论文地址:
Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks
Python实现:
https://github.com/rbgirshick/py-faster-rcnn
简介
Fast R-CNN算法采用 SppNet 的思想解决了R-CNN中图像warp操作,并且避免了特征的重复计算(参见 ROI Pooling的相关理解及Fast R-CNN与R-CNN的简单对比),使区域 + 分类/回归的检测框架有了实时的可能。但是 region proposal 的生成仍是算法的一个速度瓶颈。
为了解决这一问题,作者提出了 Region Proposal Network(RPN),RPN 网络共享输入图像的卷积特征,能够快速生成候选区域,计算代价小。生成的候选区送入Fast R-CNN网络进行 detection。因此 Faster R-CNN 也可以理解为 RPN + Fast R-CNN(文中作者称 RPN 具有 attention 的意味,即告诉网络关注的区域在哪里)。
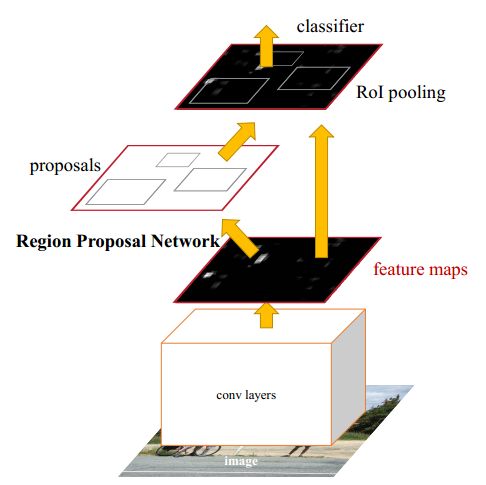
RPN网络
RPN 网络的作用是输入一张图像,输出一批候选矩形区域(region proposal),同时输出的还有区域得分。RPN为全卷积网络,以 ZF 网络或 VGG 网络为 base 网络,下图是以 ZF-5 为参考的RPN网络结构(图片是用Netscope在线生成的http://ethereon.github.io/netscope/#/editor)
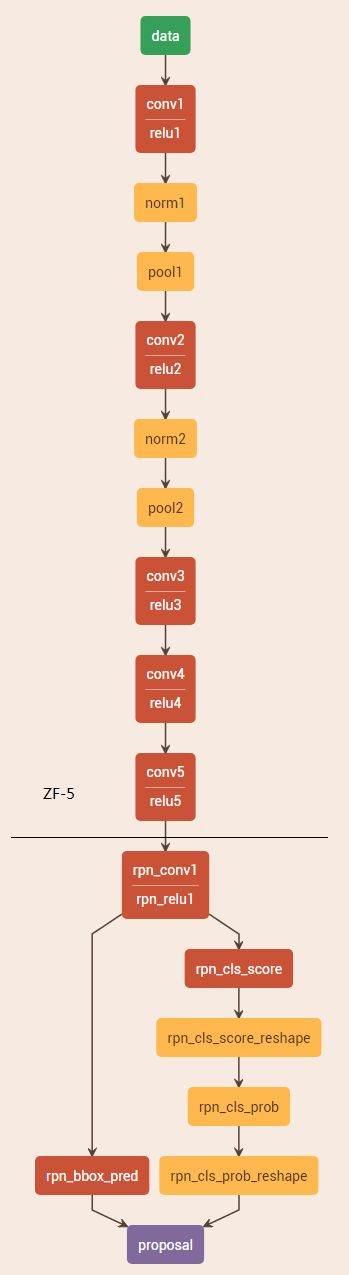
黑线以上是 ZF-5 网络的卷积过程,黑线以下是 RPN 网络的特有结构。对于 ZF-5 卷积得到的 feature map,采用n*n大小的 sliding window 进行滑动处理(即filter大小为n*n的卷积,文中 n=3),然后通过1*1卷积输出两路,分别用于分类和回归。
如图是 sliding window 的处理过程:
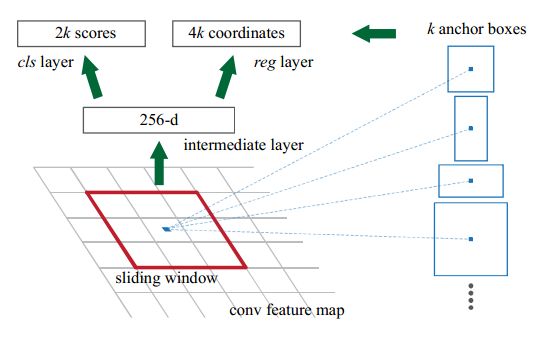
图中的一些解释
- 256-d:ZF-5 的最后一层输出 filter 的个数是256,因此每一个滑动窗输出是一个256维的向量。
- 2k 和 4k:首先解释一下k,在每一个滑动窗口的中心位置,预测k个候选区,这些候选区被称为 anchor(后文会解释)。2k是因为分类层的输出为目标为 foreground 和 background 的概率,4k则是每个 anchor box 包含4 个位置坐标。
Anchor 的解释
Anchor 是 RPN 网络的核心,后续的一些目标检测网络如 YOLOv2、SSD、YOLOv3 也借鉴了这一机制。
在 ZF-5 输出的 feature map 上进行滑窗操作,是为了获取滑窗对应的感受野内是否存在目标(概率,以及目标的位置坐标),由于目标大小和长宽比例可能不一,因此需要多个窗口。Anchor 的机制是,以滑动窗的中心为采样点,采用不同的 scale 和 ratio,生成不同大小共 k 个 anchor 窗口。对于一个W*H大小的 feature map 来说,生成的 anchor 总数为W*H*k。例如 scale 为(128,256,512),ratio 为(1:2,1:1,2:1)时,则生成 9 种 anchor。
注:目标识别任务应具有平移不变性和尺度不变性,传统的做法是采用 image pyramid 或 filter pyramid,anchor 的机制满足这样的要求,且相比较两种做法更加的 cost-efficient
采用 Anchor 机制能够从整图的 feature map 上直接提取候选区域(映射到原图)及其特征,相比较 R-CNN 和 Fast R-CNN 中 selective search(或EdgeBoxes) 的方法,避免了大量的额外运算,且整个过程融合到一个网络中,方便训练和测试
训练
RPN 网络的 loss 函数同样是一个多任务的loss,包含两个部分,classification 的 loss 和 regression 的 loss。
首先,对于 classification来说,论文中将满足以下两种规则的 anchor 判定为 positive:1)anchor 与任一目标的 ground truth box 的IoU值最大;2)anchor 与任一目标的 ground truth box 的IoU值 > 0.7。因此,存在一个 ground truth 对应多个 anchor 的情况。当 IoU 值 < 0.3 时,则认为 anchor 为 non-positive,即背景。除此之外,其他的 anchor 不参与训练。
如此,loss 函数定义为(可恶的不支持公式编辑。。。)
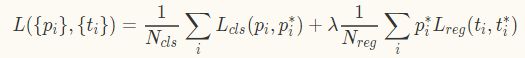
式中,i 是一个 mini-batch 下 anchor 的索引。p_i是 anchor 为目标的概率。当anchor为目标时,p^*_i 为1,否则为0。t_i是预测框的位置坐标,t^*_i是ground truth的坐标。
L_{cls}是目标与非目标的对数损失,即
L_{reg}则采用 Fast R-CNN 中的平滑 L1 loss,不采用 R-CNN 和 SPP 中平滑 L2 loss 的原因是,在防止梯度爆炸问题上,L1 loss 敏感性较低,学习率更容易调节。L1 loss 的形式为
其中,
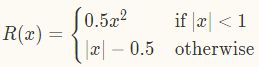
p^*_iL_{reg}表示 regression loss 只在 anchor 为 positive 时有效。
L_{cls}和L_{reg}分别由N_{cls}、N_{reg}进行归一化,同时乘上系数\lambda。论文作者发布的代码中,N_{cls}为mini-batch的大小(如N_{cls} = 256),N_{reg}为anchor的数量(如N_{cls} ~ 2400)。另外,设置\lambda为10,则 cls 项和 reg 项的权重大体一致(事实上 \lambda 的影响不大,如下表所示)。
| λ | 0.1 | 1 | 10 | 100 |
|---|---|---|---|---|
| mAP(%) | 67.2 | 68.9 | 69.9 | 69.1 |
在计算 bbox 的 regression 时,采用以下计算方法
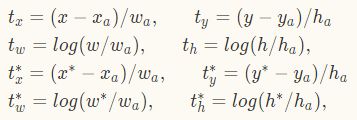
式中,x,y,w,h表示框的中心坐标及宽高。x,x_a,x^*分别表示预测框,anchor 框和 ground truth 框(y,w,h同理)。
RPN 通过 Back Propagation 和 SGD 的方法进行端到端的训练。参照Fast R-CNN 中 “image - centric” 的采样策略。每个 mini-batch 由包含很多图像的单张图像组成,如果采用所有的 anchors 优化 loss 函数,可能会向负样本倾斜,因为它们比重较大。因而,论文中采取随机从一张图像中采样 256 个 anchors 的做法来训练一个 mini-batch,256个 anchors 中正负样本的比重是1:1。如果正样本数少于128,则用负样本填充。
新增层的参数用均值为0,标准差为0.01的高斯分布来进行初始化,其余层(都是共享的卷积层,与VGG共有的层)参数用 ImageNet 分类预训练模型来初始化。前60k个mini-batch进行迭代,学习率设为0.001;后20k个mini-batch进行迭代,学习率设为 0.0001;设置动量momentum = 0.9,权重衰减 weightdecay = 0.0005。实现方式为Caffe。
RPN 和 Fast R-CNN特征共享
以上描述了如何训练 RPN 网络,而没有考虑基于 region proposal 的目标检测网络如何利用这些 proposals。对于检测网络,作者采用了 Fast R-CNN。RPN 和 Fast R-CNN 如果都独立训练,需要单独修改它们的卷积层。因此有需要开发一种允许两个网络间共享卷积层的技术,而不是分别学习两个网络。论文中作者描述了 3 种方法用来实现特征共享:
- 交替训练。 首先训练 RPN,用 RPN 输出的 proposals 训练 Fast R-CNN。Fast R-CNN 精调后用于初始化 RPN 网络参数,如此循环迭代。开源的 matlab 版本就是这种训练方法。
- 近似联合训练。 RPN 和 Fast R-CNN 整合到一个网络里一起训练。但是该方法忽略了 wrt 导数,开源的 python 版本就是这么训练的,可以减少 25-50% 的训练时间。为什么呢?因为 caffe 中所有层都是 c++ 实现的,所以 python_layer 就没有进行 back_ward,当然训练的时候必须显式指定loss_weight:1。
- 联合训练。 超出论文范畴,作者未实现。
基于交替训练法,作者描述了一种4-step的训练方式:
step 1. 训练 RPN 网络,采用 ImageNet 预训练的模型进行初始化,并进行微调
step 2. 利用 step1 的RPN生成 proposal,由 Fast R-CNN 训练一个单独的检测网络,该网络同样由ImageNet预训练模型进行初始化。此时,两个网络还未共享卷积层
step 3. 用检测网络初始化 RPN 训练,固定共享的卷积层,只微调 RPN 独有的层,现在两个网络实现了卷积层共享
step 4. 保持共享的卷积层固定,微调 Fast R-CNN 的 fc 层。这样,两个网络共享相同的卷积层,构成一个统一的网络
实现细节
训练时(eg:600*1000的图像),如果 anchor box 的边界超过了图像边界,我们将其舍弃不用,因为这样的 anchor 会导致训练无法收敛。一幅 600*1000 的图像经过 VGG16 后大约为 40*60,则此时的 anchor 数为 40*60*9,约为 20k 个 anchor boxes,再去除与边界相交的 anchor boxes 后,剩下约为 6k 个,这么多数量的anchor boxes之间肯定是有很多重叠区域,因此需要使用非极大值抑制法(NMS,non-maximum suppression)将 IoU>0.7 的区域全部合并,最后就剩下约 2k 个 anchor boxes(同理,在最终检测端,可以设置将概率大约某阈值P且IoU大约某阈值T的预测框采用 NMS 方法进行合并,注意:这里的预测框指的不是 anchor boxes)。NMS不会影响最终的检测准确率,但是大幅地减少了建议框的数量。NMS之后,我们用建议区域中的top-N个来检测。
实验结果
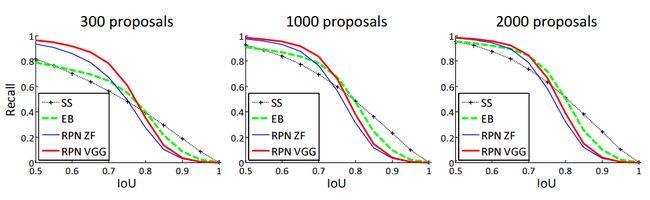
- 与Selective Search方法(黑线SS)相比,当每张图生成的proposal从2000减少到300时,RPN方法(红蓝)的召回率下降不大。说明RPN方法的目的性更明确(attention机制~~)。
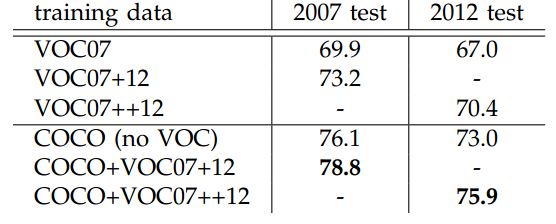
- 使用更大的MS COCO库训练,直接在PASCAL VOC上测试,准确率提升6%。说明faster RCNN迁移性良好,没有over fitting。
结语
此时可以放出 R-CNN、Fast R-CNN、Faster R-CNN的对比了。如下所示(此处表格参考https://blog.csdn.net/qq_17448289/article/details/52871461)
| 名称 | 方法 | 缺点 | 优点 |
|---|---|---|---|
| R-CNN | 1、SS提取RP; 2、CNN提取特征; 3、SVM分类; 4、BBox回归。 |
1、 训练步骤繁琐(微调网络+训练SVM+训练bbox); 2、 训练、测试均速度慢 ; 3、 训练占空间 |
1、 从DPM HSC的34.3%直接提升到了66%(mAP); 2、 引入RP+CNN |
| Fast R-CNN | 1、SS提取RP; 2、CNN提取特征; 3、softmax分类; 4、多任务损失函数边框回归。 |
1、 依旧用SS提取RP(耗时2-3s,特征提取耗时0.32s); 2、 无法满足实时应用,没有真正实现端到端训练测试; 3、 利用了GPU,但是区域建议方法是在CPU上实现的。 |
1、 由66.9%提升到70%; 2、 每张图像耗时约为3s。 |
| Faster R-CNN | 1、RPN提取RP; 2、CNN提取特征; 3、softmax分类; 4、多任务损失函数边框回归。 |
1、 还是无法达到实时检测目标; 2、 获取region proposal,再对每个proposal分类计算量还是比较大。 |
1、 提高了检测精度和速度; 2、 真正实现端到端的目标检测框架; 3、 生成建议框仅需约10ms。 |
Faster R-CNN 将 two-stage 的检测框架在实时的进程中推进了一大步,但是仍有提升的空间。由Microsoft Research的Jifeng Dai等人提出的R-FCN网络即是一个例子。