上一篇文章我们分析了ProcessBlock()的主要步骤,其中的checkBlockSanity()、maybeAcceptBlock()及processOrphans()等调用又涉及到更详细的验证过程,我们将逐步深入它们的实现及调用。按照ProcessBlock()的流程,我们先来分析checkBlockSanity(),它主要对区块结构进行了综合验证,保证在进一步验证之前区块本身是正确的。
//btcd/blockchain/validate.go
// checkBlockSanity performs some preliminary checks on a block to ensure it is
// sane before continuing with block processing. These checks are context free.
//
// The flags do not modify the behavior of this function directly, however they
// are needed to pass along to checkBlockHeaderSanity.
func checkBlockSanity(block *btcutil.Block, powLimit *big.Int, timeSource MedianTimeSource, flags BehaviorFlags) error {
msgBlock := block.MsgBlock()
header := &msgBlock.Header
err := checkBlockHeaderSanity(header, powLimit, timeSource, flags) (1)
if err != nil {
return err
}
// A block must have at least one transaction.
numTx := len(msgBlock.Transactions) (2)
if numTx == 0 {
return ruleError(ErrNoTransactions, "block does not contain "+
"any transactions")
}
// A block must not have more transactions than the max block payload.
if numTx > wire.MaxBlockPayload { (3)
str := fmt.Sprintf("block contains too many transactions - "+
"got %d, max %d", numTx, wire.MaxBlockPayload)
return ruleError(ErrTooManyTransactions, str)
}
// A block must not exceed the maximum allowed block payload when
// serialized.
serializedSize := msgBlock.SerializeSize()
if serializedSize > wire.MaxBlockPayload { (4)
str := fmt.Sprintf("serialized block is too big - got %d, "+
"max %d", serializedSize, wire.MaxBlockPayload)
return ruleError(ErrBlockTooBig, str)
}
// The first transaction in a block must be a coinbase.
transactions := block.Transactions()
if !IsCoinBase(transactions[0]) { (5)
return ruleError(ErrFirstTxNotCoinbase, "first transaction in "+
"block is not a coinbase")
}
// A block must not have more than one coinbase.
for i, tx := range transactions[1:] { (6)
if IsCoinBase(tx) {
str := fmt.Sprintf("block contains second coinbase at "+
"index %d", i+1)
return ruleError(ErrMultipleCoinbases, str)
}
}
// Do some preliminary checks on each transaction to ensure they are
// sane before continuing.
for _, tx := range transactions {
err := CheckTransactionSanity(tx) (7)
if err != nil {
return err
}
}
// Build merkle tree and ensure the calculated merkle root matches the
// entry in the block header. This also has the effect of caching all
// of the transaction hashes in the block to speed up future hash
// checks. Bitcoind builds the tree here and checks the merkle root
// after the following checks, but there is no reason not to check the
// merkle root matches here.
merkles := BuildMerkleTreeStore(block.Transactions()) (8)
calculatedMerkleRoot := merkles[len(merkles)-1]
if !header.MerkleRoot.IsEqual(calculatedMerkleRoot) { (9)
str := fmt.Sprintf("block merkle root is invalid - block "+
"header indicates %v, but calculated value is %v",
header.MerkleRoot, calculatedMerkleRoot)
return ruleError(ErrBadMerkleRoot, str)
}
// Check for duplicate transactions. This check will be fairly quick
// since the transaction hashes are already cached due to building the
// merkle tree above.
existingTxHashes := make(map[chainhash.Hash]struct{})
for _, tx := range transactions {
hash := tx.Hash()
if _, exists := existingTxHashes[*hash]; exists { (10)
str := fmt.Sprintf("block contains duplicate "+
"transaction %v", hash)
return ruleError(ErrDuplicateTx, str)
}
existingTxHashes[*hash] = struct{}{}
}
// The number of signature operations must be less than the maximum
// allowed per block.
totalSigOps := 0
for _, tx := range transactions { (11)
// We could potentially overflow the accumulator so check for
// overflow.
lastSigOps := totalSigOps
totalSigOps += CountSigOps(tx)
if totalSigOps < lastSigOps || totalSigOps > MaxSigOpsPerBlock {
str := fmt.Sprintf("block contains too many signature "+
"operations - got %v, max %v", totalSigOps,
MaxSigOpsPerBlock)
return ruleError(ErrTooManySigOps, str)
}
}
return nil
}
其中的验证过程为:
- 调用checkBlockHeaderSanity()对区块头结构进行验证,随后我们再分析它的实现;
- 区块头检查通过后,随后开始检查区块中的交易。首先,区块中至少包含一个交易,如代码(2)处所示;
- 随后,检查区块中交易的总个数是否超限,这里的限制是block的最大长度,即1000000字节,约为1MB。这是一个比较宽松的限制,更严格的检查在代码(4)处进行,即检查区块的总大小不能超过1MB;
- 代码(5)、(6)处检查区块中有且只有一个coinbase交易,而且是区块中的第1个交易。coinbase交易是系统奖励“矿工”的交易,它没有有效的输入UTXO,它的输入指向一个Hash为全零的交易中的第0xFFFFFFFF个输出;
- 代码(7)处调用CheckTransactionSanity()对区块中的每个交易作检查;
- 代码(8)处调用BuildMerkleTreeStore()计算区块中交易的Merkle树,随后代码(9)用计算出来的Merkle树根与区块头中的Merkle树根比较,两个值必须一致,如果不一致,交易集合可能被篡改;
- 随后,检查交易集合中是否有重复的交易,请注意,这里不是检查双重支付;
- 最后,检查区块中所有交易的解锁脚本和锁定脚本中的操作符的总数是否超过限制,当前每个区块中的脚本操作符总个数限制为20000个,超过限制的区块有可能包含恶意脚本来消耗节点计算资源;
接下来,我们来看看checkBlockHeaderSanity()的实现:
//btcd/blockchain/validate.go
// checkBlockHeaderSanity performs some preliminary checks on a block header to
// ensure it is sane before continuing with processing. These checks are
// context free.
//
// The flags do not modify the behavior of this function directly, however they
// are needed to pass along to checkProofOfWork.
func checkBlockHeaderSanity(header *wire.BlockHeader, powLimit *big.Int, timeSource MedianTimeSource, flags BehaviorFlags) error {
// Ensure the proof of work bits in the block header is in min/max range
// and the block hash is less than the target value described by the
// bits.
err := checkProofOfWork(header, powLimit, flags)
if err != nil {
return err
}
// A block timestamp must not have a greater precision than one second.
// This check is necessary because Go time.Time values support
// nanosecond precision whereas the consensus rules only apply to
// seconds and it's much nicer to deal with standard Go time values
// instead of converting to seconds everywhere.
if !header.Timestamp.Equal(time.Unix(header.Timestamp.Unix(), 0)) {
str := fmt.Sprintf("block timestamp of %v has a higher "+
"precision than one second", header.Timestamp)
return ruleError(ErrInvalidTime, str)
}
// Ensure the block time is not too far in the future.
maxTimestamp := timeSource.AdjustedTime().Add(time.Second *
MaxTimeOffsetSeconds)
if header.Timestamp.After(maxTimestamp) {
str := fmt.Sprintf("block timestamp of %v is too far in the "+
"future", header.Timestamp)
return ruleError(ErrTimeTooNew, str)
}
return nil
}
可以看到,其中主要是对区块头中的难度值和时间戳进行检查。其中主要步骤为:
- 调用checkProofOfWork进行工作量检查;
- 检查时间戳的精度为1s,从注释中知道,这是Btcd特有的检查过程;在“挖矿”前打包区块时,填入待“挖”区块头里的timestamp字段的时间值也应保证其精度为1s;
- 最后,检查区块头中时间戳是否超过当前时间2小时,请注意,这里的“当前”时间并不是节点上的时钟,而是经过与Peer同步并较正过的时间;
checkProofOfWork中主要进行了工作量证明的验证:
//btcd/blockchain/validate.go
// checkProofOfWork ensures the block header bits which indicate the target
// difficulty is in min/max range and that the block hash is less than the
// target difficulty as claimed.
//
// The flags modify the behavior of this function as follows:
// - BFNoPoWCheck: The check to ensure the block hash is less than the target
// difficulty is not performed.
func checkProofOfWork(header *wire.BlockHeader, powLimit *big.Int, flags BehaviorFlags) error {
// The target difficulty must be larger than zero.
target := CompactToBig(header.Bits) (1)
if target.Sign() <= 0 { (2)
str := fmt.Sprintf("block target difficulty of %064x is too low",
target)
return ruleError(ErrUnexpectedDifficulty, str)
}
// The target difficulty must be less than the maximum allowed.
if target.Cmp(powLimit) > 0 { (3)
str := fmt.Sprintf("block target difficulty of %064x is "+
"higher than max of %064x", target, powLimit)
return ruleError(ErrUnexpectedDifficulty, str)
}
// The block hash must be less than the claimed target unless the flag
// to avoid proof of work checks is set.
if flags&BFNoPoWCheck != BFNoPoWCheck {
// The block hash must be less than the claimed target.
hash := header.BlockHash()
hashNum := HashToBig(&hash) (4)
if hashNum.Cmp(target) > 0 { (5)
str := fmt.Sprintf("block hash of %064x is higher than "+
"expected max of %064x", hashNum, target)
return ruleError(ErrHighHash, str)
}
}
return nil
}
其主要步骤是:
- 调用CompactToBig()方法,将区块头中区块目标难度Bits转换成整数值,便于后续进行数值比较;
- 代码(2)和(3)处检测难度值是否在(0, 2^224-1)范围内;
- 随后,调用HashToBig()将区块头Hash转换成整数值,并与目标难度值进行比较,如代码(4)、(5)处所示,如果区块头Hash值大于目标难度值,则表明该区块不满足工作量证明;
区块头中目标难度的编码方式如下:

对应的计算公式是:
其中,sign指符号位对应的值(0或1),mantissa表示尾数,exponent表示指数。CompactToBig()就是根据上述编码规则和公式来计算难度值的;相应地,BigToCompact()将难度值按上述编码规则转换成32位bit序列,相关的代码读者可以自行分析。256位Hash值是按小端字节序,在HashToBig()中转换成big.Int值时,作了字节序转换。
我们可以看到,在对区块头进行检查时,主要检查了时间戳和与工作量证明相关的难度值和头部Hash。接下来,我继续分析CheckTransactionSanity(),来看看针对交易作了哪些检查。
//btcd/blockchain/validate.go
// CheckTransactionSanity performs some preliminary checks on a transaction to
// ensure it is sane. These checks are context free.
func CheckTransactionSanity(tx *btcutil.Tx) error {
// A transaction must have at least one input.
msgTx := tx.MsgTx()
if len(msgTx.TxIn) == 0 { (1)
return ruleError(ErrNoTxInputs, "transaction has no inputs")
}
// A transaction must have at least one output.
if len(msgTx.TxOut) == 0 { (2)
return ruleError(ErrNoTxOutputs, "transaction has no outputs")
}
// A transaction must not exceed the maximum allowed block payload when
// serialized.
serializedTxSize := tx.MsgTx().SerializeSize()
if serializedTxSize > wire.MaxBlockPayload { (3)
str := fmt.Sprintf("serialized transaction is too big - got "+
"%d, max %d", serializedTxSize, wire.MaxBlockPayload)
return ruleError(ErrTxTooBig, str)
}
// Ensure the transaction amounts are in range. Each transaction
// output must not be negative or more than the max allowed per
// transaction. Also, the total of all outputs must abide by the same
// restrictions. All amounts in a transaction are in a unit value known
// as a satoshi. One bitcoin is a quantity of satoshi as defined by the
// SatoshiPerBitcoin constant.
var totalSatoshi int64
for _, txOut := range msgTx.TxOut { (4)
satoshi := txOut.Value
if satoshi < 0 {
str := fmt.Sprintf("transaction output has negative "+
"value of %v", satoshi)
return ruleError(ErrBadTxOutValue, str)
}
if satoshi > btcutil.MaxSatoshi {
str := fmt.Sprintf("transaction output value of %v is "+
"higher than max allowed value of %v", satoshi,
btcutil.MaxSatoshi)
return ruleError(ErrBadTxOutValue, str)
}
// Two's complement int64 overflow guarantees that any overflow
// is detected and reported. This is impossible for Bitcoin, but
// perhaps possible if an alt increases the total money supply.
totalSatoshi += satoshi
if totalSatoshi < 0 {
str := fmt.Sprintf("total value of all transaction "+
"outputs exceeds max allowed value of %v",
btcutil.MaxSatoshi)
return ruleError(ErrBadTxOutValue, str)
}
if totalSatoshi > btcutil.MaxSatoshi {
str := fmt.Sprintf("total value of all transaction "+
"outputs is %v which is higher than max "+
"allowed value of %v", totalSatoshi,
btcutil.MaxSatoshi)
return ruleError(ErrBadTxOutValue, str)
}
}
// Check for duplicate transaction inputs.
existingTxOut := make(map[wire.OutPoint]struct{})
for _, txIn := range msgTx.TxIn { (5)
if _, exists := existingTxOut[txIn.PreviousOutPoint]; exists {
return ruleError(ErrDuplicateTxInputs, "transaction "+
"contains duplicate inputs")
}
existingTxOut[txIn.PreviousOutPoint] = struct{}{}
}
// Coinbase script length must be between min and max length.
if IsCoinBase(tx) {
slen := len(msgTx.TxIn[0].SignatureScript)
if slen < MinCoinbaseScriptLen || slen > MaxCoinbaseScriptLen { (6)
str := fmt.Sprintf("coinbase transaction script length "+
"of %d is out of range (min: %d, max: %d)",
slen, MinCoinbaseScriptLen, MaxCoinbaseScriptLen)
return ruleError(ErrBadCoinbaseScriptLen, str)
}
} else {
// Previous transaction outputs referenced by the inputs to this
// transaction must not be null.
for _, txIn := range msgTx.TxIn {
prevOut := &txIn.PreviousOutPoint
if isNullOutpoint(prevOut) { (7)
return ruleError(ErrBadTxInput, "transaction "+
"input refers to previous output that "+
"is null")
}
}
}
return nil
}
类似地,CheckTransactionSanity的输入是指向btcutil.Tx的指针类型,而不是*wire.MsgTx类型。btcutil.Tx是wire.MsgTx的封装类型,它的定义如下:
//btcd/vendor/github.com/btcsuite/btcutil/tx.go
// Tx defines a bitcoin transaction that provides easier and more efficient
// manipulation of raw transactions. It also memoizes the hash for the
// transaction on its first access so subsequent accesses don't have to repeat
// the relatively expensive hashing operations.
type Tx struct {
msgTx *wire.MsgTx // Underlying MsgTx
txHash *chainhash.Hash // Cached transaction hash
txIndex int // Position within a block or TxIndexUnknown
}
CheckTransactionSanity()的主要过程是:
- 交易中至少有一个输入,请注意,coinbase交易也包含一个输入,只不过指向一个无效的utxo;
- 交易中至少有一个输出;
- 交易的Size不能超过Block的最大Size,即1000000字节;
- 交易的每个输出的比特币数量和总的输出比特币数量须大于零而且小于2100万个比特币,即不能超过比特币总量;
- 接着,检查交易中是否有重复的输入;
- 最后,检查交易输入引用的交易是否正常,如果是Coinbase交易,由于没有有效的输入,所以其解锁脚本可以是“矿工”写入的任意字符串,但其编码后的长度应该大于等于2个字节且小于等于100个字节;如果不是coinbase交易,则其输入必须指向一个有效的交易的有效输出Utxo,即其Hash是非零Hash且输出的索引号不是0xFFFFFFFF。
Bitcoin创世区块的Coinbase交易的解锁脚本包含的就是《纽约时报》的一则报道的标题:

在对区块头和每个交易进行完整性检查后,checkBlockSanity()中还对区块头中的Merkle根进行了较验,它调用BuildMerkleTreeStore()为区块中所有交易构建Merkle树,在计算Merkle树时需要计算每个交易的Hash,它会通过util.Tx的txHash缓存下来。除了在验证区块时需要用构建Merkle树,在“挖矿”前打包区块时也要计算区块头的Merkle树根。在分析BuildMerkleTreeStore()的实现之前,我们先介绍一个Merlle树,它的结构如下图所示:
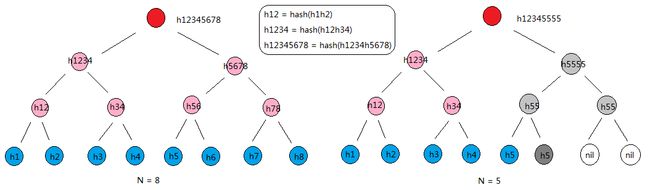
图中,蓝色节点表示叶子节点,粉色节点和浅灰色节点表示父节点,浅灰色节点的右子节点由其左子节点复制而来,红色节点表示根节点,深灰色节点表示复制的叶子节点。Merle树的叶子节点的值就是交易的Hash,每两个相邻的Hash(HASH1和HASH2),通过SHA256(SHA256(HASH1 + HASH2))计算父节点的值,其中HASH1 + HASH2表示字符连接,而不是数值相加。相邻的父节点通过相同的算法计算上一级父节点的值,直到最终计算出根节点的值。如果叶子节点不是偶数个,最右侧的叶子节点没有右兄弟节点,在计算父节点时,它要将自己复制一份作为右兄弟节点再计算父节点的值。同样地,如果父节点不是偶数个,最右的侧的父节点也将自己复制一份来计算上一级父节点。图中N=8的情形就是叶子节点是偶数的情况,N=5就是叶子节点是奇数的情况,其中N表示叶子节点的个数。特别地,N=8的情况中,由于8是2的幂,各级父节点也正好是偶数;若N是偶数,但不是2的幂,则父节点个数会出现奇数的情况,就需要将最右父节点复制。可以看出,Merkle树中任何一个叶子节点的值或者叶子节点的顺序发生变化时,根节点的值也会随之变化,也就是说,区块中的交易或者交易的顺序发生变化时,其区块头中的Merkle树根值也将发生变化,进一步导致区块头Hash发生变化,进而影响“挖矿”的结果。
//btcd/blockchain/merkle.go
func BuildMerkleTreeStore(transactions []*btcutil.Tx) []*chainhash.Hash {
// Calculate how many entries are required to hold the binary merkle
// tree as a linear array and create an array of that size.
nextPoT := nextPowerOfTwo(len(transactions)) (1)
arraySize := nextPoT*2 - 1
merkles := make([]*chainhash.Hash, arraySize) (2)
// Create the base transaction hashes and populate the array with them.
for i, tx := range transactions {
merkles[i] = tx.Hash() (3)
}
// Start the array offset after the last transaction and adjusted to the
// next power of two.
offset := nextPoT
for i := 0; i < arraySize-1; i += 2 {
switch {
// When there is no left child node, the parent is nil too.
case merkles[i] == nil: (4)
merkles[offset] = nil
// When there is no right child, the parent is generated by
// hashing the concatenation of the left child with itself.
case merkles[i+1] == nil:
newHash := HashMerkleBranches(merkles[i], merkles[i]) (5)
merkles[offset] = newHash
// The normal case sets the parent node to the double sha256
// of the concatentation of the left and right children.
default:
newHash := HashMerkleBranches(merkles[i], merkles[i+1]) (6)
merkles[offset] = newHash
}
offset++
}
return merkles
}
......
// HashMerkleBranches takes two hashes, treated as the left and right tree
// nodes, and returns the hash of their concatenation. This is a helper
// function used to aid in the generation of a merkle tree.
func HashMerkleBranches(left *chainhash.Hash, right *chainhash.Hash) *chainhash.Hash {
// Concatenate the left and right nodes.
var hash [chainhash.HashSize * 2]byte
copy(hash[:chainhash.HashSize], left[:])
copy(hash[chainhash.HashSize:], right[:])
newHash := chainhash.DoubleHashH(hash[:])
return &newHash
}
BuildMerkleTreeStore()返回的是一个slice,而不是一个树结构,即它将Merkle树存在一个线性的数组结构中。由于采用线性数组来存树结构,为了便于索引每个节点,这里将Merkle树扩展为一颗完全平衡二叉树,如图中N=5的情形所示,最右侧为nil的节点即为扩充的节点。也就是说,叶子节点的个数会被扩充为大于或者等于当前叶子节点数的最小的2的幂,如N=5时,叶子节点个数扩充为8,扩充的节点值为nil,两个nil节点的父节点仍然是nil,所以并不影响最后树根的值。
其主要步骤是:
- 根据交易个数,即叶子节点个数,计算大于或者待该值的最小2的幂;
- 计算完全平衡二叉树的节点总个数,并作为结果slice的大小,请注意,现在merkles中各元素为nil;
- 计算交易的Hash值,并按顺序填入merkles,扩充的节点值仍为nil;
- 随后,开始从头遍历merkles,并计算父节点的值,其中offset为父节点的索引值;
- 如果i节点值为nil(请注意,i为偶数,i节点总是左子节点),则它和其右边兄弟节点均是扩充节点,其父节点的值也是nil,如图中N=5情况中的nil节点;
- 如果i节点不为nil,但i+1节点为空,即右子节点为空,则将i节点的值复制一份后与i节点一起计算父节点的值,如代码(5)处所示。请注意,这里i+1节点的值仍是nil,i节点的值并没有直接拷贝给i+1节点,所以图中N=5情况中深灰色h5节点的值实际上也是nil;
- 如果i节点与i+1节点均不是扩充的节点,则直接用两者的值计算父节点的值,如代码(6)处所示;
遍历完成后,每级的父节点均会计算完成,merkles中最后一个元素即为根节点的值。对于图中N=8的情况,最后merkles中的值为: {h1, h2, h3, h4, h5, h6, h7, h8, h12, h34, h56, h78, h1234, h5678, h12345678};N=5的情况下,merkles的值为: {h1, h2, h3, h4, h5, nil, nil, nil, h12, h34, h55, nil, h1234, h5555, h12345555}。
到此,我们就介绍完了进行区块结构检查的完整过程,其中并不包括对区块上下文,即与区块链状态相关的检查,它的流程如下图所示:
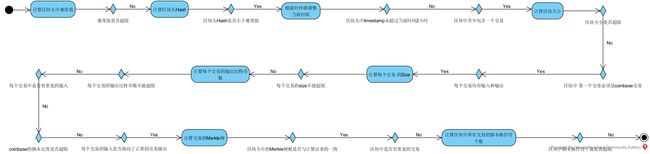
区块验证和Checkpoint工作量验证通过后,节点会调用maybeAcceptBlock()结合区块链上下文对区块作进一步验证,验证通过后才将区块写入区块链,其中涉及到更复杂的过程,我们将在下一篇文章《Btcd区块链的构建(三)》中详细介绍。
==大家可以关注我的微信公众号,后续文章将在公众号中同步更新:==
