是自己来关机。不鼓励使用这个选项﹐而且该选项所产生的后果往往不总是你所预期得到的。
[-c] cancel current process取消目前正在执行的关机程序。所以这个选项当然没有时间参数﹐但是可以输入一个用来解释的讯息﹐而这信息将会送到每位使用者。
[-f] 在重启计算器〔reboot〕时忽略fsck。
[-F] 在重启计算器〔reboot〕时强迫fsck。
[-time] 设定关机〔shutdown〕前的时间。
命令:shutdown -r -t 0:0就是立即关机,如果设置为7,则是7秒钟之后关机。
halt###
halt就是调用shutdown -h。halt执行时﹐杀死应用进程﹐执行sync系统调用﹐文件系统写操作完成后就会停止内核。
halt 参数说明:
[-n] 防止sync系统调用﹐它用在用fsck修补根分区之后﹐以阻止内核用老版本的超级块〔superblock〕覆盖修补过的超级块。
[-w] 并不是真正的重启或关机﹐只是写wtmp〔/var/log/wtmp〕纪录。
[-d] 不写wtmp纪录〔已包含在选项[-n]中〕。
[-f] 没有调用shutdown而强制关机或重启。
[-i] 关机〔或重启〕前﹐关掉所有的网络接口。
[-p] 该选项为缺省选项。就是关机时调用poweroff。
reboot###
reboot的工作过程差不多跟halt一样﹐不过它是引发主机重启﹐而halt是关机。它的参数与halt相差不多。
init###
init是所有进程的祖先﹐它的进程号始终为1﹐所以发送TERM信号给init会终止所有的用户进程﹑守护进程等。shutdown 就是使用这种机制。
init定义了8个运行级别(runlevel), init 0为关机﹐init 1为重启。关于init可以长篇大论﹐这里就不再叙述。另外还有 telinit命令可以改变init的运行级别﹐比如﹐telinit -i S可使系统进入单用户模式﹐并且得不到使用shutdown时的信息和等待时间。
apt-get使用##
“起初GNU/Linux系统中只有.tar.gz。用户必须自己编译他们想使用的每一个程序。在Debian出现之後,人们认为有必要在系统中添加一种机制用来管理安装在计算机上的软件包。人们将这套系统称为dpkg。至此着名的‘package’首次在GNU/Linux上出现。不久之後红帽子也开始着手建立自己的包管理系统‘rpm’。
“GNU/Linux的创造者们很快又陷入了新的窘境。他们希望通过一种快捷、实用而且高效的方式来安装软件包。这些软件包可以自动处理相互之间的依赖关系,并且在升级过程中维护他们的配置文件。Debian又一次充当了开路先锋的角色。她首创了APT(Advanced Packaging Tool)。这一工具後来被Conectiva 移植到红帽子系统中用于对rpm包的管理。在其他一些发行版中我们也能看到她的身影。”
"同时,apt是一个很完整和先进的软件包管理程序,使用它可以让你,又简单,又准确的找到你要的的软件包, 并且安装或卸载都很简洁。 它还可以让你的所有软件都更新到最新状态,而且也可以用来对ubuntu进行升级。"
"apt是需要用命令来操作的软件,不过现在也出现了很多有图形的软件,比如Synaptic, Kynaptic 和 Adept。"
apt-get update——在修改/etc/apt/sources.list或者/etc/apt/preferences之後运行该命令。此外您需要定期运行这一命令以确保您的软件包列表是最新的。
apt-get install packagename——安装一个新软件包(参见下文的aptitude)。
apt-get remove packagename——卸载一个已安装的软件包(保留配置文件)。
apt-get --purge remove packagename——卸载一个已安装的软件包(删除配置文件)。
dpkg --force-all --purge packagename——有些软件很难卸载,而且还阻止了别的软件的应用,就可以用这个,不过有点冒险。
apt-get autoclean——apt会把已装或已卸的软件都备份在硬盘上,所以如果需要空间的话,可以让这个命令来删除你已经删掉的软件。
apt-get clean——这个命令会把安装的软件的备份也删除,不过这样不会影响软件的使用的。
apt-get upgrade——更新所有已安装的软件包。
apt-get dist-upgrade——将系统升级到新版本。
apt-cache search string——在软件包列表中搜索字符串。
dpkg -l package-name-pattern——列出所有与模式相匹配的软件包。如果您不知道软件包的全名,您可以使用“package-name-pattern”。
aptitude——详细查看已安装或可用的软件包。与apt-get类似,aptitude可以通过命令行方式调用,但仅限于某些命令——最常见的有安装和卸载命令。由于aptitude比apt-get了解更多信息,可以说它更适合用来进行安装和卸载。
apt-cache showpkg pkgs——显示软件包信息。
apt-cache dumpavail——打印可用软件包列表。
apt-cache show pkgs——显示软件包记录,类似于dpkg –print-avail。
apt-cache pkgnames——打印软件包列表中所有软件包的名称。
dpkg -S file——这个文件属于哪个已安装软件包。
dpkg -L package——列出软件包中的所有文件。
apt-file search filename——查找包含特定文件的软件包(不一定是已安装的),这些文件的文件名中含有指定的字符串。apt-file是一个独立的软件包。您必须先使用apt-get install来安装它,然後运行apt-file update。如果apt-file search filename输出的内容太多,您可以尝试使用apt-file search filename | grep -w filename(只显示指定字符串作为完整的单词出现在其中的那些文件名)或者类似方法,例如:apt-file search filename | grep /bin/(只显示位于诸如/bin或/usr/bin这些文件夹中的文件,如果您要查找的是某个特定的执行文件的话,这样做是有帮助的)。
apt-get autoclean——定期运行这个命令来清除那些已经卸载的软件包的.deb文件。通过这种方式,您可以释放大量的磁盘空间。如果您的需求十分迫切,可以使用apt-get clean以释放更多空间。这个命令会将已安装软件包裹的.deb文件一并删除。大多数情况下您不会再用到这些.debs文件,因此如果您为磁盘空间不足而感到焦头烂额,这个办法也许值得一试。
wget下载##
wget是在Linux下开发的开放源代码的软件,作者是Hrvoje Niksic,后来被移植到包括Windows在内的各个平台上。它有以下功能和特点:
(1)支持断点下传功能;这一点,也是网络蚂蚁和FlashGet当年最大的卖点,现在,Wget也可以使用此功能,那些网络不是太好的用户可以放心了;
(2)同时支持FTP和HTTP下载方式;尽管现在大部分软件可以使用HTTP方式下载,但是,有些时候,仍然需要使用FTP方式下载软件;
(3)支持代理服务器;对安全强度很高的系统而言,一般不会将自己的系统直接暴露在互联网上,所以,支持代理是下载软件必须有的功能;
(4)设置方便简单;可能,习惯图形界面的用户已经不是太习惯命令行了,但是,命令行在设置上其实有更多的优点,最少,鼠标可以少点很多次,也不要担心是否错点鼠标;
(5)程序小,完全免费;程序小可以考虑不计,因为现在的硬盘实在太大了;完全免费就不得不考虑了,即使网络上有很多所谓的免费软件,但是,这些软件的广告却不是我们喜欢的;
wget http://soft.deepvps/web/nginx/nginx-0.8.0.tar.gz:下载远程服务器上的文件到自己的服务器,连上传都省了,服务器不是100M就是1000M的带宽,下载一个2-3兆的MT还不是几十秒的事;
wget -c http://soft.deepvps/web/nginx/nginx-0.8.0.tar.gz:继续下载上次未下载完的文件;
wget参数说明:
-t,--tries=NUMBER 是否下载次数(0表示无穷次)
-O --output-document=FILE保存下载日志到文件FILE
-nc, --no-clobber 不要覆盖已经存在的文件
-N,--timestamping只下载比本地新的文件
-T,--timeout=SECONDS 设置超时时间
-Y,--proxy=on/off 关闭代理
例:下载的首页并将下载过程中的的输入信息保存到test.htm文件中:wget -O test.html
1)下载整个http或者ftp站点:wget http://place.your.url/here
这个命令可以将http://place.your.url/here 首页下载下来。使用-x会强制建立服务器上一模一样的目录,如果使用-nd参数,那么服务器上下载的所有内容都会加到本地当前目录。
2)递归下载 :wget -r http://place.your.url/here
这 个命令会按照递归的方法,下载服务器上所有的目录和文件,实质就是下载整个网站。这个命令一定要小心使用,因为在下载的时候,被下载网站指向的所有地址同 样会被下载,因此,如果这个网站引用了其他网站,那么被引用的网站也会被下载下来!基于这个原因,这个参数不常用。可以用-l number参数来指定下载的层次。例如只下载两层,那么使用-l 2。
3)制作镜像站点,那么可以使用-m参数,例如:wget -m http://place.your.url/here
这时wget会自动判断合适的参数来制作镜像站点。此时,wget会登录到服务器上,读入robots.txt并按robots.txt的规定来执行。
4)断点续传,例如:wget -c http://the.url.of/incomplete/file
当文件特别大或者网络特别慢的时候,往往一个文件还没有下载完,连接就已经被切断,此时就需要断点续传。wget的断点续传是自动的,只需要使用-c参数,使用断点续传要求服务器支持断点续传。-t参数表示重试次数,例如需要重试100次,那么就写-t 100,如果设成-t 0,那么表示无穷次重试,直到连接成功。-T参数表示超时等待时间,例如-T 120,表示等待120秒连接不上就算超时。
**5)批量下载,例如:wget -i download.txt **
如果有多个文件需要下载,那么可以生成一个文件,把每个文件的URL写一行,例如生成文件download.txt,然后用命令:wget -i download.txt 这样就会把download.txt里面列出的每个URL都下载下来。(如果列的是文件就下载文件,如果列的是网站,那么下载首页)
6)选择性的下载,例如:wget -m –reject=gif http://target.web.site/subdirectory
可以指定让wget只下载一类文件,或者不下载什么文件。例如:wget -m –reject=gif http://target.web.site/subdirectory 表示下载http://target.web.site/subdirectory, 但是忽略gif文件。–accept=LIST 可以接受的文件类型,–reject=LIST拒绝接受的文件类型。
7)密码和认证
wget只能处理利用用户名/密码方式限制访问的网站,可以利用两个参数:
–http-user=USER设置HTTP用户
–http-passwd=PASS设置HTTP密码
对于需要证书做认证的网站,就只能利用其他下载工具了,例如curl。
8)利用代理服务器进行下载
如果用户的网络需要经过代理服务器,那么可以让wget通过代理服务器进行文件的下载。此时需要在当前用户的目录下创建一个.wgetrc文件。文件中可以设置代理服务器:
http-proxy = 111.111.111.111:8080
ftp-proxy = 111.111.111.111:8080
分别表示http的代理服务器和ftp的代理服务器。如果代理服务器需要密码则使用:
–proxy-user=USER设置代理用户
–proxy-passwd=PASS设置代理密码
这两个参数。
使用参数–proxy=on/off 使用或者关闭代理。
附录:命令格式:
wget [参数列表] [目标软件、网页的网址]
-V,–version 显示软件版本号然后退出;
-h,–help显示软件帮助信息;
-e,–execute=COMMAND 执行一个 “.wgetrc”命令-o,–output-file=FILE 将软件输出信息保存到文件;
-a,–append-output=FILE将软件输出信息追加到文件;
-d,–debug显示输出信息;
-q,–quiet 不显示输出信息;
-i,–input-file=FILE 从文件中取得URL;-t,–tries=NUMBER 是否下载次数(0表示无穷次)
-O –output-document=FILE下载文件保存为别的文件名
-nc, –no-clobber 不要覆盖已经存在的文件
-N,–timestamping只下载比本地新的文件
-T,–timeout=SECONDS 设置超时时间
-Y,–proxy=on/off 关闭代理-nd,–no-directories 不建立目录
-x,–force-directories 强制建立目录-http-user=USER设置HTTP用户
-http-passwd=PASS设置HTTP密码
-proxy-user=USER设置代理用户
-proxy-passwd=PASS设置代理密码-r,–recursive 下载整个网站、目录(小心使用)
-l,–level=NUMBER 下载层次-A,–accept=LIST 可以接受的文件类型
-R,–reject=LIST拒绝接受的文件类型
-D,–domains=LIST可以接受的域名
-exclude-domains=LIST拒绝的域名
-L,–relative 下载关联链接
-follow-ftp 只下载FTP链接
-H,–span-hosts 可以下载外面的主机
-I,–include-directories=LIST允许的目录
-X,–exclude-directories=LIST 拒绝的目录
lsof使用##
lsof filename 显示打开指定 文件的所有进程
lsof -a 表示两个参数都必须满足时才显示结果
lsof -c string 显示COMMAND列中包含指定字符的进程所有打开的文件
lsof -u username 显示所属user进程打开的文件
lsof -g gid 显示归属gid的进程情况
lsof +d /DIR/ 显示目录下被进程打开的文件
lsof +D /DIR/ 同上,但是会搜索目录下的所有目录,时间相对较长
lsof -d FD 显示指定文件描述符的进程
lsof -n 不将IP转换为hostname,缺省是不加上-n参数
lsof -i 用以显示符合条件的进程情况
lsof -i[46] [protocol][@hostname|hostaddr][:service|port]
查看22端口现在运行的情况:lsof -i :22

查看所属root用户进程所打开的文件类型为txt的文件:lsof -a -u root -d txt
