在看了几篇论文和一些文章之后,今天来做一个小小的总结。这篇文章主要分为三部分。第一部分是简单讲述Task oriented dialogue systems;第二部分是较概括的讲述现在各end to end task oriented dialogue systems的模型;第三是总结和讨论。
简述Task oriented dialogue systems:
Task Oriented Dialog Systems(领域任务型的对话系统)是针对具体的应用领域,比如餐厅预订、公交线路查询、设备控制等,以完成一项具体的领域任务为目标,代表有自动客服,领域推荐等等。
对于一个传统领域任务型(task oriented) 的对话系统[1],可以分为以下三个部分,也就是SLU,NLG,Dialogue Manager。口语理解模块(SLU)将语言转换成抽象语义表示,即用户对话行为,而后系统更新其内部状态,然后系统通过决策规则确定系统行为,最后语言生成模块(NLG)将系统行为决策转化成对话。其中,状态变量包含跟踪对话过程的变量,以及表示用户需求的属性值(又称为slots)。
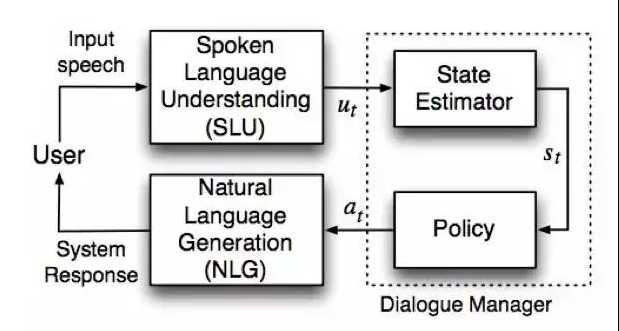
在分模块系统中,每个部分都有不同的方法和模型来解决。举个栗子,比如:SLU系统由从自然语言询问中识别说话者的意图和提取语义构成,这两项任务常被称为意图识别和槽位填充。意图识别和槽位填充通常是分别进行的。意图推测可以理解为语义表达分类的问题,比较流行的分类方法有例如支持向量机(SVMs)和深度神经网络。槽位填充可以理解为序列标注任务。解决序列标注问题流行的方法包括最大熵马尔可夫模型(MEMMs),条件随机场(CRFs)以及循环神经网络(RNNs)等等。由于在此主要是讲end to end 的模型,所以不详细说明各个部分分开模型的解决方式。
在任务型的对话系统中,分模块的解决方式有不错的效果,但是,这样的方式需要分开来训练各个模块,同时需要大量的特定领域的人工干预(domain-specific handcrafting),在模型泛化方面有很大的局限,在进行任务对话的时候,缺乏鲁棒性。同时随着技术的发展,如何构建个性化,更加吸引用户的对话系统也是一个较大的问题。而随着深度学习的发展,end to end 模型在很多方面有所成就,如机器翻译,文本挖掘和图像识别等。但在Task Oriented Dialog Systems(领域任务型的对话系统)方面,还有很大的提升空间。下面介绍最近end to end 模型的一些工作和我的看法,当然,如有偏颇,望指出!
这篇就先总结这5篇paper,若下来有其他新的再看,有必要总结话,那么就下次再总结吧!
end to end task oriented dialogue systems模型:
Learning End-to-End Goal-Oriented Dialog[2]
基于Memory Network在QA chatbot领域充分展示了优势,而Paper Learning End-to-End Goal-Oriented Dialog则将其应用在了领域任务型的对话系统(Task Oriented Dialog System)中。模型还是原来的模型,只是用法不同而已!
模型如下图,和一开始的Memory Network没有什么不同的地方,但是有一点需要指出的是在End-to-End Memory Network这篇文中的output是一个词。也就是说在QA那边,回答只是一个词而已。但在生成对话的时候,一个词肯定是解决不了问题的。然而模型还是那个模型呀,怎么办呢?这个时候作者在paper中提出的是不是不用一句话一句话机器生成式的,而是恰好相反,作者在这里用的是先指定回答模板,然后基于模板生成的,模型在输出时输出一个得分,再从模板中取得分最高的那一个。这样虽然解决了生成一句话的问题,但是另外一个问题也就是领域迁移性差的问题也就随之产生。

Memory Network其实验数据为以餐馆预订为目的的bAbI数据集,已有开源的数据和代码
总结一下其优缺点:应用Memory Network的优势在于不用独立涉及 SLU,DST,也就是直接的端到端的一种训练,在其缺点在于很难结合知识库。同时在该论文中的实验是基于模板检索的各种模板还是需要自己制定,也就是存在迁移差的问题。
LSTM-based dialog[3]&Hybrid Code Networks[4]
这两篇论文有很多相似的地方,首先在motivation上,可以说都是客服成长过程,这个在[3]开头有描述,在训练的时候可以看作是专家在训练一个新入职的客服,由专家提供一系列example dialogues,和一些标准答案,然后让模型去学习。学成之后上线服务,在服务的同时有结合反馈来继续学习。然后是在模型方面,从图中就可以看出相似之处,整体流程方面大概是首先输入会话,然后提取entity ,加上原来对话,转成向量,输入给RNN,用rnn来做DM结合一些领域知识,一些action mask和templates,输出决策,再基于模板生成对话,这样一直循环。最后是在训练方法上面,都提出了SL和RL都可以独立训练或者结合来训练的方式。
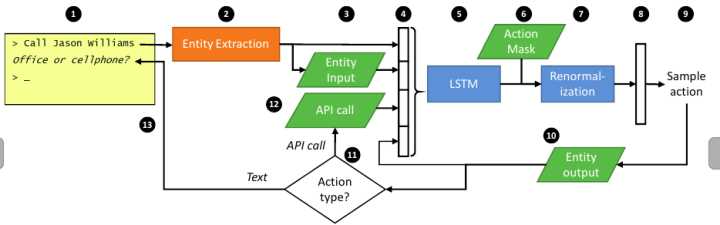
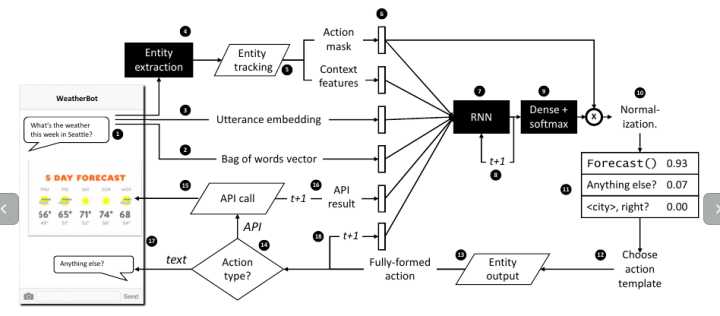
在网上找到Hybrid Code Networks模型的实验代码--代码和数据,实验数据还是以餐馆预订为目的的bAbI数据集,可以和上面的Memory Network base 模型做下对比实验。
总结其优缺点:可以同时用SL和RL的训练方式训练,领域专家需要提供少量对话样本,就可以自动学习对话状态( dialogue states)。但是缺点是很多模块还是需要较多的人为的干预,比如需要人为干预的SLU, DST, Database模块,制定动作掩码(action mask),等等。
A network Based end To End trainable task Oriented dialogue system[5]
这篇论文是剑桥大学Dialogue System Group在16年5月发表的,如下图,首先其模型中Intent Network可以理解为seq2seq的encoder部分,将用户的输入encode成一个vector z(t)。然后在Belief Trackers,这个也就是Dialogue State Tracking(DST),这里是输入原对话输出一个informable slot和requestable slot的概率分布,作用就是原来的作用,获取到预先定好的知识图谱中每个slot的分布,跟踪对话的状态。而后在Policy Network结合前面两者加上从 数据库查询的相应”知识“,形成决策,输出给Generation Network进行文本生成。
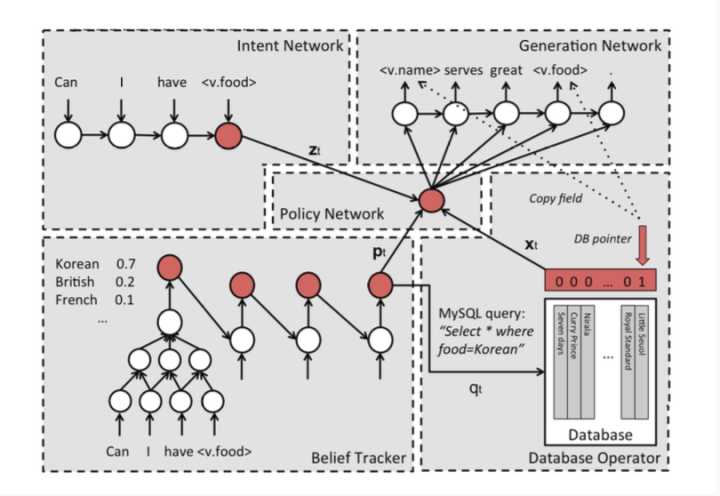
这篇目前并没有找到其代码,只是有论文作者的主页是找到其数据集...
总结其优缺点:这篇论文在system中能较好的结合知识库,在项目只需要较少的人为干预即可,在其缺点在于我们需要在DST预定好领域先验知识中的slot value,而且在训练中在于DST是需要独立的训练。
End To End task Completion neural dialogue systems[6]
这篇文章中结合之前一篇paper[7]提出的User Simulator来模用户议程,来进行训练,可以说形成一个较为完善的训练系统。在User Simulator输出query给语意理解模块(LU)作为输入,语意理解模块(LU)是一个LSTM实现的,然后输出语义帧,用流行的IOB(in-out-begin)格式用于表示槽标签。在DM决策之后输出policy输出结果。
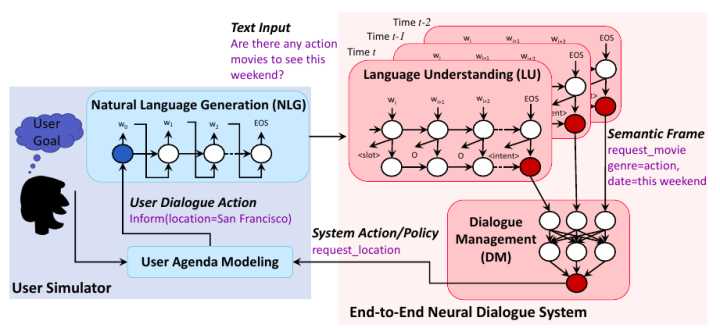
这篇paper开源了其代码和数据,是纯python无框架写的!
总结其优缺点:其优点很明显就是在训练的时候是端到端的,同时User Simulator在一定程度上解决了end to end Task oriented dialogue systems训练数据难获得的问题。然后其劣势和挑战在于首先数据集不大,在训练的时候也较依赖于其特定的数据集!
总结与讨论:
提出我的几个想法,首先是在end to end 模型中,其实就是在想怎么把之前做的分模块要分开训练的多个模型有机的结合统一成一个新的模型,比较常见的是比如DM用RNN来做,更好的跟踪状态,用基于模板或者基于生成式或者两者结合的方式来生成对话等。
在训练方式方面,RL算法在上面的论文用普遍都有用,也得到了非常不错的效果,这个是个很不错的方式,也是可以继续提出创新点的地方。
最后在task oriented dialogue systems方面end to end的数据缺乏,在[7]提出的User Simulator 是一个比较不错的方式来模拟用户训练,当然在发展end to end Task oriented dialogue systems中,数据集还是个很大的问题 。
在接下来的工作,我想第一是应该是怎么才能用更少的领域先验知识来构建模型,另一个也应该是怎么才能提高其领域迁移性的问题。
参考文献:
[1]:李林琳&赵世奇.对话系统任务综述与基于POMDP的对话系统. PaperWeekly.
[2]:Antoine Bordes and Jason Weston. Learning end-to-end goal-oriented dialog. arXiv preprint arXiv:1605.07683, 2016.
[3]:Jason D Williams and Geoffrey Zweig. End-to-end lstm-based dialog control optimized with supervised and reinforcement learning. arXiv preprint arXiv:1606.01269, 2016.
[4]:Williams J D, Asadi K, Zweig G. Hybrid Code Networks: practical and efficient end-to-en dialog control with supervised and reinforcement learning[J]. arXiv preprint arXiv:1702.03274, 2017.
[5]:Wen T H, Vandyke D, Mrksic N, et al. A network-based end-to-end trainable task-oriented dialogue system[J]. arXiv preprint arXiv:1604.04562, 2016.
[6]:Li, Xuijun, et al. "End-to-end task-completion neural dialogue systems."arXiv preprint arXiv:1703.01008(2017).
[7]:Li, Xiujun, et al. "A user simulator for task-completion dialogues."arXiv preprint arXiv:1612.05688(2016)
原文参考:https://zhuanlan.zhihu.com/p/27762254