每天分析一个开源项目:open_deep_research
每天分析一个开源项目:open_deep_research
项目链接:langchain-ai/open_deep_research
项目介绍
项目功能:
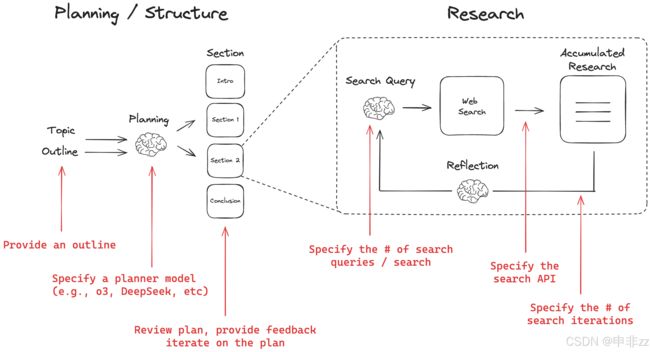
Open Deep Research 是一个基于 LangGraph 的 Web 研究助手,旨在帮助用户快速生成特定主题的综合性报告。它模拟了 OpenAI 和 Gemini 的 Deep Research 流程,但提供了更强的自定义能力,允许用户配置模型、Prompt、报告结构、搜索 API 和研究深度。核心功能包括:
- 报告规划与反馈: 根据用户提供的主题和报告结构,智能规划报告的各个章节。用户可以对报告计划进行反馈,迭代优化,直到满意为止。
- Web 搜索与信息收集: 对每个报告章节,自动生成搜索查询,利用各种 Web 搜索 API(如 Tavily、Perplexity、Exa、ArXiv、PubMed)收集相关信息。
- 内容生成与深度研究: 利用大型语言模型(如 Anthropic Claude、OpenAI 模型、Groq 模型)撰写报告的每个章节,并通过多次迭代的写作、反思、搜索、重写,深化研究的深度。
- 灵活配置与自定义: 提供丰富的配置选项,包括报告结构、搜索 API、模型选择、搜索深度等,用户可以根据需求调整研究助手的行为。
适用场景:
Open Deep Research 适用于以下场景:
- 市场分析与竞争情报: 快速生成关于特定市场或竞争对手的报告,收集关键数据和洞见。
- 科研探索与文献综述: 帮助科研人员快速了解某个研究领域的最新进展,进行文献综述。
- 技术调研与知识学习: 快速了解某项技术的原理、应用和发展趋势。
- 内容创作与报告撰写: 辅助内容创作者和专业人士撰写各种报告,例如行业报告、白皮书、研究报告等。
表现:
Open Deep Research 的优势体现在以下几个方面:
- 强大的自定义能力: 可以根据用户的具体需求进行定制,例如,可以调整模型的选择,定制报告的结构。
- 高效的研究流程: 通过规划、搜索、写作的迭代流程,确保报告内容的全面性和准确性。
- 灵活的部署方式: 支持本地部署和云端部署,方便用户使用。
- 基于 LangGraph 的可扩展性: 基于 LangGraph 构建,具有良好的可扩展性,可以方便地添加新的功能和模块。
- 兼容多种模型和搜索引擎 支持包括Anthropic, OpenAI, Groq 的模型,和Perplexity, Tavily, Exa, Arxiv, PubMed搜索引擎。
安装与使用指南
以下是在本地环境中安装和使用 Open Deep Research 的详细步骤:
1. 环境准备(推荐:创建虚拟环境):
为了隔离项目依赖,建议创建并激活一个虚拟环境。
python -m venv open_deep_research # 创建名为 open_deep_research 的虚拟环境
source open_deep_research/bin/activate # 在 Linux/macOS 上激活虚拟环境
# 或者
.\open_deep_research\Scripts\activate # 在 Windows 上激活虚拟环境
2. 安装 Open Deep Research:
使用 pip 包管理器安装 open-deep-research。
pip install open-deep-research
3. 配置 API 密钥:
Open Deep Research 需要调用各种 API(例如:Tavily, Anthropic, OpenAI等)来完成搜索和内容生成。你需要设置相应的 API 密钥。
-
复制
.env.example 文件:cp .env.example .env或者在Windows下:
copy .env.example .env -
编辑
.env 文件:打开
.env 文件,将sk-xxx 替换为你自己的 API 密钥。 例如:OPENAI_API_KEY=sk-your_openai_api_key ANTHROPIC_API_KEY=sk-your_anthropic_api_key TAVILY_API_KEY=your_tavily_api_key GROQ_API_KEY=your_groq_api_key PERPLEXITY_API_KEY=your_perplexity_api_key EXA_API_KEY=your_exa_api_key PUBMED_API_KEY=your_pubmed_api_key [email protected] -
设置环境变量 (可选):
或者,你也可以直接设置环境变量,这与编辑
.env 文件的效果相同,并且可以在不同项目之间共享API密钥。export TAVILY_API_KEY=<your_tavily_api_key> export ANTHROPIC_API_KEY=<your_anthropic_api_key> # 更多 API key...请注意,某些操作系统(如 Windows)使用不同的环境变量设置语法(
set TAVILY_API_KEY=)。
4. 使用示例 (Python 代码):
以下是一个简单的使用示例,展示了如何使用 Open Deep Research 生成报告。
from langgraph.checkpoint.memory import MemorySaver
from open_deep_research.graph import builder
import uuid
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
topic = "Overview of the AI inference market with focus on Fireworks, Together.ai, Groq"
thread = {"configurable": {"thread_id": str(uuid.uuid4()),
"search_api": "tavily",
"planner_provider": "openai",
"planner_model": "claude-3-7-sonnet-latest",
"writer_provider": "anthropic",
"writer_model": "claude-3-5-sonnet-latest",
"max_search_depth": 1,
}}
import asyncio
async def main():
async for event in graph.astream({"topic":topic,}, thread, stream_mode="updates"):
print(event)
print("\n")
if __name__ == "__main__":
asyncio.run(main())
这段代码:
- 导入必要的模块: 包括
MemorySaver (用于保存运行状态) 和builder (用于构建 LangGraph)。 - 初始化 LangGraph: 创建
MemorySaver 实例,并使用builder.compile() 编译 LangGraph。 - 定义主题: 设置要研究的主题。
- 配置线程: 通过
thread 字典配置了运行参数,包括search_api,planner_provider,planner_model,writer_provider, 和writer_model 等。 - 运行 LangGraph: 使用
graph.astream() 方法运行 LangGraph。stream_mode="updates" 表示以流式更新的方式输出结果。 - 循环输出事件: 循环遍历
graph.astream() 返回的事件,并打印到控制台。
中断和反馈:
Open Deep Research 的核心在于人机交互。当报告计划生成后,程序会中断,等待用户反馈。
- 提供反馈: 修改报告计划,例如,添加一个章节。
- 批准计划: 如果对报告计划满意,则输入
"true",然后程序会继续运行,生成最终报告。
5. 在 Jupyter Notebook 中使用(推荐):
建议在 Jupyter Notebook 中使用 Open Deep Research,因为可以更方便地查看中间结果和进行交互。 你可以参考 src/open_deep_research/graph.ipynb 文件中的示例。 该文件是一个完整的jupyter notebook,包含所有步骤。
6. 使用 LangGraph Studio UI (可选):
如果你想使用图形界面来运行 Open Deep Research,可以按照以下步骤操作:
-
克隆代码仓库:
git clone https://github.com/langchain-ai/open_deep_research.git cd open_deep_research -
安装依赖:
# 安装 dependencies pip install -e . pip install langgraph-cli[inmem] -
启动 LangGraph 服务器:
langgraph dev -
访问 Studio UI:
在浏览器中打开
https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024(以你的实际端口为准)。按照界面提示输入主题,并提供反馈。
Open Deep Research 核心思想、创新与优化
核心思想:
Open Deep Research 的核心思想在于 将深度研究过程分解为可配置、可交互的自动化工作流,并以 人机协作 的方式生成高质量的报告。它借鉴了 OpenAI 和 Gemini Deep Research 的理念,但强调 用户对整个研究过程的控制和干预,并利用 LangGraph 框架实现流程的模块化和可扩展性。
更具体地说,其核心思想可以总结为:
- 规划与执行分离: 将研究流程分解为报告规划和内容生成两个阶段。 报告规划由用户引导,保证报告的整体结构和方向符合用户的预期。 内容生成阶段采用自动化流程,提高效率。
- 人机协作: 在报告规划阶段,允许用户对报告结构和章节内容进行反馈,并可以调整优化方向。
- 可配置性: 允许用户自定义研究流程的关键参数,例如使用不同的搜索 API、LLM 模型、搜索深度等等。 这使得 Open Deep Research 适用于不同的研究场景和需求。
- 模块化与可扩展性: 基于 LangGraph 框架,将研究流程分解为独立的节点和边。 这种模块化的设计使得 Open Deep Research 易于维护、扩展和定制。
创新与优化:
Open Deep Research 在以下几个方面进行了创新和优化:
-
基于 LangGraph 的工作流引擎:
- 创新: 利用 LangGraph 框架构建研究流程。
- 优化: LangGraph 提供了状态管理、节点编排、并行处理和人机交互等功能,简化了研究流程的构建和管理。
-
灵活的配置系统:
- 创新: 引入
Configuration 类,集中管理可配置参数。 - 优化: 允许用户通过环境变量、配置文件或 RunnableConfig 对象灵活配置参数。 并能基于模型和搜索引擎,配置不同参数。
- 创新: 引入
-
模块化的搜索 API 抽象:
- 创新: 抽象不同的搜索 API (Tavily, Perplexity, Exa, ArXiv, PubMed) 到统一接口。
- 优化:
get_search_params() 函数根据所选 API 自动过滤和传递相应的参数。 新增搜索引擎只需要新增对应的模块即可,而不需要改动主流程。
-
智能查询生成与反思:
- 创新: 使用 LLM 模型根据报告主题和章节目标,生成高效的搜索查询。
- 优化: 在章节内容生成后,使用 LLM 模型进行反思,并生成后续查询,提升研究深度。
-
高效的数据处理和格式化:
- 优化:
deduplicate_and_format_sources() 函数高效地对搜索结果进行去重、截断和格式化,以满足 LLM 模型的输入要求。 这样做能节约token,节省费用。
- 优化:
-
可定制的 Prompt 模板:
- 创新: 使用预定义的 Prompt 模板,指导 LLM 模型生成报告计划、章节内容和搜索查询。
- 优化: 允许用户根据需求修改 Prompt 模板,以进一步控制研究流程和输出质量。
代码示例:
以下代码片段展示了 Open Deep Research 的一些创新与优化:
-
灵活的配置:
from open_deep_research.configuration import Configuration config = Configuration.from_runnable_config(runnable_config) # 从配置对象中加载配置 search_api = get_config_value(config.search_api) # 处理字符串枚举变量 -
统一的搜索 API 抽象:
if search_api == "tavily": search_results = await tavily_search_async(query_list) elif search_api == "perplexity": search_results = perplexity_search(query_list) # 其他搜索 API... -
智能查询生成与反思:
from open_deep_research.prompts import query_writer_instructions system_instructions = query_writer_instructions.format(topic=topic, section_topic=section.description) queries = llm.invoke([SystemMessage(content=system_instructions), HumanMessage(content="Generate search queries...")])
那么对于deep research来说,是以什么条件作为判断跳出思维链的标准的呢?
Open Deep Research 的思维链(主要是指在每个报告章节生成和迭代过程中)跳出标准主要基于以下几个条件:
-
章节内容质量评估(Grade):
- 这是最重要的判断标准。 在
write_section函数中,使用了LLM模型(通常是planner model)对生成的章节内容进行评估。 - 这个模型会根据
section_grader_instructions提示词来判断章节内容是否充分、准确、相关,并且是否解决了章节目标。 - 模型输出一个
grade字段,其值为 "pass" 或 "fail"。 如果grade 为 "pass",则认为章节内容质量达到要求,可以跳出思维链。
- 这是最重要的判断标准。 在
-
最大搜索深度限制(max_search_depth):
- 这是为了避免无限循环而设置的安全机制。
-
Configuration 类中的max_search_depth 参数限制了每个章节可以进行的最大搜索迭代次数(写作、反思、搜索、重写)。 -
write_section 函数会检查当前的搜索迭代次数 (state["search_iterations"]) 是否超过了max_search_depth。 如果超过,即使章节内容质量评估为 "fail",也会强制跳出思维链,防止无限循环。
具体的代码逻辑:
在 src/open_deep_research/graph.py 文件的 write_section 函数中,有以下代码:
# 如果章节通过了质量评估,或者达到了最大搜索深度,则发布章节并停止迭代
if feedback.grade == "pass" or state["search_iterations"] >= configurable.max_search_depth:
# 发布章节到已完成章节列表
return Command(
update={"completed_sections": [section]},
goto=END
)
# 否则,更新搜索查询,继续搜索和写作
else:
return Command(
update={"search_queries": feedback.follow_up_queries, "section": section},
goto="search_web"
)
Open Deep Research 使用 章节内容质量评估 和 最大搜索深度限制 作为双重标准,判断是否跳出思维链。前者保证章节内容达到质量要求,后者防止无限循环。这两个条件的结合,在保证研究深度的同时,也提高了研究的效率和可靠性。
在实际使用中,可以调整 max_search_depth 参数,以控制研究的深度和耗时。 如果需要更高的质量,可以增加 max_search_depth,但也要注意避免进入无限循环。同时,prompt的设计也会极大的影响思维链的效果,好的prompt可以大大减少迭代的次数。