一般来说IC老化是四种现象之一:NBTI (negative-bias temperature instability), HCI (hot carrier injection), EM (electron migration) 和TDDB (time-dependent dielectric breakdown)。其中NBTI和HCI主要导致速度的缓慢降低,EM和TDDB主要导致随机的崩溃性失效。
其中EM很好解释,金属导线中的原子被电流带着不知跑到什么地方去。这个效应一会导致导线在缺损处逐渐变细最终断裂,二会导致跑掉的原子在别处堆积生成dendrite,然后dentrite长着长着就长到别的导线上面去了,结果就是线间短路。可以看出两个效应基本一发生就没得挽救了,要对付EM主要靠预防,比如说想法不要造出缺陷来,做线的时候宽一点。但是在设计条件下,正常设计数十亿门,导线如恒河沙数,要保证这个人力有时不及。其它三个效应都是跟MOSFET原理有关。贴个我以前做的报告图示意一下:
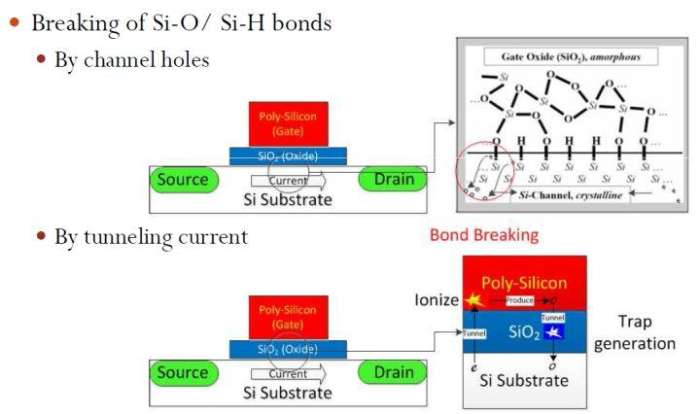
本科学过电子学的可以知道,MOSFET原理是一个门极靠静电势控制底下的导电沟道深度,电势高形成深沟道电流就大,电势低沟道消失就不导电了。稍微想深一层就知道这个门极导电底下的沟道也导电,那就必须中间有个绝缘介质把他们分开,否则就变成联通线不是晶体管了。再想深一层就知道这个绝缘介质最简单的做法是把硅氧化做二氧化硅。而行外人一般想不到的是光二氧化硅还不够,工程上二氧化硅和基板硅之间附着很差,必须加入Si-H键把二氧化硅层拴住。所以实际上介质层和硅之间有一层不是纯SiO2是SiOH。问题由此产生。VLSI等级的微观尺度使得量子效应不能忽略。沟道中流动的电子会因为量子能量涨落随机得到临时能量变成热电子然后跳到不知什么地方去,这叫隧穿效应。随手搜到一个详细解释(隧穿电流_百度百科),对物理学感兴趣的同学可以看看。不感兴趣的同学,想想MOSFET关断状态的漏电流哪来的,为啥是个幂指数函数就知道了。这事没完。前面提到有Si-H键。这个键的特点是容易破,也容易重新恢复。电子一隧穿,有几率把这个键打断,这时候就产生断键和游离氢原子。断键会使得threshold voltage提高,就是说原先0.3V就打开的门,现在需要0.35V才能打开了。这意思是说,同样加1伏电压,原先导通电流相当于0.7V时的情形,现在相当于0.65V时的情形。这就是为什么断键会使芯片变慢,因为导通电流低了,升压就慢。升压一慢,门开关就慢了,最后你的逻辑就慢了。为什么会随时间变慢呢?因为断键是随机发生,需要时间积累。另外,记住我们前面提到Si-H键可以恢复,所以基于断键的老化效应都有恢复模式。对于NBTI来说,你给他加反向电压就会进恢复模式;对于HCI来说,你不要动他就进入恢复模式。但是这两者都不可能长时间发生,所以总的来说,芯片是会逐渐老化的。为什么温度有影响呢?温度表示宏观物体微观粒子平均动能。热了,热电子就多,断键机会就大。一般民用电子产品用上十来年问题不大。汽车电子芯片,十年就差不多了。哪位有朋友开美国车的,可以观察一下。新车一般很潮,上十年以后基本上就像圣诞树一样了,一开车到处都亮。为什么加压有影响呢?同样的晶体管,供电电压越高偏移电压越高,偏移电压越高氢原子游离越快,等于压制了自发的恢复效应,自然老化就快了。为什么超频有影响呢?因为超频本质上是利用芯片厂商对这个过程无法充分把握而预留的裕量。芯片制造出来会有一个速度测试,然后芯片厂商考虑到典型使用情况,预留一个裕量,话不说太满,免得老化以后芯片达不到。打个比方,300ps芯片标3GHz,即便老化10%也还能达到;但是如果你改时钟当3.3GHz用,那稍微老化一点就达不到了。从用户的角度来看,就是亮不起来。这是为啥会老化。最后再说一下前面提到的TDDB。上文只说Si-H键会断,但是Si-O键其实也会断的,断了以后会形成一个可导电的点。随着使用随机断裂,到一定时间以后断了的Si-O键会形成一个从沟道联通门极的导电旁路,管子就击穿了。这就是TDDB。过去为了速度二氧化硅层越削越薄,这个问题很突出。但是有了High-金属门(HKMG)技术以后可以不再削薄电介质层,这个问题可能就不如想象的那么严重了。延伸阅读:Negative-bias temperature instabilityHot-carrier injection普度大学M. Alam教授的网上课件EE695A: Reliability Physics of Nanoelectronic Transistors。 特别推荐这个,Alam教授不辞劳苦不怕被盗把幻灯片都放上来了还带配音,尤其难得的是把NBTI研究历史都带入教学里面了很有故事感,数理背景hold得住的不妨看一看。
上面图中右上角黑白图取自Alam教授课件,此致感谢。
老化也叫wear out,它并不会影响计算速度,但在一定时间后会造成出错。超频伴随的高温和高电压会加速这一老化过程。因为睿频技术超过TDP不会太久,一般来说影响不大。我们先来看看CPU的寿命是如何决定的。
浴缸曲线模型(Bathtub Curve Model)
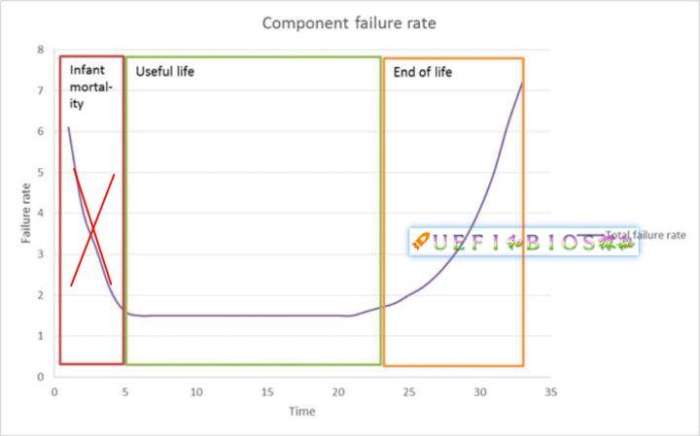
和大多数半导体设备一样,CPU的可靠性我们可以通过失效率来衡量。如果我们以时间为x轴,y轴为失效率。CPU的失效率曲线如下:

失效率曲线
蓝色的曲线叫做早期失效期(Infant Mortality),表明CPU在开始使用时,失效率很高,但随着产品工作时间的增加,失效率迅速降低。它的原因是由于制造和原材料带来的缺陷。
红色的直线叫做随机失效期(Random Failures),它是质量缺陷、材料弱点、环境和使用不当等因素引起的。它是个常数,它在CPU整个生命周期是个常数。
绿色曲线是耗损失效期(Wear-out),它在前期极低,后期开始错误后极具提高。是老化失效的原因。
综合上面三种曲线,综合失效率是紫色曲线,它呈现两头高,中间低的特征,形状像个浴缸,我们把它叫做浴缸曲线(Bathtub)模型。CPU在生命周期中的这种特点,表现在开始时故障率很高,如果没有问题,则可以稳定工作很久,到最后开始老化失效,故障率急剧升高。
Burn-in
许多人看到这里都会大吃一惊:“什么,CPU早期失效率这么高?是不是我刚买的CPU马上就要坏了?”CPU制造厂商并不希望大规模的退货发生,毕竟所有CPU至少都有3年的质保期。CPU厂商会封测期间,把CPU放入高温的环境下洗个澡(heat soaking),并加上高压。这样几个小时就相当于过了好几周。在把CPU拿出来测试,不好的淘汰掉,好的就可以进入浴缸曲线的底部稳定期,才能出货。这个工序叫做老化(Burn-in)。如图:
这样挑选后CPU直接跳过早期失效期,进入了稳定期。大家的CPU才会有3年质保。
3年之后呢,CPU会降速吗?
就像超市里的牛奶写的保质期3天,实际上5天之后大多数牛奶还是可以喝的一样。3年质保只是最小值,实际上大部分CPU用上7年以上都是没有问题的。那么多年后进入耗损失效期(Wear-out)后CPU会怎么样呢?首先,CPU的速度是恒定的,都是一个基频乘以一个比例(Ratio)出来的。基频现在Intel CPU一般是100MHz,我们用的3G CPU,Ratio就是30,下来刚好3GHz。而基频和Ratio在整个生命期是不变的,从而CPU运算速度是不变的。Wear out的后果是出错而不是降频,而很多种出错都会被CPU的错误检测发现并报告或者纠正,详情请参阅本专栏的另一篇文章计算机硬件出错了会发生什么?,如果发现出错,就是CPU开始进入失效期,以后错误会越来越多。
CPU为什么会失效?
实际上CPU失效的原因有好几个,我们今后会专门撰文介绍。它们的统一特点就是高温高电压会加速失效。如图:
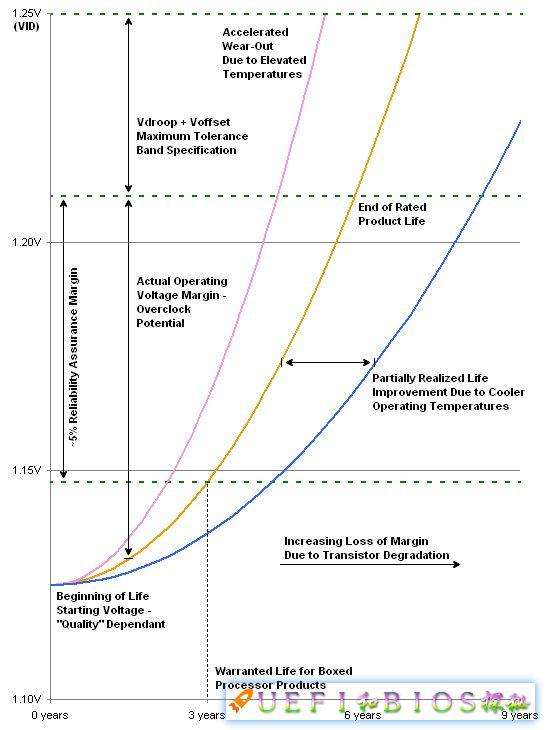
失效与电压的关系(来源anandtech)
粉色的曲线是高温曲线,黄色是正常温度,而蓝色则是配备了好的散热系统。可以看出高温和高电压严重影响了CPU的失效率。这也是为什么超频后不再享受质保的原因。
结论
CPU使用长了并不会降频,如果我们把电脑和手机变慢的罪魁祸首归咎于CPU,那真是错怪它了。那么为什么电脑手机会越用越慢呢?原因很多,软件原因是安装软件越来越多等等;硬件原因也许就是风扇脏了,转速慢了,造成温度过高而降频(CPU风扇停转后会发生什么?CPU凭什么烧不坏);或者SSD的空间满了/没有启动Trim(杂说闪存番外:手机为什么越用越卡和闪存写放大)造成速度极大降低等等。
最后强调一下CPU的Wear-out是随着使用时间进行的。如果你把电脑放上几年不动,CPU并不会老化,反倒是SSD的内容丢失了(杂说闪存番外:我们的数据存在固态硬盘上安全吗?)
温度高会造成芯片的电子迁移现象,加速芯片设备的老化。 “电子迁移”是50年代在微电子科学领域发现的一种从属现象,指因电子的流动所导致的金属原子移动的现象。因为此时流动的“物体”已经包括了金属原子,所以也有人称之为“金属迁移”。在电流密度很高的导体上,电子的流动会产生不小的动量,这种动量作用在金属原子上时,就可能使一些金属原子脱离金属表面到处流窜,结果就会导致原本光滑的金属导线的表面变得凹凸不平,造成永久性的损害。这种损害是个逐渐积累的过程,当这种“凹凸不平”多到一定程度的时候,就会造成CPU内部导线的断路与短路,而最终使得CPU报废。温度越高,电子流动所产生的作用就越大,其彻底破坏CPU内一条通路的时间就越少,即CPU的寿命也就越短,这也就是高温会缩短CPU寿命的本质原因。
因为市场和政策原因造成的为部分市场或者国家单独关闭或者打开某种功能,以及单独的SKU,不在本文讨论范围内。本文仅限于作者理解的技术原因和背后的知识。
CPU生产和制造似乎很神秘,技术含量很高。许多对电脑知识略知一二的朋友大多会知道CPU里面最重要的东西就是晶体管了,提高CPU的速度,最重要的一点说白了提高主频并塞入更多的晶体管。由于CPU实在太小,太精密,里面组成了数目相当多的晶体管,所以人手是绝对不可能完成的,只能够通过光刻工艺来进行加工的。这就是为什么一块CPU里面为什么可以数量如此之多的晶体管。
整个过程十分复杂和繁琐,所幸Intel很早就公布了一段有趣的视频,生动的展示了整个过程,我找到优酷的链接,大家可以看一下:

from sand to silicon (intel CPU 制作)
youku.com视频
整个过程充满科技感。下面我们来揭秘为什么i7,i5和部分i3是一个娘胎里长出来的。为了让读者知道我在说什么,我们先来回顾一下整个CPU制造过程。我们从中可以看到,同一品类i7,i5和部分i3出自同一个wafer线,他们最终分叉在封测阶段后期。
CPU制造过程
沙子

如果问及CPU的原料是什么,大家都会轻而易举的给出答案—是硅。这是不假,但硅又来自哪里呢?其实就是那些最不起眼的沙子。不过不是随便抓一把沙子就可以做原料的,一定要精挑细选,从中提取出最最纯净的硅原料才行。
2. 融化提纯
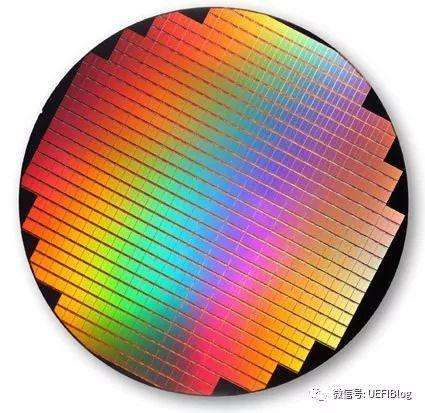
将原料进行高温溶化。整块硅原料必须高度纯净,即单晶硅。然后从高温容器中采用旋转拉伸的方式将硅原料取出,此时一个圆柱体的硅锭就产生了:

在切片后得到元晶圆:


注意这里硅锭尺寸不一,常见的有200mm,300mm直到450mm。在保留硅锭的各种特性不变的情况下增加横截面的面积是具有相当的难度的。我们会在后续文章介绍横截面的大小对于成本的影响。
3. 光刻胶(Photo Resist),溶解光刻胶、蚀刻、离子注入、电镀、铜层生长





这些步骤有很多文章介绍,我就不罗嗦了。这些都做完我们就得到了成品晶圆Wafer,接下来是我们介绍的重点。

4. Wafer测试
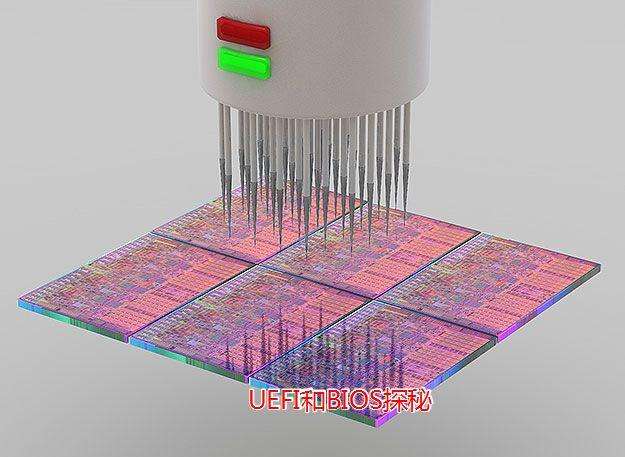
用探针基于电气特性的测试。
5. 切片
用精确控制的切片机将一个个小格切开:

终于得到了CPU的核心:Die
6. 封装(Packaging)

到这里所有的步骤都一样的,白牌CPU生产出来了:

值得注意的是这些白牌CPU都是经过基础测试并工作正常的,但这并不代表它们是合格的产品,i7,i5和部分i3的分野也在其后发生。
7. binning
通过测试设备,就是这个小白盒:

是骡子是马该拉出来遛遛了。这个步骤是封测的最后一步,它通过测量电压、频率、散热、性能、cache等等来为该CPU分类。最差当然是废品,其次有很多个SKU,远远不止i3、i5和i7这么粗枝大叶。例如i5还分有很多不同的细类,大家可以看intel的CPU,i5也有很多种,对应不同的市场segment。
接下来分拣:

然后就可以上市了!

需要binning的原因
需要指出的是Intel这么做并不是什么市场策略,而是生产工艺使然。Wafer在2)和3)步骤中会有不少缺陷产生,看下面这个图:

大圆就是晶圆,小方格就是CPU的Die。我们可以看到其中的缺陷就像撒芝麻粒,斑斑点点,而且越靠近边角越可能出现,很多小格都有(量产后不会有这么多)。良品率高,品质控制的好,芝麻粒就少。
缺陷并不可怕,只要有手段控制就行了。CPU内置了很多gate,封测时发现问题就封闭出现错误的部件,core错误就关闭core,cache错误就关部分cache,温度上升快了就出错就锁到低频,等等。所以才有了i5,i7和其中的细小sku。
接着我们来举个例子,下面是第4代酷睿(Haswell)的die:
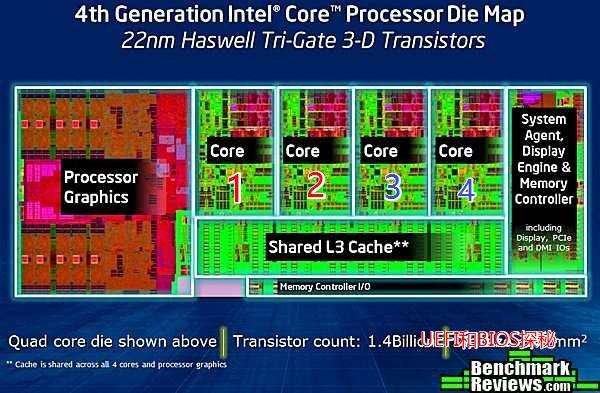
我们可以看到它主要分为几个部分:GPU、4个内核、System Agent(uncore,类似北桥)、cache和内存控制器和其他小部件。譬如我们发现core 3和4有问题,我们可以直接关闭3和4。如图:
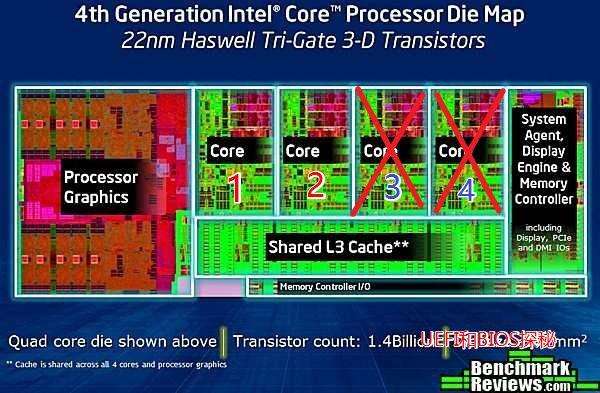
这样就得到了双core的die,接下来可能会测试速度,TDP等等。经过重重测试和筛选,binning就完成了。
结论
同代同一大类(仅面向同一个segment)i7,i5,部分i3出自一个Wafer(晶圆)产线,它们的成本是一样的。不全部生产i7并不是Intel故意搞阴谋,而是生产工艺使然。现在的做法实际上是双赢的方案:消费者和生产者都获益。消费者省钱了,生产者也减少了浪费。如果都生产i7,估计价格高到天上去了,良品率也会严重降低。
因为市场和政策原因造成的为部分市场或者国家单独关闭或者打开某种功能,以及单独的SKU,不在本文讨论范围内。本文讨论仅限于技术原因和背后的知识。
其他
最后对一些常见误解做一下澄清:
i7并不是Xeon共用一个wafer。只能说Xeon E3/E5/E7的内核部分和core系列设计几乎一样,但核外部分(uncore)却大不相同,不可能用一个晶圆。所以i7/i5/i3也不是Xeon封掉部分功能得到。同理Atom系列也不是core系列的阉割版
即使都是i7也不一定是一个wafer,die大小可能不同。面向不同的segment的die的内部是不同的,例如包不包括iris显卡等等,这不是binning能够解决的问题。
i3部分是i5的缩水版,部分i3(主要部分)是奔腾、赛扬的精选版。关键在于QDF#标明其出身。
奔腾和赛扬不一定是i3的瘦身版,部分奔腾和赛扬是ATOM产品线的高端版。
E7和E5设计不同,die大小不同,不适用本条。但E5和E7本身的Sku在此类
这种方法实际上降低了CPU的整体价格,而不是使大家吃亏。
不仅仅Intel这样,AMD也这样做。不仅仅CPU这样做,GPU也这样。这是芯片厂商的普遍做法。
CPU核心技术在设计和生产的2和3阶段,封测阶段虽有技术含量,但不是核心,国内就有封测厂。
买了i3别觉得质量差。在保修期内质量是可以保证的,我还没见过被用坏的CPU呢。CPU往往是过时淘汰掉的。
如果从单位金额的产出来看反而是i3最划算,i5适中,i7对运算密集型的用户才比较适合。

总的来说看是不是兄弟开盖一看die的大小就知道了。但开盖就不会保修了,而且大部分有焊锡,小心开盖有"奖",切忌模仿!切忌模仿!切忌模仿!
经常有朋友问我:“Intel为什么不出个100核的CPU”,“AMD单核干不过Intel,怎么不堆出个巨无霸和Intel竞争呢?”。“质不够,量来凑”似乎是个好主意,顿时感觉摩尔定律有希望了,我们相关行业又可以混几年了。
幻想美妙,现实残酷。CPU制程不变的情况下,堆砌内核必定造成CPU核心Die尺寸的增大,而其对于产品的良率有极大的影响。产品的良率影响到产品的价格,谁也不想看到自己的钱包缩水。下面我们来看一下Die的大小对于良率的影响。
Die的大小与良率(yield)
在前文(CPU制造的那些事之一:i7和i5其实是孪生兄弟!?)中我们介绍了CPU的制造过程,也顺便提到了晶圆Wafer。我们都知道CPU的制造过程,一定会用到晶圆Wafer。每个CPU内核Die都是从一个完整的Wafer上面切割下来的:

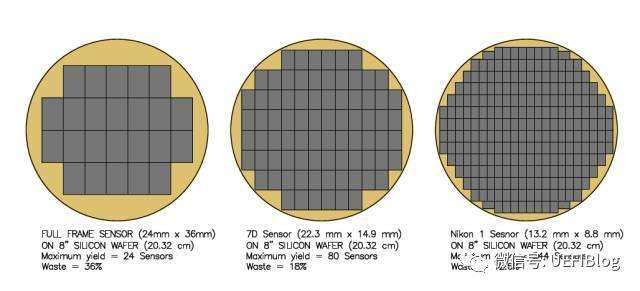
CPU成本的一个重要考量是每个Wafer能制造多少个Die,并尽量减少浪费。我们就以目前主流的300mm晶圆为例。先假设我们的晶圆出自上帝之手,没有任何缺陷(Defect)。因为Die一般是长方形或者正方形,所以圆形的Wafer边缘部分被浪费了,如下图:
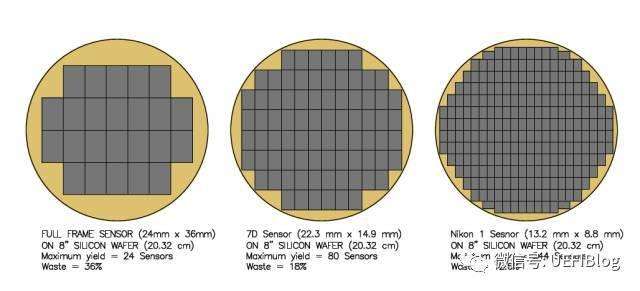
从图中我们可以看出随着Die的缩小,浪费的比例也从36%缩小成为12.6%。根据极限知识,我们知道如果Die的大小足够小,我们理论上可以100%用上所有的Wafer大小。从中我们可以看出越小的Die,浪费越小,从而降低CPU价格,对CPU生产者和消费者都是好事。
回过头来,晶圆在制造过程中总是避免不了缺陷,这些缺陷就像撒芝麻粒,分布在整个Wafer上:

如果考虑缺陷,Die的大小会严重影响良率:
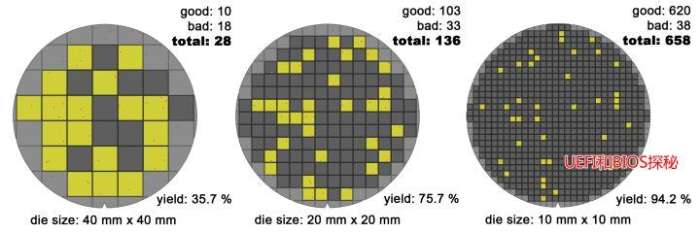
上图大家可以点开看(图比较大),其中不太清楚的红色小点是晶圆的缺陷,在Die很大时,有很大概率它的范围内会缺陷,而只要有缺陷该Die就报废了(简化处理);在Die比较小的时候,它含有缺陷的可能性就大大降低了。如图中,随着Die的减小,良率从第一个的35.7%提高到了95.2%!我们举个极端的例子,整个Wafer就一个Die,那么良率只有0%了,生产一个报废一个。谁还干这么傻的事!
制程、Die的大小与良率
22nm->14nm->10nm,每一步前进都会消耗大量的投资,芯片生产厂家还乐此不疲,有很大的原因就是制程提高了,Die也小了(或者同样大小可以塞入更多的晶体管),良率提高了,也就省钱了。制程提高还能带来另外的好处,譬如更加省电了,性能更好了等等。
但是更好的制程在最初往往会让晶圆的缺陷更容易造成严重问题,反过来会降低良率。频率也可能上不去,不得不binned到低频。同时漏电流的增加会让待机功耗增加,这也是为什么最初的14nmCPU比22nm待机功耗更高的原因。
结论
100个内核的CPU是行不通的,至少目前行不通。现在Die尺寸最大的据我所知就是Intel的Knight系列和N的人工智能板卡,成本非常高。而它们能做那么多核是因为每个核都很简单,占地很小,加起来Die的面积也在可控范围内。
也有同学好奇为什么不采用更大的Wafer呢?那将我们下一篇的内容。
补充
AMD在猪队友工艺落后Intel的前提下,又想要堆核怒怼。另辟蹊径,采取一个Package封装4个独立Die的做法,推出了EPYC服务器芯片,即不影响良率,又可以核心数目好看,可谓一举两得。

并在刚不久发布了ThreadRipper

可惜连接四个Die的片外总线终归没有片内总线效率高,在好些benchmark中败下阵来,可见没有免费的午餐。他也似乎忘记了自己在2005年双核口水大战中调侃Intel是“胶水粘”的双核,自己这次可是“拼积木”式的,为了数据好看也够“拼”的了。
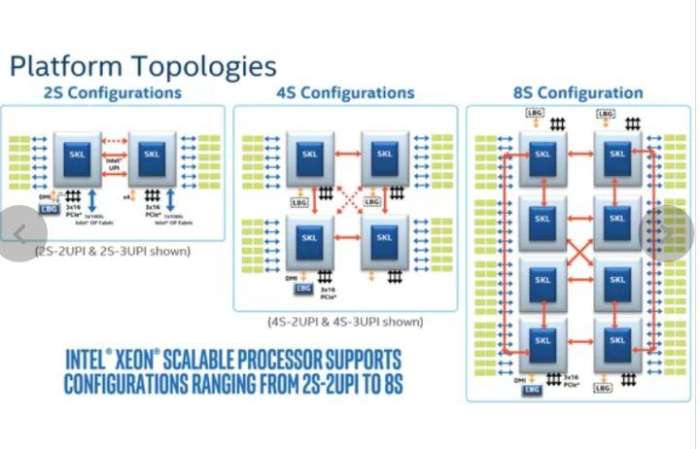
我们来看看四个Die是怎么连接的。我们来看一个双路EPYC服务器:

注意这里的双路之间互联和每个CPU Package(MCM)里面4个Zeppelin Die都是Infinity Fabric连接的,本质上Package的四个Die和四路CPU没有什么不同。是四个NUMA的Node(NUMA与UEFI)。
而Intel的Pakcage内部是一个Die, Core之间原来是Ring Bus,在Skylake后改为Mesh:
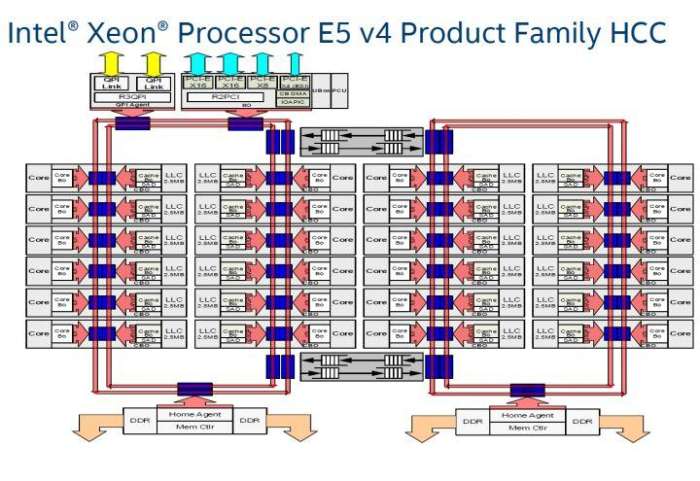
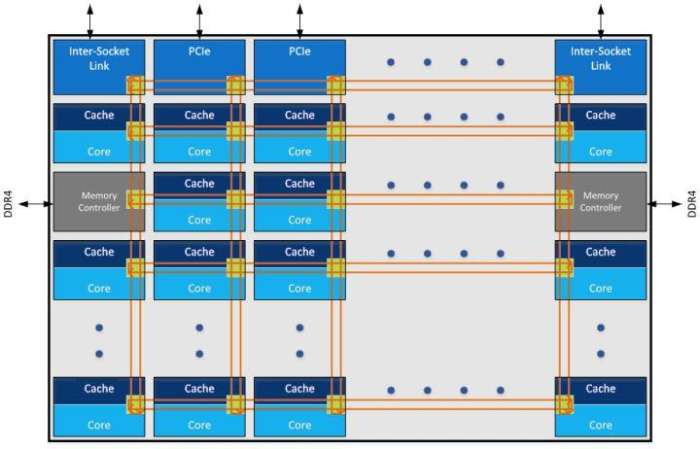
而与Infinity Fabric对应的QPI和UPI只用到了socket互联:
它们的延迟不在一个数量级上。
AMD这样做,在增加灵活性之外,主要的目的是:省钱!!AMD每个Zeppelin Die都比Intel的小,这对良品率提高很大,节约了生产费用。回首2004年,Intel雄心勃勃,宣布代码为Prescott超长流水线的奔腾4将会发布4GHz主频CPU,但最后结果是因为种种原因止步于3.8GHz。其后主频不进反退,直到到代号Haswell的酷睿4代(4790K)才真正站上4GHz,继任的broadwell, Skylake, Kabylake和Coffeelake对频率提高又变得无所作为。时间走过了十几年,为什么CPU主频不能继续提高呢?究竟发生了什么?我们是不是已经顶到频率天花板了呢?
通过前一篇文章(CPU制造的那些事之二:Die的大小和良品率),我们知道想要提高CPU的运算效能,不能够简单通过堆砌内核的方式。那么能不能简单提高CPU主频,让CPU每个内核更快的算出结果呢?为什么持CPU制程牛耳的Intel,不再勇攀主频高峰了呢?其实,瓶颈主要在于散热,我们来详细了解一下个中原因。
为什么CPU会发热
从含有1亿4000万个场效应晶体管FET的奔腾4到高达80多亿的Kabylake,Intel忠实的按照摩尔定律增加着晶体管的数目。这么多个FET随着每一次的翻转都在消耗者能量。一个FET的简单示意图如下:

当输入低电平时,CL被充电,我们假设a焦耳的电能被储存在电容中。而当输入变成高电平后,这些电能则被释放,a焦耳的能量被释放了出来。因为CL很小,这个a也十分的小,几乎可以忽略不计。但如果我们以1GHz频率翻转这个FET,则能量消耗就是a × 10^9,这就不能忽略了,再加上CPU中有几十亿个FET,消耗的能量变得相当可观。
耗能和频率的关系
从图示中,也许你可以直观的看出,能耗和频率是正相关的。这个理解很正确,实际上能耗和频率成线性相关。能耗关系公示是(参考资料2):
P代表能耗。C可以简单看作一个常数,它由制程等因素决定;V代表电压;而f就是频率了。理想情况,提高一倍频率,则能耗提高一倍。看起来并不十分严重,不是吗?但实际情况却没有这么简单。
我们这里要引入门延迟(Gate Delay)的概念。简单来说,组成CPU的FET充放电需要一定时间,这个时间就是门延迟。只有在充放电完成后采样才能保证信号的完整性。而这个充放电时间和电压负相关,即电压高,则充放电时间就短。也和制程正相关,即制程越小,充放电时间就短。让我们去除制程的干扰因素,当我们不断提高频率f后,过了某个节点,太快的翻转会造成门延迟跟不上,从而影响数字信号的完整性,从而造成错误。这也是为什么超频到某个阶段会不稳定,随机出错的原因。那么怎么办呢?聪明的你也许想到了超频中常用的办法:加压。对了,可以通过提高电压来减小门延迟,让系统重新稳定下来。
让我们回头再来看看公式,你会发现电压和功耗可不是线性相关,而是平方的关系!再乘以f,情况就更加糟糕了。我们提高频率,同时不得不提高电压,造成P的大幅提高!我们回忆一下初中学过的y=x^3的函数图:
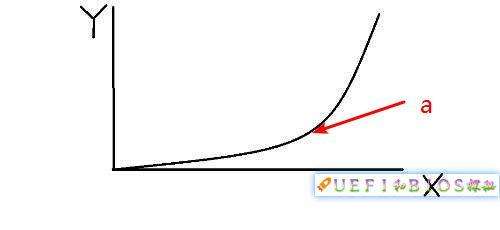
Y在经过前期缓慢的提高后在a点会开始陡峭的上升。这个a就是转折点,过了它,就划不来了。功耗和频率的关系也大抵如此,我们看两个实际的例子:
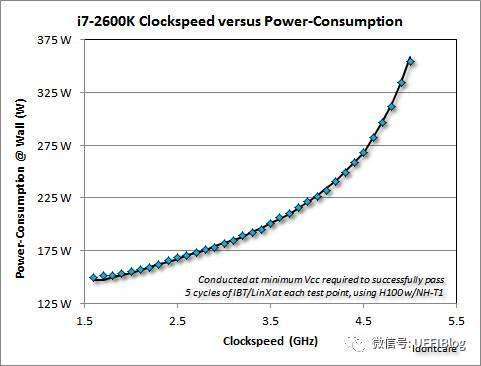
i7-2600K频率和功耗的关系

Exynos频率和功耗的关系
从ARM和X86阵营来看,他们能耗曲线是不是和幂函数图很像?
不可忽视的其他因素
现实情况比这个更复杂。实际上,上面公式里的P只是动态能耗。CPU的整体功耗还包括短路功耗和漏电功耗:
短路功耗是在FET翻转时,有个极短时间会有电子直接跑掉。它和电压、频率正相关。
漏电功耗是电子穿透MOSFET的泄漏情况,它和制程与温度有关。
综合这些,我们看一个实际的例子:
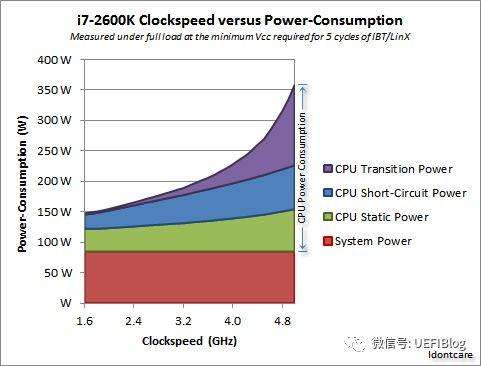
这里的Transition Power就是动态能耗,可以看出它随着频率陡峭上升;短路功耗和频率几乎呈现线性关系;而Static power就是指漏电功耗,它也上升是因为频率上升导致温度上升,从而漏电加重。
我们这里引入热密度的概念,即单位面积发出热的数量。从此图看出,随着频率的提高,各种因素综合叠加导致功耗上升严重,而芯片尺寸不变,从而热密度提高很快,现有散热设备短时间内排不出这么多热量,就会造成死机等现象(CPU风扇停转后会发生什么?CPU凭什么烧不坏)。这也是为什么超频往往需要很好的散热设备的原因(手把手来超频一:升级散热系统)。
一个脑洞
我们最后开一个脑洞:假设没有散热问题,没有门延迟,一个完美的世界里,频率有上限吗?这是个很有意思的思考。大家都知道电信号在导线里的传播速度很快,接近光速。我们这里就取光速:每秒30万公里。相信每个略微了解相对论的人都知道光速是物理极限,我们这里不讨论科幻问题。因为没有门延迟,电信号以光速传播。光速,这个数字很大,但我们的频率可是以G为单位,就是10^9,也非常大。在1GHz的情况下,电信号只能传播30cm!再远就会有相位差。10GHz的话,才能传播3cm。晶圆大小是300mm,如果我们做出个和它一样大的CPU Die,也许最高频率只有1GHz。而现在CPU的die大小差不多1cm,所以理论上30GHz是极限频率!
(这里超级简化很多条件,权作脑洞。一篇从物理极限探究CPU的文章见参考资料5)
结论
在没有强劲散热的情况下超频会减少CPU寿命,经由液氮制冷的加持,CPU的频率在极限玩家的帮助下才能挑战9GHz。这对于我们日常电脑用户来说十分遥远。而且在可以预见的未来,CPU频率因为热密度的关系并不会大幅提高,我们可能永远也看不到10GHz的硅基CPU。也许只有在抛弃硅或者转换到量子计算,CPU频率才会有翻天覆地的变化。
单纯追求高主频会让功耗急剧上升,经济上并不合算,现在CPU厂商早就放弃了单纯追求高主频,转而提高每瓦性能。实际上目前的CoffeeLake 3.8G的CPU相比奔腾4的3.8G,Benchmark跑下来效能提高了十几倍,而功耗反倒下降不少!这全拜改进架构的福。在吸取了基于netburst深度流水来提高主频,却被“誉为”高频低能的奔腾4教训后,这也是Intel等芯片制造商努力的方向。
后记
这篇文章反响很好,我接着会再接再厉,写一些CPU设计中的问题和解决方法。譬如酷睿系列相比奔腾4的netburst做了哪些架构改进,Cache一致性的问题等等,希望大家关注和喜欢!
在看过前两篇文章后,有同学在微信公众号向我提了个很好的问题:“为什么晶圆不是方的?”。是啊,圆形的wafer里面方形的Die,总是不可避免有些空间浪费了:
黑色的区域浪费有点可惜,如果是方的不是正好全部用上吗?对于这个问题,我的回答就是:“因为叫做晶圆不叫做晶方!”
嘻嘻,开个玩笑,不过严肃说起来晶圆并不是完全的圆形,你看到的晶圆是这样的:

为什么我知道的晶圆是这样的?

或是这样的:

为什么晶圆是圆形的?
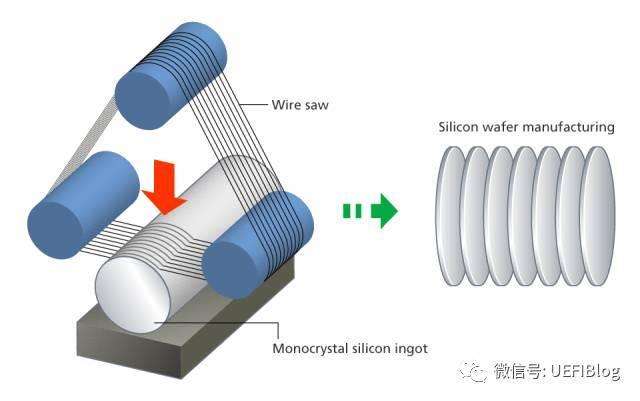
因为制作工艺决定了它是圆形的。因为提纯过后的高纯度多晶硅是在一个子晶(seed)上旋转生长出来的。多晶硅被融化后放入一个坩埚(Quartz Crucible)中,再将子晶放入坩埚中匀速转动并且向上提拉,则熔融的硅会沿着子晶向长成一个圆柱体的硅锭(ingot)。这种方法就是现在一直在用的CZ法(Czochralski),也叫单晶直拉法。如下图:

然后硅锭在经过金刚线切割变成硅片:
在经过打磨等等处理后就可以进行后续的工序了(CPU制造的那些事之一:i7和i5其实是孪生兄弟!?)
单晶直拉法工艺中的旋转提拉决定了硅锭的圆柱型,从而决定晶圆是圆形的。
为什么后来又不圆了呢?
那为啥后来又不圆了呢?其实这个中间有个过程掠过了,那就是Flat/Notch Grinning。
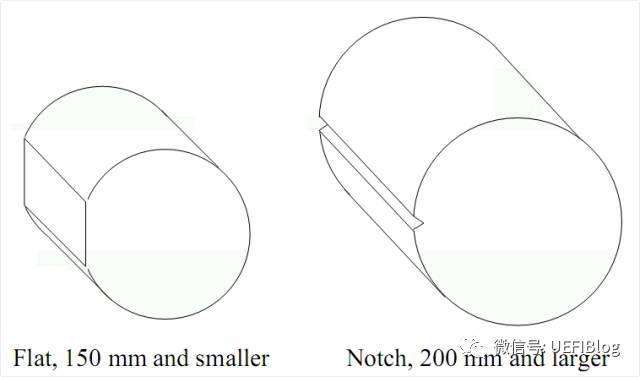
它在硅锭做出来后就要进行了。在200mm以下的硅锭上是切割一个平角,叫做Flat。在200mm(含)以上硅锭上,为了减少浪费,只裁剪个圆形小口,叫做Notch(参考资料2)。在切片后晶圆就变成了这样:

如果你仔细看我的第一个图,你也会发现它其实是有缺一个小豁口的。
为什么要这样做呢?这不是浪费吗?其实,这个小豁口因为太靠近边缘而且很小,在制作Die时是注定没有用的,这样做可以帮助后续工序确定Wafer摆放位置,为了定位,也标明了单晶生长的晶向。定位设备可以是这样:

这样切割啊,测试啊都比较方便。
结论
严格意义上所有的Wafer都不是圆形的。如果忽略Flat/Notch这些小问题,那它的圆形是工艺决定的。
后记
哈哈,彩蛋来了。其实是有方形的Wafer的:

你们知道它是干什么的吗?为什么可以是方的吗?
有人微信公众号问我,“电路为什么要铺满整个整个晶圆,边角不是没用吗?”。真是位爱思考的好同学,观察的很仔细。是的,一个晶圆周边的Die是不完整的:
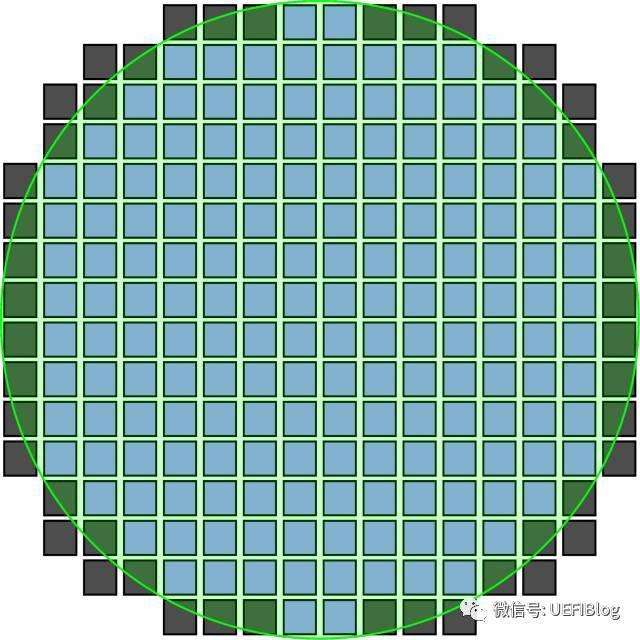
注意绿色的Die,都是不完整的。那么是不是我们应该省去这些麻烦,直接做出这样的晶圆呢?
为什么我们看Intel开发布会,公布的晶圆都是这样的呢?

Core M Wafer
原因大致有两个方面。
遮光罩Mask
光刻的重要部分遮光罩(mask)本身是方形的,它是由很多方格组成,每个方格叫做一个shot,它是曝光的最小单位。Shot包括一个或多个Die,外加一下外围测试电路。因为shot是方形的,所以每个小格也是方形的,整个mask是他们的集合。如下图:

绿色圆形是晶圆,红色内圆是可用的部分,他们之间是margin。光刻就是用Mask掩盖住需要的部分,用光去除不要的部分。
这些小方块都一样,做出Mark就是小方块的简单的重复,就像复制黏贴。并不浪费时间。而因为shot可能包括多个Die,爆出边缘shot,有可能还有部分Die是完整的。
边缘效应
还有个更重要的原因:边缘效应。如果我们不做周边的电路,会对内圈材料密度产生影响,从而影响完整的Die的良率。

忽然的密度改变会影响良率

不完整的电路可以充当缓冲
另外,小强(奇怪@不出小强同学) 补充说:在芯片制造工艺中,晶圆是不断加厚的,尤其是后段的金属和通孔制作工艺,会用到多次CMP化学机械研磨过程。 假如晶圆边沿没有图形,会造成边缘研磨速率过慢,带来的边沿和中心的高度差,在后续的研磨过程中又会影响相邻的完整芯片。 所以,即便是作为dummy pattern, 边沿的非完整shot 都需要正常曝光。
结论
不做周围的不完整Die并没有省事,反倒因为密度改变而影响内圈Die,得不偿失,在大型的Wafer上几乎没人这么做。
其他
有朋友问为啥Die不做成圆形。圆形在切割和测试时会造成很大麻烦。八角形也不利于切割:
我以前曾在英特尔的CPU封装测试工厂做过质量工程师。
CPU的寿命遵循一个失效率的统计分布曲线,如果X轴是时间,Y轴是失效率,那么这个曲线的形状象一个浴盆,两头高,中间低,事实上,我们也称这个曲线为Bathtub Curve。我们把0~30天内的比较高的失效率称为Infant Mortality(婴儿出生死亡率),最后那段越来越高的失效率是wear out fail rate,就是CPU寿终正寝的失效率。
我们希望用户拿到手里的CPU是处在当中那段失效率最低的情况,所以在封装测试工厂里有一道工序叫做Burn In(老化),把封装好的CPU放进一个大炉子里,加上电,通过高温高电压,几十分钟到几个小时的老化就相当于CPU在正常温度和电压下使用几天甚至几年的的情况。做完Burn In以后做一个测试,把在Burn In过程中失效的CPU淘汰掉,这样就相当于把Infant Mortality的失效淘汰掉了,能通过老化考验的CPU,就是失效率比较低的CPU了。
我们对于浴盆曲线当中那段最低的失效率的持续时间要求通常是7年。
一般来说ic的平均满负荷有效寿命是10万小时。
影响芯片寿命的主要在于芯片内部晶体管频繁的切换导通和关断的状态,因此带来电子流对器件的冲击,冲击导致器件在物理上出现变形损坏,或者是大电流通路长期满负荷工作,发热线路老化,电阻增大导致载流能力减弱。于是芯片就坏了。以前看过一个国家半导体的芯片分析师的论文,讲过一个芯片中,一个T字型的电路,因为长期的大电流工作,导致T字上面被电流冲击,冒头成十字和旁边的线路短路。