- 第一步:获取语料
- 1、已有语料
- 2、网上下载、抓取语料
- 第二步:语料预处理
- 1、语料清洗
- 2、分词
- 3、词性标注
- 4、去停用词
- 三、特征工程
- 1、词袋模型(BoW)
- 2、词向量
- 第四步:特征选择
- 第五步:模型训练
- 1、模型
- 2、注意事项
- (1)过拟合
- (2)欠拟合
- (3)对于神经网络,注意梯度消失和梯度爆炸问题。
第一步:获取语料
语料,即语言材料,是构成语料库的基本单元。 所以,人们简单地用文本作为替代,并把文本中的上下文关系作为现实世界中语言的上下文关系的替代品。我们把一个文本集合称为语料库(Corpus),当有几个这样的文本集合的时候,我们称之为语料库集合(Corpora)。(定义来源:百度百科)按语料来源,我们将语料分为以下两种:
1、已有语料
纸质或者电子文本资料==》电子化==》语料库。
2、网上下载、抓取语料
国内外标准开放数据集(比如国内的中文汉语有搜狗语料、人民日报语料) 或 通过爬虫。
第二步:语料预处理
语料预处理大概会占到整个50%-70%的工作量。
基本过程: 数据清洗==》分词==》词性标注==》去停词
1、语料清洗
语料清洗:在语料中找到感兴趣的内容,将不感兴趣、视为噪音的内容清洗删除。包括:对于原始文本提取标题、摘要、正文等信息,对于爬虫,去除广告、标签、HTML、JS等代码和注释。
常见数据清洗方式:人工去重、对齐、删除和标注等,或规则提取内容、正则表达式匹配、根据词性和命名实体提取,编写脚本或代码批处理等。
2、分词
分词:将短文本和长文本处理为最小单位粒度是词或词语的过程。
常见方法:基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词方法和基于规则的分词方法,其中每种方法下面对应许多具体的方法。
难点:歧义识别 和 新词识别。 eg:“羽毛球拍卖完了”,这个可以切分成“羽毛 球拍 卖 完 了”,也可切分成“羽毛球 拍卖 完 了”==》上下文信息
3、词性标注
词性标注:对每个词或词语打词类标签,是一个经典的序列标注问题。eg:形容词、动词、名词等。有助于在后面的处理中融入更多有用的语言信息。
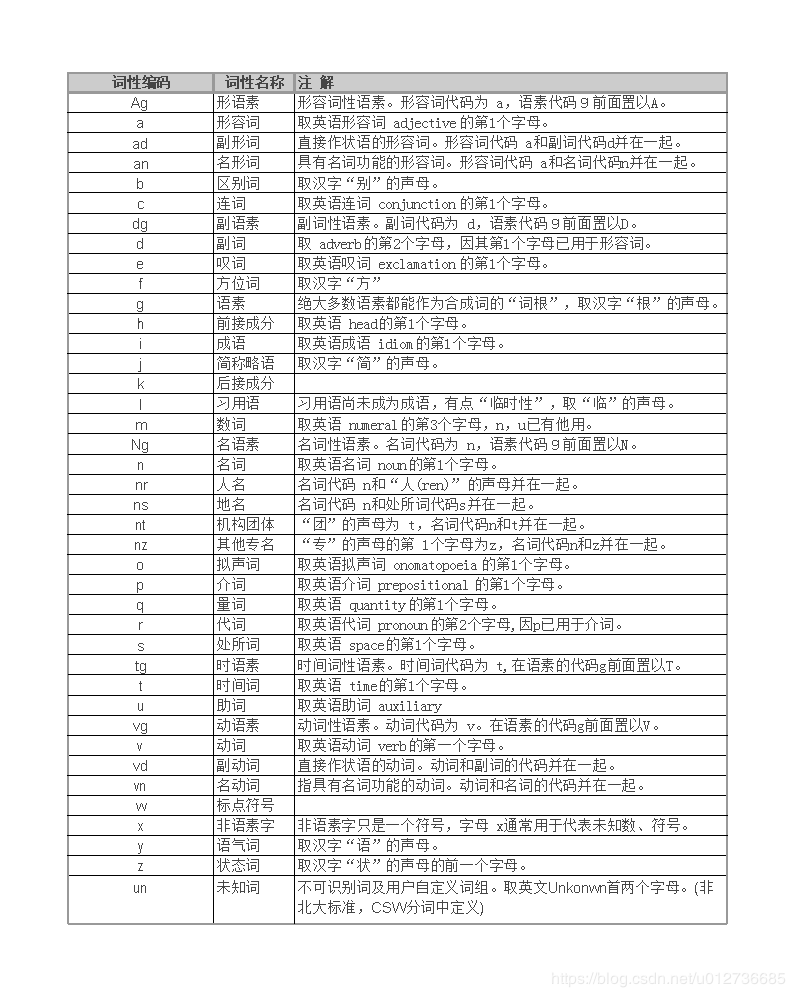
词性标注不是非必需的。比如,常见的文本分类就不用关心词性问题,但是类似情感分析、知识推理却是需要的,下图是常见的中文词性整理。
常见方法:基于规则和基于统计的方法。
- 基于统计的方法:基于最大熵的词性标注、基于统计最大概率输出词性和基于 HMM 的词性标注。
4、去停用词
停用词:对文本特征没有任何贡献的字词,eg:标点符号、语气、人称等。
注意:根据具体场景决定。eg:在情感分析中,语气词、感叹号是应该保留的,因为他们对表示语气程度、感情色彩有一定的贡献和意义。
三、特征工程
如何把分词之后的字和词语表示成计算机能够计算的类型。
思路:中文分词的字符串 ==》 向量
两种常用表示模型:
- 词袋模型(BoW)
- 词向量
1、词袋模型(BoW)
词袋模型(Bag of Word, BOW):不考虑词语原本在句子中的顺序,直接将每一个词语或者符号统一放置在一个集合(如 list),然后按照计数的方式对出现的次数进行统计。统计词频这只是最基本的方式,TF-IDF 是词袋模型的一个经典用法。
2、词向量
词向量:将字、词语转换为向量矩阵的计算模型。
常用的词表示方法:
- One-Hot:把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。eg:
[0 0 0 0 0 0 0 0 1 0 0 0 0 ... 0] - Word2Vec:其主要包含两个模型:跳字模型(Skip-Gram)和连续词袋模型(Continuous Bag of Words,简称 CBOW),以及两种高效训练的方法:负采样(Negative Sampling)和层序 Softmax(Hierarchical Softmax)。值得一提的是,Word2Vec 词向量可以较好地表达不同词之间的相似和类比关系。
- Doc2Vec
- WordRank
- FastText
第四步:特征选择
关键:如何构造好的特征向量?
==》要选择合适的、表达能力强的特征。
常见的特征选择方法:DF、 MI、 IG、 CHI、WLLR、WFO 六种。
第五步:模型训练
1、模型
对于不同的应用需求,我们使用不同的模型
- 传统的有监督和无监督等机器学习模型: KNN、SVM、Naive Bayes、决策树、GBDT、K-means 等模型;
- 深度学习模型: CNN、RNN、LSTM、 Seq2Seq、FastText、TextCNN 等。
2、注意事项
(1)过拟合
过拟合:模型学习能力太强,以至于把噪声数据的特征也学习到了,导致模型泛化能力下降,在训练集上表现很好,但是在测试集上表现很差。
常见的解决方法有:
- 增大数据的训练量;
- 增加正则化项,如 L1 正则和 L2 正则;
- 特征选取不合理,人工筛选特征和使用特征选择算法;
- 采用 Dropout 方法等。
(2)欠拟合
欠拟合:就是模型不能够很好地拟合数据,表现在模型过于简单。
常见的解决方法有:
- 添加其他特征项;
- 增加模型复杂度,比如神经网络加更多的层、线性模型通过添加多项式使模型泛化能力更强;
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。