1. Redis主从配置
1.1. 设置主从复制
Master <= Salve
10.24.6.5:6379 <= 10.24.6.7:6379

1.2. 取消主从复制
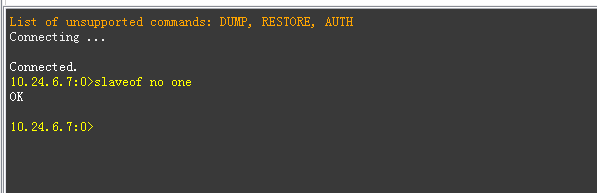
1.3. 删除所有数据
flushdb:删除这个db下的。
flushall:删除所有
2. Sentinel高可用配置
Sentinel服务器地址:
10.24.6.7
启动
Redis-sentinel sentinel.conf
或者
Redis-server sentinel.conf –sentinel
Redis服务器:
Master <= Salve
10.24.6.5:6379 <= 10.24.6.7:6379
10.24.6.4:6379
10.24.6.6:6379
2.1. Sentinel客户端:
2.1.1. Redis-DeskopMaster
2.1.2. Redis-cli
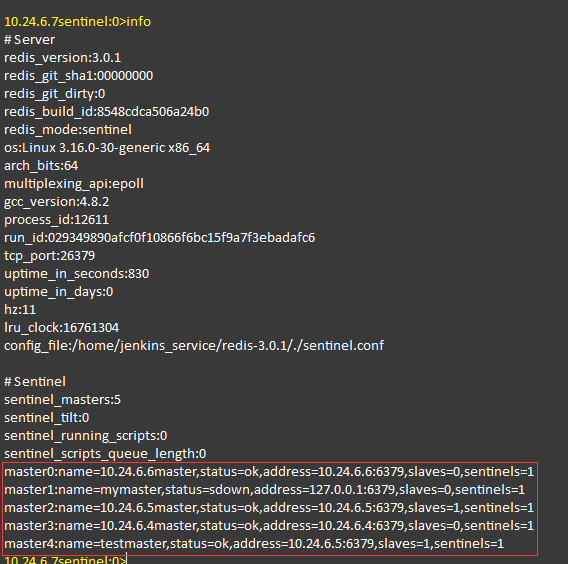
2.2. 查看Sentinel(info)
2.3. 添加redis sentinel
有两种方式,一种是通过配置文件,如何配置参考附录的sentinel.conf。这种方式主要是面向预配置的redis群集。
另外一种方式使用redis-cli做热配置:
127.0.0.1:26381> sentinel monitor mymaster 172.18.18.207 6501 1 OK
命令的格式如下:
SENTINEL MONITOR
注:quorum表示发起failover需要的sentinel数量,看sentinel群集的数量决定。
2.4. 删除redis sentinel
从sentinel中删除群集,命令: 172.18.18.207:26381> sentinel remove mymaster OK

2.5. Sentinel高可用管理
2.5.1. 查看所有master

2.5.2. 查看master的slave

2.6. Sentinel高可用客户端选择服务
from redis.sentinel import Sentinel
sentinel = Sentinel([('10.24.6.7', 26379)], socket_timeout=0.1)
master = sentinel.master_for('10.24.6.5master', socket_timeout=0.1)
print master
master.set('foo', 'bar')
print master.get('foo')
2.7. Sentinel高可用性原理
首先解释2个名词:SDOWN和ODOWN.
- SDOWN:subjectively down,直接翻译的为"主观"失效,即当前sentinel实例认为某个redis服务为"不可用"状态.
- ODOWN:objectively down,直接翻译为"客观"失效,即多个sentinel实例都认为master处于"SDOWN"状态,那么此时master将处于ODOWN,ODOWN可以简单理解为master已经被集群确定为"不可用",将会开启failover.
SDOWN适合于master和slave,但是ODOWN只会使用于master;当slave失效超过"down-after-milliseconds"后,那么所有sentinel实例都会将其标记为"SDOWN".
1) SDOWN与ODOWN转换过程:
- 每个sentinel实例在启动后,都会和已知的slaves/master以及其他sentinels建立TCP连接,并周期性发送PING(默认为1秒)
- 在交互中,如果redis-server无法在"down-after-milliseconds"时间内响应或者响应错误信息,都会被认为此redis-server处于SDOWN状态.
- 如果2)中SDOWN的server为master,那么此时sentinel实例将会向其他sentinel间歇性(一秒)发送"is-master-down-by-addr
"指令并获取响应信息,如果足够多的sentinel实例检测到master处于SDOWN,那么此时当前sentinel实例标记master为ODOWN...其他sentinel实例做同样的交互操作.配置项"sentinel monitor ",如果检测到master处于SDOWN状态的slave个数达到 ,那么此时此sentinel实例将会认为master处于ODOWN. - 每个sentinel实例将会间歇性(10秒)向master和slaves发送"INFO"指令,如果master失效且没有新master选出时,每1秒发送一次"INFO";"INFO"的主要目的就是获取并确认当前集群环境中slaves和master的存活情况.
- 经过上述过程后,所有的sentinel对master失效达成一致后,开始failover.
2) Sentinel与slaves"自动发现"机制:
在sentinel的配置文件中(local-sentinel.conf),都指定了port,此port就是sentinel实例侦听其他sentinel实例建立链接的端口.在集群稳定后,最终会每个sentinel实例之间都会建立一个tcp链接,此链接中发送"PING"以及类似于"is-master-down-by-addr"指令集,可用用来检测其他sentinel实例的有效性以及"ODOWN"和"failover"过程中信息的交互.
在sentinel之间建立连接之前,sentinel将会尽力和配置文件中指定的master建立连接.sentinel与master的连接中的通信主要是基于pub/sub来发布和接收信息,发布的信息内容包括当前sentinel实例的侦听端口:
- +sentinel sentinel 127.0.0.1:26579 127.0.0.1 26579 ....
发布的主题名称为"__sentinel__:hello";同时sentinel实例也是"订阅"此主题,以获得其他sentinel实例的信息.由此可见,环境首次构建时,在默认master存活的情况下,所有的sentinel实例可以通过pub/sub即可获得所有的sentinel信息,此后每个sentinel实例即可以根据+sentinel信息中的"ip+port"和其他sentinel逐个建立tcp连接即可.不过需要提醒的是,每个sentinel实例均会间歇性(5秒)向"__sentinel__:hello"主题中发布自己的ip+port,目的就是让后续加入集群的sentinel实例也能或得到自己的信息.
根据上文,我们知道在master有效的情况下,即可通过"INFO"指令获得当前master中已有的slave列表;此后任何slave加入集群,master都会向"主题中"发布"+slave 127.0.0.1:6579 ..",那么所有的sentinel也将立即获得slave信息,并和slave建立链接并通过PING检测其存活性.
补充一下,每个sentinel实例都会保存其他sentinel实例的列表以及现存的master/slaves列表,各自的列表中不会有重复的信息(不可能出现多个tcp连接),对于sentinel将使用ip+port做唯一性标记,对于master/slaver将使用runid做唯一性标记,其中redis-server的runid在每次启动时都不同.
3) Leader选举:
其实在sentinels故障转移中,仍然需要一个“Leader”来调度整个过程:master的选举以及slave的重配置和同步。当集群中有多个sentinel实例时,如何选举其中一个sentinel为leader呢?
在配置文件中“can-failover”“quorum”参数,以及“is-master-down-by-addr”指令配合来完成整个过程。
A) “can-failover”用来表明当前sentinel是否可以参与“failover”过程,如果为“YES”则表明它将有能力参与“Leader”的选举,否则它将作为“Observer”,observer参与leader选举投票但不能被选举;
B) “quorum”不仅用来控制master ODOWN状态确认,同时还用来选举leader时最小“赞同票”数;
C) “is-master-down-by-addr”,在上文中以及提到,它可以用来检测“ip + port”的master是否已经处于SDOWN状态,不过此指令不仅能够获得master是否处于SDOWN,同时它还额外的返回当前sentinel本地“投票选举”的Leader信息(runid);
每个sentinel实例都持有其他的sentinels信息,在Leader选举过程中(当为leader的sentinel实例失效时,有可能master server并没失效,注意分开理解),sentinel实例将从所有的sentinels集合中去除“can-failover = no”和状态为SDOWN的sentinels,在剩余的sentinels列表中按照runid按照“字典”顺序排序后,取出runid最小的sentinel实例,并将它“投票选举”为Leader,并在其他sentinel发送的“is-master-down-by-addr”指令时将推选的runid追加到响应中。每个sentinel实例都会检测“is-master-down-by-addr”的响应结果,如果“投票选举”的leader为自己,且状态正常的sentinels实例中,“赞同者”的自己的sentinel个数不小于(>=) 50% + 1,且不小与
在sentinel.conf文件中,我们期望有足够多的sentinel实例配置“can-failover yes”,这样能够确保当leader失效时,能够选举某个sentinel为leader,以便进行failover。如果leader无法产生,比如较少的sentinels实例有效,那么failover过程将无法继续.
4) failover过程:
在Leader触发failover之前,首先wait数秒(随即0~5),以便让其他sentinel实例准备和调整(有可能多个leader??),如果一切正常,那么leader就需要开始将一个salve提升为master,此slave必须为状态良好(不能处于SDOWN/ODOWN状态)且权重值最低(redis.conf中)的,当master身份被确认后,开始failover
A)“+failover-triggered”: Leader开始进行failover,此后紧跟着“+failover-state-wait-start”,wait数秒。
B)“+failover-state-select-slave”: Leader开始查找合适的slave
C)“+selected-slave”: 已经找到合适的slave
D) “+failover-state-sen-slaveof-noone”: Leader向slave发送“slaveof no one”指令,此时slave已经完成角色转换,此slave即为master
E) “+failover-state-wait-promotition”: 等待其他sentinel确认slave
F)“+promoted-slave”:确认成功
G)“+failover-state-reconf-slaves”: 开始对slaves进行reconfig操作。
H)“+slave-reconf-sent”:向指定的slave发送“slaveof”指令,告知此slave跟随新的master
I)“+slave-reconf-inprog”: 此slave正在执行slaveof + SYNC过程,如过slave收到“+slave-reconf-sent”之后将会执行slaveof操作。
J)“+slave-reconf-done”: 此slave同步完成,此后leader可以继续下一个slave的reconfig操作。循环G)
K)“+failover-end”: 故障转移结束
L)“+switch-master”:故障转移成功后,各个sentinel实例开始监控新的master。
Sentinel.conf详解
- ##sentinel实例之间的通讯端口
- ##redis-0
- port 26379
- ##sentinel需要监控的master信息:
- ##
应该小于集群中slave的个数,只有当至少 个sentinel实例提交"master失效" - ##才会认为master为O_DWON("客观"失效)
- sentinel monitor def_master 127.0.0.1 6379 2
- sentinel auth-pass def_master 012_345^678-90
- ##master被当前sentinel实例认定为“失效”的间隔时间
- ##如果当前sentinel与master直接的通讯中,在指定时间内没有响应或者响应错误代码,那么
- ##当前sentinel就认为master失效(SDOWN,“主观”失效)
- ##
- ##默认为30秒
- sentinel down-after-milliseconds def_master 30000
- ##当前sentinel实例是否允许实施“failover”(故障转移)
- ##no表示当前sentinel为“观察者”(只参与"投票".不参与实施failover),
- ##全局中至少有一个为yes
- sentinel can-failover def_master yes
- ##当新master产生时,同时进行“slaveof”到新master并进行“SYNC”的slave个数。
- ##默认为1,建议保持默认值
- ##在salve执行salveof与同步时,将会终止客户端请求。
- ##此值较大,意味着“集群”终止客户端请求的时间总和和较大。
- ##此值较小,意味着“集群”在故障转移期间,多个salve向客户端提供服务时仍然使用旧数据。
- sentinel parallel-syncs def_master 1
- ##failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,
- ##当前sentinel将会认为此次failoer失败。
- sentinel failover-timeout def_master 900000
- ##当failover时,可以指定一个“通知”脚本用来告知系统管理员,当前集群的情况。
- ##脚本被允许执行的最大时间为60秒,如果超时,脚本将会被终止(KILL)
- ##脚本执行的结果:
- ## 1 -> 稍后重试,最大重试次数为10;
- ## 2 -> 执行结束,无需重试
- ##sentinel notification-script mymaster /var/redis/notify.sh
- ##failover之后重配置客户端,执行脚本时会传递大量参数,请参考相关文档
- # sentinel client-reconfig-script