目录
- Hibernate的介绍与执行流程
- 运行流程:
- Hibernate运行环境搭建
- Hibernate的基础示例
- 持久类的编写
- 持久类的介绍
- 几个考虑遵守的规则:
- 补充:
- Hibernate核心文件配置
- 使用XML配置核心文件:
- 基础配置选项
- 可选配置:
- 使用properties配置核心配置:
- 核心配置文件的加载:
- c3p0连接池的配置:
- 补充:
- 使用XML配置核心文件:
- Hibernate映射文件配置
- 怎么配置映射文件:
- 主键生成策略:
- 补充:
- Hibernate与数据库的连接
- Configuration:
- SessionFactory:
- Session:
- Transaction:
- Hibernate操作数据表之增删查改CRUD
- 新增:
- 查询:
- 修改:
- 删除:
- 缓存
- 缓存对效率的影响:
- 持久化类对象的三种状态:
- 事务管理
- 事务的开启、提交与回滚:
- 事务隔离级别配置:
- 不同函数中的事务管理:
- 关系映射:
- 一对多关系:
- “一”方的配置:
- “多”方的配置
- 其他配置与测试类
- 补充
- 多对多关系:
- 级联操作:
- 一对多的级联操作设置:
- 多对多的级联操作设置:
- 示例:
- 放弃外键维护问题:
- 一对多关系:
- 日志
目录:
首发日期:2018-07-31
修改:
- 2018-08-11:从头回顾了一遍,对各个地方增加了讲解,以帮助读者更好地了解。修改了关系映射中的错误表述,由于重复次数问题,导致那里我填混乱了。
- 2018-10-25:把原来的版本修改成了markdown版本的,重新整理了顺序和内容解释,把图片都转存到我的图床,并重新发布了博文。
Hibernate的介绍与执行流程
- Hibernate是一个持久层的框架(持久层做的事通常都是将数据保存到数据库中)。
- Hibernate是基于ORM的框架。ORM把对象和数据表建立了关系,使得可以通过操作对象来操作表。ORM可以根据对象与数据表的映射关系来处理SQL语句,类对象的创建可以对应数据表记录的插入操作,类对象的更改可以对应数据表记录update操作。基于ORM之后,对于对象的操作会自动生成对应的SQL语句来处理数据表,而不需要像JDBC那样需要自己去拼接SQL语句,省去了很多麻烦。
题外话:
什么是ORM(对象关系映射):ORM 将数据库中的表与面向对象语言中的类建立了一种对应关系,【ORM可以说是参照映射来处理数据的模型,比如说:需要创建一个表,可以定义一个类,而这个类存在与表相映射的属性,那么可以通过操作这个类来创建一个表】
为什么需要ORM框架:JDBC的API是最底层的操作数据库的API了,但明显的是,使用它很麻烦,因为每一个交互都需要你去编写(包括编写SQL语句之类的);而使用ORM,它帮你定义了关系和封装了API,使得你可以远离底层,比如你可以调用save(类对象),这可以让你很轻松的将这个对象的各个属性插入到与类建立了关系的对应数据表中。
运行流程:
1.当使用Hibernate时,Hibernate需要先去加载一个核心配置文件,读取Hibernate的核心配置信息(数据库连接信息、日志管理、数据表映射关系等)【在读取的过程中,会将读取的配置信息逐一配置给对应的组件(连接池、日志等等)。】;
2.载入核心配置文件的过程的最后是读取核心配置文件中标注的“映射关系文件”。“映射关系文件”定义着持久化类与数据表之间的映射关系。(在读取映射关系文件的过程中,同时会判断是否有对应的数据表,如果没有表可能会根据类与表的映射关系来创建表,表建立之后,再建立映射);
3.核心配置和映射关系都读取完毕之后。Hibernate的基本运行配置就配置完毕了。在前面的加载配置中,返回的是一个Configuration对象,Configuration对象主要是用来获取配置文件的。
4.通过Configuration对象的buildSessionFactory方法获取一个sessionFactory对象,sessionFactory对象真正负责解析配置文件中的配置选项并配置给各个组件,在很多时候,sessionFactory对象相当于一个连接池,它解析了Hibernate的配置并负责分发会话连接。
5.通过sessionFactory对象的openSession方法来获取一个Session对象,有了Session对象就相当于有了JDBC中的Connection对象,它相当于与数据库的会话连接。我们可以使用Session对象来操作数据库。
6.对于增删改操作,我们需要事务管理对象Transaction对象的协助。可以通过Session对象获取一个Transaction对象,Transaction对象负责数据库的事务管理。
7.对于增删改操作,需要开启事务对象Transaction,但对于查询操作,是不需要事务的。对于增删改操作,可以通过Session对象的调用save\delete\update方法来操作数据库;对于查询操作,可以通过get\load等方法来操作数据库。
Hibernate运行环境搭建
下面的运行环境基于的是Hibernate5.3.0
【不过更建议使用低一点的版本的,比如可以使用5.0.x版本的】
【据说Hibernate5.x要求JDK版本最低要1.7?不过我没尝试过,如果发现报错,可以考虑一下可能是因为这个问题。】
【如果你会maven的话,也可以尝试自查一下maven搭建Hibernate】
1.在官网下载Hibernate5
下载方法可以参考一下这个:https://jingyan.baidu.com/article/7e4409530e67d82fc0e2eff9.html
2.解压下载的压缩包

3.在解压出来的文件夹中,lib存放着Hibernate运行所需要的jar包。lib目录下有好几个文件夹,每个文件夹下有Hibernate不同功能需求的jar包。

4.因为这里仅仅做最基础的运行,所以仅仅将required中的11个jar包导入到工程中。
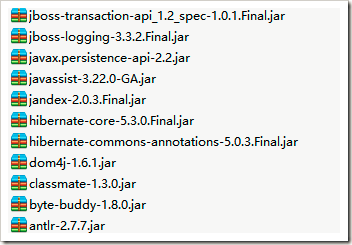
如果你还需要其他功能,可以按照前面图中标注不同功能的文件夹来选择添加。比如想要使用C3P0,可以将optional文件夹中c3p0文件夹下的包都导入。
5.导入Hibernate之外的包:由于Hibernate是持久层的框架,所以它还需要数据库驱动包。另外,Hibernate依赖slf4j日志接口,所以也需要导入。
- 数据库驱动包:
 【版本可以比较随意】
【版本可以比较随意】
- 日志包
 【这是Hibernate的日志接口,如果要扩展日志功能,需要这个接口】【这个可以在lib\spatial中找到】
【这是Hibernate的日志接口,如果要扩展日志功能,需要这个接口】【这个可以在lib\spatial中找到】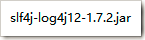 【slf4j只是一个日志接口,没有具体的日志功能,这里我们使用log4j来实现日志功能,但slf4j不能直接到log4j,它需要转换器,这个就是转换器】【这个需要你自己下载】
【slf4j只是一个日志接口,没有具体的日志功能,这里我们使用log4j来实现日志功能,但slf4j不能直接到log4j,它需要转换器,这个就是转换器】【这个需要你自己下载】 【这个也需要你自己下载】
【这个也需要你自己下载】
6.导入包之后,运行环境就基本搭建完毕了。后面都是具体需求具体配置了。
Hibernate的基础示例
这个基础示例作用是让你了解Hibernate的使用需要做什么?先让你了解需要做什么,后面再讨论每个流程里面能够做哪些操作。这个示例可以与上面的运行流程结合了解。
1.运行环境搭建,导入需要的依赖包。
2.创建持久类Person,持久类用于跟数据表建立映射关系,类的成员变量与数据表的字段对应。
public class Person {
private Long pid;
private String username;
private Integer age;
private Integer address;
public Long getPid() {
return pid;
}
public void setPid(Long pid) {
this.pid = pid;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getAddress() {
return address;
}
public void setAddress(Integer address) {
this.address = address;
}
}3.创建映射文件Person.hbm.xml,这个文件的意义是将持久类与数据表的属性建立映射关系(具体配置先不说,只在图内简单介绍,下面再具体介绍),以便使用ORM操作来管理数据表。这个映射文件与持久类Person位于同一个包下。
映射文件主要包括类与表的对应,以及它们之间的成员变量与字段的对应。

4.创建核心配置文件:hibernate.cfg.xml,这个核心配置文件包含了数据库连接信息、hibernate自身配置(方言,是否显示SQL语句)、映射文件路径等信息

【上图有个自动建表操作:数据表也可以交给Hibernate创建(但不建议,因为方言会影响使用什么语句来创建数据表,有时候方言与数据库版本之间会有一些问题。所以十分建议提前创建,不然你可能会遇到其他问题】
5.Hibernate的核心配置文件和映射文件已经写好了,那么下面的重点就是获取对象来操作了。使用Configuration来读取核心配置文件,返回结果是Configuration对象,这个对象包含了Hibernate的配置信息(就好比工厂有了设计图纸),下面的操作会自动读取hibernate.cfg.xml中的配置。
![]()
6.使用前面获取到的Configuration对象来获取一个SessionFactory对象,SessionFactory对象是解析了Hibernate的配置信息。(可以说SessionFactory对象就是一个获取到图纸之后,已经做好准备开工的工厂)
7.SessionFactory对象可以翻译成session工厂,可以使用它来获取Session对象,Session对象建立了与数据库的会话连接,相当于JDBC中的Connection对象,我们可以使用Session对象来与数据库交互。【Transaction是事务对象,负责管理事务,对于增删改都需要事务对象。】

上面的过程就是通过保存一个对象来将数据存储到数据表中的过程。
持久类的编写
持久类的介绍
- 持久类是用于跟数据表产生映射关系的类。 一个没有映射关系的类不是持久化类。
- 持久类的定义与普通的javabean没有什么区别,如果你了解javabean,那么你应该知道javabean有三个标准:
- 1.属性私有化
- 2.有无参构造函数 (Hibernate同样需要利用反射来创建对象,从数据表中获取数据记录时会转成一个个对象)
- 3.提供私有的属性的公有getter和setter函数。
- 除了以上与javabean相同的要求之外,还需要一个唯一标识属性(也可以称为OID,对象标识(Object identifier-OID))。它相当于数据表中的主键,Hibernate利用唯一标识属性(OID)来特异性地识别每个对象。
一个简单示例:
public class Person {
private Long pid;//唯一标识属性,用来映射表中的主键
private String username;
private Integer age;
private Integer address;
public Long getPid() {
return pid;
}
public void setPid(Long pid) {
this.pid = pid;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getAddress() {
return address;
}
public void setAddress(Integer address) {
this.address = address;
}
}几个考虑遵守的规则:
1.持久化类的属性尽量使用包装类类型。【因为基础数据类型通常存在默认值并且通常不为null,这个默认值也会存储到数据表中,如果不注意就会引起歧义。,null在数据表中是空的意思,在数据表中它的意义是明确的,但如果默认值是0的话,意思就是不明确了。比如某个字段用0,1代表男女,那么默认值为0的话就不好确定是否是忘记设置性别还是已经设置了。】
2.持久化类不要使用final修饰,不然无法使用延迟加载功能(这个东西将会在后面的CRUD中load()方式的查询中讲),延迟加载功能依赖于代理对象,使用final修饰之后就无法产生代理对象了。
补充:
- 持久类还有三种状态需要认识,因为涉及到与数据库的交互和缓存区,所以留到后面缓存那里再讲。
Hibernate核心文件配置
核心配置文件的配置方式有使用properties和xml这两种,我们主要使用xml版,因为xml版可以导入映射文件,而使用properties版的就需要自己在代码中引入映射文件。
使用XML配置核心文件:
- 命名要求:hibernate.cfg.xml 【保存路径:src目录下,否则需要在.configure()的时候传入它的路径】
- XML需要约束,那么它的约束头去哪里找:它在依赖包hibernate-core-5.3.0.Final.jar下的org.hibernate下的hibernate-configuration-3.0.dtd的注释中(hibernate5与hibernate3的相似,所以使用的是3.0的dtd)。
- xml文件结构:根标签为hibernate-configuration标签,hibernate-configuration标签里面包含了一个session-factory标签,session-factory里面使用property标签写配置信息。
属性值
基础配置选项
基础配置选项是必须要配置的选项
- 数据驱动
- 格式:
数据驱动 - 例如:
com.mysql.jdbc.Driver
- 格式:
- 数据库url
- 格式:
url - 例如:
jdbc:mysql://localhost:3306/hibernate
- 格式:
- 数据库用户名
- 格式:
用户名 - 例如:
root
- 格式:
- 数据库用户密码
- 格式:
密码 - 例如:
123456
- 格式:
- SQL方言:定义了怎么转换SQL语句,就好像使用谷歌翻译需要确定转成哪种语言 【下面会讲能填哪些值】
- 格式:
方言 - 例如:
org.hibernate.dialect.MySQL5Dialect
- 格式:
- 映射关系文件:【注意,映射关系文件要放在最下面!它是核心配置中最后加载的】
- 格式:
- 例如:
- 格式:
可选配置:
可选配置是说明下面的配置是可选的 ,可以不配置
- 显示对应的sql语句:使用hibernate操作对象,会转成对应的sql语句,可以设置sql语句是否显示到控制台。
- 格式:
true或false - 例如:
true
- 格式:
- 格式化显示的sql语句 :当选择显示sql语句后,默认的是一行显示的,使用格式化后,是多行的。
- 格式:
true或false - 例如:
true
- 格式:
- 是否自动建表hibernate.hbm2ddl.auto :
- 格式:
create或creat-drop或update或validate - 不配的时候:不使用hibernate的建表功能
- create:不论有没有表,每次都重新创建表。
- update:如果没有表,就创建;如果有了,就用已有;如果定义的表结构跟现有的不符合,那么修改成定义的表结构。
- create-drop:不论有没有表,每次都重新创建表,并且在用完后就会删除。
- validate:不会创建表,只会使用已经有了的表,所以如果结构不符合会报错。
- 例如:·
update
- 格式:
下面给出一个配置好了的hibernate.cfg.xml:
com.mysql.jdbc.Driver
jdbc:mysql://localhost:3306/hibernate2
root
123456
org.hibernate.dialect.MySQL5Dialect
update
true
true
那么,去哪里看能配什么,配哪些值呢?
在hibernate解压包的project的etc下面有一个hibernate.properties,里面有hibernate的核心配置信息。想使用什么功能,ctrl+f查找一下即可。
这里提醒一下,对于Hibernate5.3之前的版本,对于mysql方言,它或许能够支持下图中显示的方言。但要提醒的是,如果你使用了mysql5以上的版本并且Hibernate是5.3,那么mysql方言你必须使用Mysql5XXXX(在原来的基础上加个5)
除了在hibernate.properties中,我们还可以通过依赖包来查看。比如依赖包中的org.hibernate.dialect包含的就是方言的class文件,你看名字就能够了解有哪些方言了。

使用properties配置核心配置:
- 命名要求:hibernate.properties
- 配置选项:在xml的配置方法中,相信你已经了解了有哪些选项可以配置了。xml版的和properties版的配置选项是一样的。
- 格式:类似hibernate.connection.driver_class=com.mysql.jdbc.Driver
核心配置文件的加载:
- xml版本:使用new Configuration().configure()会自动查找文件名为hibernate.cfg.xml的配置文件来加载配置信息。
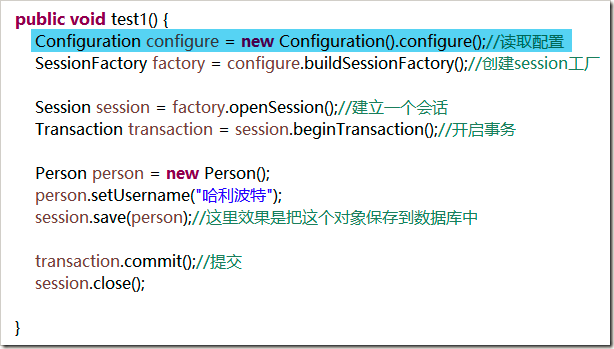
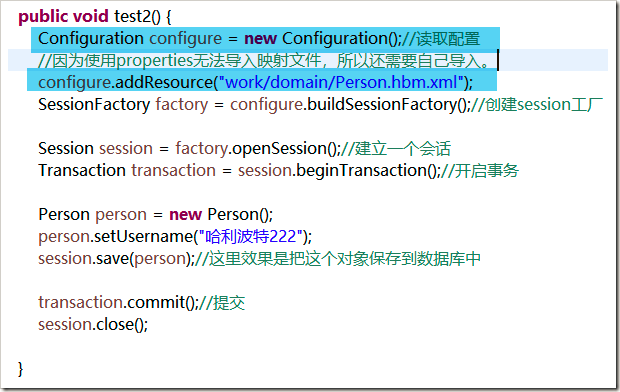
- properties版本: 使用new Configuration()来读取hibernate.properties 中的配置信息,映射文件需要使用configure.addRrsource(文件路径)来导入。
c3p0连接池的配置:
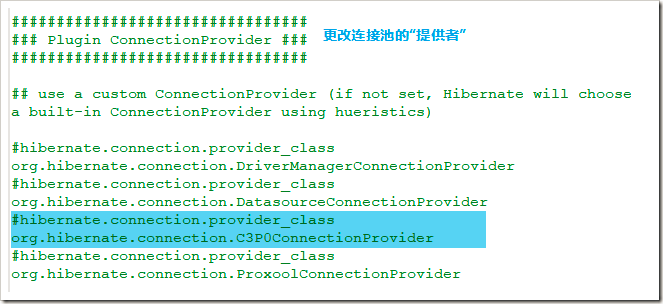
hibernate有自己的内置连接池,但很多时候,我们会考虑使用别的连接池,c3p0就是常用的选择。要使用c3p0连接池,也需要在核心配置文件中进行配置,下面介绍怎么配置。
1.首先需要配置hibernate的连接提供者,改成由C3P0提供:
2.然后配置c3p0的选项:
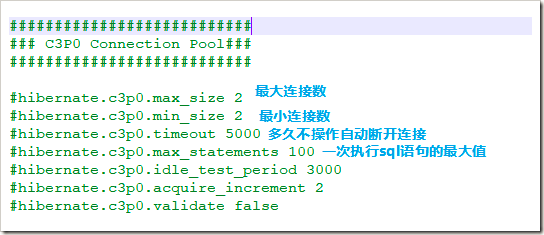
org.hibernate.connection.C3P0ConnectionProvider
5
20
120
注意,要记得导入c3p0的依赖包,它在hibernate解压包的lib的optional的c3p0中。
补充:
- 选项hibernate.XXX前面的hibernate.是可以省去的。
- 事务管理也需要核心配置文件的配置,这部分将在事务管理那里再讲。
- 还有很多的配置,但都相对少用,有需要再去properties查找一下即可。
Hibernate映射文件配置
映射文件的结构大概如下:
怎么配置映射文件:
映射文件名要求:类名.hbm.xml,例如Person.hbm.xml
标准xml首部:
xml约束:hibernate的映射文件使用的是she对于映射文件,它的dtd可以在依赖包hibernate-core-5.3.0.Final.jar下的org.hibernate下的hibernate-mapping-3.0.dtd的注释中中获取。(hibernate5与hibernate3的相似,通常使用hibernate-mapping-3.0.dtd的)。
- 配置选项:
- hibernate-mapping 标签:根标签,class标签是它的子标签
- class标签:用来定义持久类与数据表的映射关系。
- 属性:
- name:对应的持久类的全路径 【全限定名,就是用.划分的路径】
- table:对应的数据表的名字
- catalog:数据库名【比较少用】
- 常见子标签:id,property,set(涉及一对多,多对多),many-to-one(涉及一对多)
- 属性:
- id标签:用来建立类中的唯一标识属性(OID)与表中的主键的对应关系,OID可以唯一标识每一个持久类类对象。
- 属性:
- name:对应的持久类的唯一标识属性的名字
- column:对于表中的主键名【如果表中的主键与持久类中的唯一标识属性同名,那么可以省去column】
- length:定义数据类型的长度
- type:字段的数据类型
- 常见子标签:generator(用来定义主键生成策略,会在下面具体讲。)
- 属性:
- property标签:用来建立类中的普通属性与表的字段的对应关系
- 属性:
- name:对应的持久类的属性名
- column:对于表中的字段名【如果表中的字段名与持久类中的属性同名,那么可以省去column】
- length:定义数据类型的长度
- type:字段的数据类型【type和length主要是用来定义字段的属性的,如果你不关心字段的属性,只需要映射关系,那么可以省去。】【如果定义了type和length,那么会根据策略来判断是否去更改表结构;没有表的时候,会根据这些属性来创建新表;如果没表也没有这些关于字段的属性的属性,那么会使用默认值。比如varchar长度会达到255】
- not-null:字段是否为空。【也是用来定义字段的属性的,可以不用】
- unique:字段是否有唯一属性。【也是用来定义字段的属性的,可以不用】
- 属性:
主键生成策略:
id标签用来配置主键,generator标签是id标签的子标签,它是用来配置主键生成策略的(主键的值的策略),generator的class的值常用的有如下几个:
- increment:使用Hibernate自增长机制来生成主键。使用这个属性之后,使用自动建表,表会有主键属性。但它是线程不安全的,它的原理是获取数据库中主键当前最大值来确定新主键的值。所以它只能用于单线程。
- identity: 使用数据库自带的自增长机制,适用于DB2、SQL Server、MySQL、Sybase。
- sequence:使用数据库自带的自增长机制,适用于oralce、DB、SAP DB、PostgerSQL。
- uuid:随机生成字符串作为主键的值。
- native:使用数据库自带的自增长机制,会根据不同的数据库来采用identity或sequence。
- assigned:放弃管理,由自己调用setter函数给主键设置值。
- foreign:使用关联表的主键值作为主键的值。主要用于一对一关系中。【这个这里不讲,因为太少用了】
补充:
- 映射文件的配置中还有一个重头戏-- 一对多、多对多关系的配置,因为这是一个重点内容,所以分到下面的关系映射中来讲。
Hibernate与数据库的连接
- 上面已经讲述了配置核心配置文件,配置映射文件,也就是说基本的准备已经做好了,接下来的内容就是Hibernate利用这些配置来与数据库进行交互了。
- 这小节主要讲Hibernate与数据库的连接,下一节才会讲到操作数据表。
- 要了解Hibernate与数据库的连接的,首先要了解以下几个类。
Configuration:
- 作用:它负责加载核心配置文件,在上面的核心配置文件中有讲到核心配置文件的加载,这里再次提一下。
- 使用:
- 对于xml版的核心配置文件:只需要Configuration cfg = new Configuration().configure() 返回的是读取了hibernate.cfg.xml配置的Configuration对象
- 对于properties版的核心配置文件:由于properties版的无法导入映射文件,所以需要加载配置:Configuration cfg = new Configuration(),然后再导入映射文件:configuration.addResource("work/domain/Customer.hbm.xml");
- 对于xml版的核心配置文件:只需要Configuration cfg = new Configuration().configure() 返回的是读取了hibernate.cfg.xml配置的Configuration对象
SessionFactory:
- 作用:加载了核心配置文件之后,就需要进行hibernate与数据库的连接了,SessionFactory对象在很多时候都可以直接认为是一个连接池对象(主要功能)。它可以由Configuration类对象调用buildSessionFactory方法来获取。它调用openSession方法可以创建一个Session对象(相当于数据库连接会话对象)。
- 使用:
- 获取 SessionFactory:
SessionFactory factory = configure.buildSessionFactory() - 创建Session:
Session session=factory.openSession()
- 获取 SessionFactory:
Session:
- 作用:SessionFactory对象相当于一个连接池对象,那么可以从它那里获取连接,返回的是一个Session对象,Session对象就相当于jdbc中的Connection对象,我们可以使用Session对象来操作数据库。
- 使用:
- 创建Session:
Session session = factory.openSession(); - session有很多操作数据表的方法,如何使用session来操作数据库,我们下面再讲。这里主要讲如何进行连接。
- 创建Session:
Transaction:
- 作用:Hibernate的增删改操作需要事务管理,Transaction是事务管理对象,它可以通过Session对象来获取。
- 使用:
- 获取:
Transaction transaction = session.beginTransaction();【这样就为这个session开启了事务】 - 提交事务:
transaction.commit(); - 回滚事务:
transaction.rollback();
- 获取:
了解上面对象的作用与使用之后,我们就可以得出以下与数据库建立连接并交互的步骤:

Hibernate操作数据表之增删查改CRUD
了解了怎么建立与数据库的连接之后,下面就是CRUD的内容了。
【不要忘了!Hibernate的增删改需要事务管理】
新增:
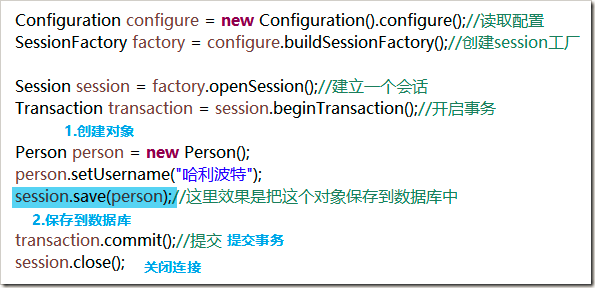
1.创建持久类对象,给持久类对象设置属性。
2.session对象调用save(Object obj)来保存到数据库,对象的数据会根据映射关系存储到对应的数据表中。
查询:
查询是一个很重要的内容,考虑到这篇博文已经很长了的,所以我留到另外一篇博文去讲述了。
详情点击下面超链接。查询
修改:
修改有两种方法:
1.创建一个对象,给对象的唯一标识属性(OID)赋予一个值,给各个属性赋值,然后session.update(这个对象)【这样会把OID对应的数据库记录的所有字段都改成对象的对应属性,所以如果不正确赋值的话,数据库中字段的值会出错。】
public void test1() {
Configuration cfg = new Configuration().configure();
SessionFactory factory = cfg.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
Person person = new Person();
person.setId(1L);
person.setUsername("葫芦娃");
session.update(person);
//这样的缺点是没有set的属性值都是null,并会写到数据表中
transaction.commit();
session.close();
}2.先查询,再修改【推荐操作,查询出来后,对象中存储着原有的属性】:先查询出对象,修改好对象的指定属性,然后session.update(这个对象)
【这里给的例子使用的查询是OID查询,更多查询方法请查看"查询"那里的用法】
public void test1() {
Configuration cfg = new Configuration().configure();
SessionFactory factory = cfg.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
Person person = session.get(Person.class, 2L);
person.setUsername("葫芦娃");
session.update(person);
transaction.commit();
session.close();
}删除:
删除有两种方法:
1.创建一个对象,给对象的唯一标识属性赋予一个值,然后session.delete(这个对象)
2.先查询,再删除:先查询出对象,然后session.delete(这个对象)【推荐先查询,再删除,如果涉及到表与表之间的关联(外键),那么需要先查询再删除,不然查找不到外键,从而无法级联处理,这个后面讲】
【这里给的例子使用的查询是OID查询,更多查询方法请查看"查询"那里的用法】
public void test2() {
Configuration cfg = new Configuration().configure();
SessionFactory factory = cfg.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
Person person = session.get(Person.class, 2L);
session.delete(person);
transaction.commit();
session.close();
}缓存
缓存:是一种优化的方式,将数据存入到内存中,内存要比硬盘快,普通的查询是查询存储在硬盘中的数据库数据,使用缓存后可以直接从缓存中获取之前存储下来的数据,不需要从数据源中重新获取。
- session管理着Hibernate的一级缓存。
- 缓存区中有一块特殊的区域--快照区,缓存区存储着“本地对象”,快照区存储着"查询到的对象"。
- 缓存区是用来存储被session管理的持久类对象的(刚刚查询得来的对象、新创建的并通过session保存了的对象都会保存到缓存区),通常来说都是处于“持久态”的对象;
- 而快照区存储的是查询来的对象,主要用于校验本地对象的数据跟数据表是否一致。查询到的对象是可以修改的,修改的是缓存区中的对象,但快照区只会存储上次查询结果。
- 一个新建的对象是不会存储到缓存区的,只有它被session管理了,才会存储到缓存区中,并且不会存储到快照区中。
缓存对效率的影响:
- 查询一个持久类对象时,如果这个持久类对象缓存区已经有了,那么不会再发送SQL语句,而是从缓存区中获取对象,避免了重复发送SQL。
- 修改一个持久类对象后,如果缓存区的对象与快照区的对象的数据不一样,那么会自动发SQL语句来更新到数据表中,这样不需要显式update。
上面了解了缓存区之后,有提到存储到缓存区的通常都是持久态对象,下面了解一下持久类对象的三种状态。
持久化类对象的三种状态:
瞬时态:新建的持久类,唯一标识属性(OID)没有值的时候,没有被session管理的时候。
持久态:唯一标识属性有值,被session管理的时候(要么是用session刚从数据库中查询出来的;要么是已经使用过session保存到数据库中,并且还没有被删除的。)。持久态的对象会存储到缓存区中,用来提高效率。
脱管态:唯一标识属性有值,不被session管理的时候。
持久类状态转换图:

事务管理
事务的开启、提交与回滚:
开启事务:Transaction transaction = session.beginTransaction();
事务提交:transaction.commit();
事务回滚:transaction.rollback();
public void test1() {
Configuration configuration = new Configuration().configure();
SessionFactory factory = configuration.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
Account account = session.get(Account.class, 1L);
Account account2 = session.get(Account.class, 2L);
try {
account.setMoney(account.getMoney()-100);
account2.setMoney(account2.getMoney()+100);
transaction.commit();//不发生异常的时候,提交
}catch (Exception e) {
transaction.rollback();//发生异常,回滚
}finally {
session.close();
}
}事务隔离级别配置:
事务隔离级别配置要在核心配置文件中配置:
值可以为一下四个:【左边是值,右边是级别,值代表的级别的意义就不说了,是sql那边的内容。】
1:Read Uncommitted
2:Read Committed
4:Repeatable Read
8:Serializable
不同函数中的事务管理:
我们从上面学会了怎么使用事务--用session来开启。但你可能遭遇两个“动作”不在一个session中的情况,这种情况是很经常见的,因为分工越细效率越高。例如银行的转钱操作,这种需要一方加钱,一方减钱,通常来说我们不会把加钱减钱都定义到一个函数中,而是把他们分开,这样别的情况需要加钱时就可以直接调用函数了。而不同的session之间的事务是隔离的,这时候两个操作处于不同session的话就没办法进行统一的事务管理了。
@Test
public void test2() {
Configuration configuration = new Configuration().configure();
SessionFactory factory = configuration.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
Account account = session.get(Account.class, 1L);
Account account2 = session.get(Account.class, 2L);
reduceMondy(account,100.0);
addMoney(account2,100.0);
transaction.commit();//不发生异常的时候,提交
session.close()
}
public void reduceMondy(Account account, double d) {
Configuration configuration = new Configuration().configure();
SessionFactory factory = configuration.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
account.setMoney(account.getMoney()-d);
session.update(account);
transaction.commit();
session.close()
}
public void addMoney(Account account, double d) {
Configuration configuration = new Configuration().configure();
SessionFactory factory = configuration.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
account.setMoney(account.getMoney()+d);
int a=10/0;//这次出一下异常,测试两者的事务是不同的,结果,一方钱少了,一方没加钱
session.update(account);
transaction.commit();
session.close()
}你可能会想到把某个session作为形参传进去,这样两个函数用的就是一个session了,这是一个解决方法。
但Hibernate提供了一个更好的解决方案。我们可以使用getCurrentSession来获取session(需要在核心配置文件中配置,下面将如何配置),getCurrentSession是通过当前线程来获取一个session,当调用getCurrentSession来获取session时,Hibernate会把这个session存储到线程中,其他函数调用getCurrentSession来获取session时,获取的session是同一个,所以同一个线程执行不同的函数依然可以很好的进行事务管理。
@Test
public void test2() {
Configuration configuration = new Configuration().configure();
SessionFactory factory = configuration.buildSessionFactory();
Session session = factory.getCurrentSession();
Transaction transaction = session.beginTransaction();
Account account = session.get(Account.class, 1L);
Account account2 = session.get(Account.class, 2L);
try {
reduceMondy(account,100.0);
addMoney(account2,100.0);
transaction.commit();
}
catch (Exception e) {
transaction.rollback();//发生异常,回滚
}
}
public void reduceMondy(Account account, double d) {
Configuration configuration = new Configuration().configure();
SessionFactory factory = configuration.buildSessionFactory();
Session session = factory.getCurrentSession();
//当使用同一个session时,事务的开启应该在调用这个两个函数的地方开启
account.setMoney(account.getMoney()-d);
session.update(account);
}
public void addMoney(Account account, double d) {
Configuration configuration = new Configuration().configure();
SessionFactory factory = configuration.buildSessionFactory();
Session session = factory.getCurrentSession();//从线程中获取session
//当使用同一个session时,事务的开启应该在调用这个两个函数的地方开启
account.setMoney(account.getMoney()+d);
int a=10/0;//这次出一下异常,测试两者的事务是不同的
session.update(account);
}所以很多时候,factory.getCurrentSession()取代了Session session = factory.openSession()。
getCurrentSession的正常使用需要核心配置文件加上一个配置选项:
采用getCurrentSession()创建的Session在commit或rollback后会自动关闭,而采用OpenSession()必须手动关闭。
关系映射:
在上面的基础示例中,演示的是一个单表的例子。而事实上,项目中的表与表之间是有关系的。并且我们经常需要利用这些关系来获取数据。
一对多关系:
【例子演示以班级与学生之间的一对多关系(假设一个班级可以有多个学生,一个学生只能有一个班级)为例】
“一”方的配置:
在“一”的一方的持久类中需要增加一个“多”一方持久类组成的集合(这里的集合最好提前new一下,免得后面再去赋值,new了之后,后面就可以直接get来add了)。
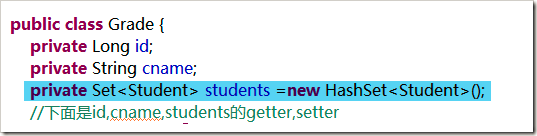
- 在数据库一对多关系管理中,通常在多的一方的表中创建外键。所以就算持久类多了一个集合,也不会映射到数据表中。这个集合主要是用来帮助Hibernate处理它们之间的关系的,不会在表中生成新的字段。
创建“一”一方的映射关系文件,除了基本字段关联之外,还使用set标签来定义关系。在set标签中,name属性是集合对象的变量名,子标签key中的column属性是“多”一方的外键字段名。子标签one-to-many的class属性是“多”一方的类的全路径。
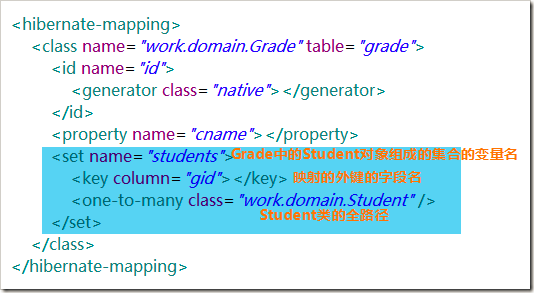
“多”方的配置
在多的一方的持久类中增加一个“一”一方的持久类对象,多出来的“一”一方的类的对象是用来映射成外键字段的(对象跟外键的映射关系需要在映射文件中配置),从面向对象来说就是利用对象的包含关系来映射多对一的关系。(在数据表中我们使用外键来定义一对多的关系,在类中,我们使用对象包含对象来定义一对多的关系。这个O类相对于M类来说就是M类对应表的外键)

- 在数据库一对多关系管理中,通常在多的一方的表中创建外键。所以上面增加的“一”一方的对象会映射成外键(这个映射规则需要定义,下面讲)。
创建“多”一方的映射关系文件,除了基本字段关联之外,还使用many-to-one标签来定义关系。many-to-one标签中,name属性是那个M中存储的O的对象的变量名,class属性是O的类的全路径,column属性是“一”一方的对象要映射成的外键的字段名(这个字段名会出现在“多”一方的表中,并使用“一”一方的主键值作为值)。

其他配置与测试类
在hibernate.cfg.xml中导入映射文件
编写测试类,将一一方的对象和多一方的对象互相建立上关系(把一一方的对象设置到多一方的对象的属性中,把多一方的对象添加到一一方的集合中),然后使用save保存起来。
创建两个学生(李白、杜甫)、一个班级(唐朝);给学生的grade属性设置为班级对象并将两个学生加入到班级对象的学生集合中;把三个对象都保存起来。
public void test3() {
Configuration configure = new Configuration().configure();
SessionFactory factory = configure.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
//创建两个学生一个班级
Student s1=new Student();
Student s2=new Student();
s1.setName("李白");
s2.setName("杜甫");
Grade g=new Grade();
g.setCname("唐朝");
//设置关系
s1.setGrade(g);
s2.setGrade(g);
g.getStudents().add(s1);
g.getStudents().add(s2);
//保存
session.save(s1);
session.save(s2);
session.save(g);
transaction.commit();
}结果:


结果显示了它们建立的一对多的关系,操作一方对象会给外键字段字段赋值。
补充
- 上面说的一一方的那个集合不会映射到数据表中,仅仅作为Hibernate关系管理依据,如果这个关系你不怎么用到的话可以不配置,如果查询中经常要用到通过多一方查询一一方,而不使用通过一一方查询多一方的话,那么这个关系就是没有用处的,这时候一一方的关系可以不配置,仅仅配置多一方的。【想了解更详细,可以了解一下这个:https://blog.csdn.net/u011781521/article/details/71172874】
多对多关系:
(假设一方为A,一方为B)
1.创建A的持久类,里面有一个B类对象组成的集合【例子演示以一个商品可以属于多个购物车,一个购物车可以有多个商品为例。】
创建购物车类ShopCar:

2.创建B的持久类,里面有一个A类对象组成的集合,
创建产品类Product:

3.创建A的hbm,使用property配置好基本属性,使用set配置配置集合:set中的name的值是自身存储的对方对象的集合的变量名,table是中间表的名称(自动创建);key中的column的值是自身在中间表映射的外键字段名;many-to-many中class的值是对方类的全路径,column的值是对方类在中间表映射的外键字段名。
创建ShopCar.hbm.xml:

4.创建B的hbm,像第三步一样配置好
创建Product.hbm.xml:

5.在hernate.cfg.xml中导入映射文件
6.编写测试类,将一个A类对象与多个B类对象建立关联,将一个B类对象与多个A类对象建立关联,把所有A和B的对象保存,查看中间表的数据。
编写测试类,建立两个Product,建立两个ShopCar,让他们之间相互都建立起关联。
public void test4() {
Configuration configure = new Configuration().configure();
SessionFactory factory = configure.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
//新建两个订单,两个产品
ShopCar o1=new ShopCar();
ShopCar o2=new ShopCar();
o1.setCustomer("马云");
o2.setCustomer("马化腾");
Product p1=new Product();
Product p2=new Product();
p1.setProduct_name("聚宝盆");
p2.setProduct_name("招财猫");
//相互建立关系
o1.getProducts().add(p1);
o2.getProducts().add(p1);
o1.getProducts().add(p2);
o2.getProducts().add(p2);
//保存
session.save(o1);
session.save(o2);
session.save(p1);
session.save(p2);
transaction.commit();
}结果:

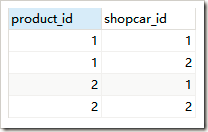
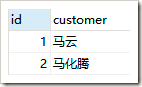
级联操作:
- 什么是级联操作?当表之间有关系的时候,对一个表做操作(删除、修改),会对应去更改关联的表(例如修改班级的id时会对应去修改学生记录中的班级id)。
- 【注意!这里的关系相对于表而言,但对于对象来说,是对象中是否存储着另一方的对象(当然还需要映射关系文件的帮助),所以只有在对象上关联上的才会级联,没有关联上的不会级联】(这就是为什么上面的修改和删除要先查询再操作的原因)
一对多的级联操作设置:
- 级联操作由cascade属性影响。
- save-update 【级联保存或修改】
- many-to-one中配置了,那么"多"一方的对象保存时,会同时保存建立了关系的"一"一方的对象。
- set中配置了,那么"一"一方的对象保存时,会同时保存建立了关系的"多"一方的对象。
- delete【级联删除】
- 这个比较少有与多对多,通常使用于一对多中的“一”一方(一个球队解散了,就删除对应的球员信息)。
- save-update 【级联保存或修改】
- 一一方的cascade出现在set标签中。
- 多一方的cascade出现在many-to-one标签中。
多对多的级联操作设置:
- cascade出现在set中的cascade
- set中配置了save-update,那么一方的对象保存时,会同时保存建立了关系另一方的对象。
示例:
在学生hbm的many-to-one中加上cascade="save-update":那么只保存学生对象,也可以同时保存学生对象所对应的班级对象。
public void test5() {
Configuration configure = new Configuration().configure();
SessionFactory factory = configure.buildSessionFactory();
Session session = factory.openSession();
Transaction transaction = session.beginTransaction();
//创建两个学生一个班级
Student s1=new Student();
s1.setName("林则徐");
Grade g=new Grade();
g.setCname("清朝");
//设置关系
s1.setGrade(g);
g.getStudents().add(s1);
//保存
session.save(s1);//只保存学生,可以同时保存这个学生对象所关联的班级对象
transaction.commit();
}放弃外键维护问题:
对于一对多级联操作(假设“一”一方为A,“多”一方为B),可能会产生多余SQL语句,原因是缓存区中A,B的数据都发生了变化了,使得不与快照区的数据映像相同,Hibernate默认就会对更新了的对象进行修改处理。
- 对象是新建的时候,不涉及到快照区,不会发生上述问题;
但在修改外键的时候就会发生,比如先查询出来一个A,两个B(由于处于持久态,这时候三个对象的数据会存储到缓存区和快照区),A原本仅仅与B1关联,现在增加了与B2的关联,那么这时候缓存区中的A对象发生了数据更改,B2对象也发生了更改。在提交的时候,校验缓存区和快照区的数据发现缓存区的A和B2与快照区的数据不同了,这时候hibernate会发起对A的数据更新(外键新增)以及对B2的数据更新(外键新增)。所以发起了两次外键新增,这就产生了多余的SQL语句。【而多对多中,Hibernate考虑到如果两个都有的话,会在中间表插入重复的,所以多对多不会发生这个问题(测试过!)】
解决方案:inverse是Hibernate定义的一种维护外键的属性,当这个属性设置为true时,那么设置的一方会放弃外键维护权(代表外键更新了它也不会去管理),对于一对多,通常都是在set上配置inverse=”true”,让多的一方去维护外键 。
日志
如果你已经导入前面说讲的那几个日志包了的话,那么你还需要一个log4j.properties就可以配置好你的日志功能了。Hibernate需要日志来打印一些数据。
日志包:
- slf4j-api-1.6.1.jar【这是Hibernate的日志接口,如果要扩展日志功能,需要这个接口】【这个可以在lib\spatial中找到】
- slf4j-log4j12-1.7.2.jar【我们这里要使用log4j来实现日志功能,但slf4j不能直接到log4j,它需要转换器,这个就是转换器】【这个需要你自己下载】
- log4j-1.2.6.jar【这个也需要你自己下载】
至于log4j.properties怎么写,project/etc中有一个log4j.properties,可以参照那个来写。
#
# Hibernate, Relational Persistence for Idiomatic Java
#
# License: GNU Lesser General Public License (LGPL), version 2.1 or later.
# See the lgpl.txt file in the root directory or .
#
### direct log messages to stdout ###
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### direct messages to file hibernate.log ###
#log4j.appender.file=org.apache.log4j.FileAppender
#log4j.appender.file.File=hibernate.log
#log4j.appender.file.layout=org.apache.log4j.PatternLayout
#log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### set log levels - for more verbose logging change 'info' to 'debug' ###
log4j.rootLogger=warn, stdout
#log4j.logger.org.hibernate=info
log4j.logger.org.hibernate=debug
### log HQL query parser activity
#log4j.logger.org.hibernate.hql.ast.AST=debug
### log just the SQL
#log4j.logger.org.hibernate.SQL=debug
### log JDBC bind parameters ###
log4j.logger.org.hibernate.type=info
#log4j.logger.org.hibernate.type=debug
### log schema export/update ###
log4j.logger.org.hibernate.tool.hbm2ddl=debug
### log HQL parse trees
#log4j.logger.org.hibernate.hql=debug
### log cache activity ###
#log4j.logger.org.hibernate.cache=debug
### log transaction activity
#log4j.logger.org.hibernate.transaction=debug
### log JDBC resource acquisition
#log4j.logger.org.hibernate.jdbc=debug
### enable the following line if you want to track down connection ###
### leakages when using DriverManagerConnectionProvider ###
#log4j.logger.org.hibernate.connection.DriverManagerConnectionProvider=trace 写在最后:Hibernate毕竟是一个框架,市面上的书写它都能写它几百页,在一篇博文内不可能把内容写得详尽。所以这篇博文很大程度上主要是你让你了解Hibernate,剩下的就要你自己去了解了。获取百度才是你最好的老师?
这篇博文断断续续写了三天,很多时候都是在想以什么一种方式来讲述才能更好地让大家理解。最终成了这个样子,希望能帮到大家。