由于忙于硕士毕业相关事宜,非常久没有更新博客,现在回来更新博客,第一篇还是资源整理类。
1 Coding:
1.USGS EROS数据分发系统的API接口,非官方API。
espa api
2.R语言包Taipan,Taipan是一种在准备分析时注释图像的工具。
taipan
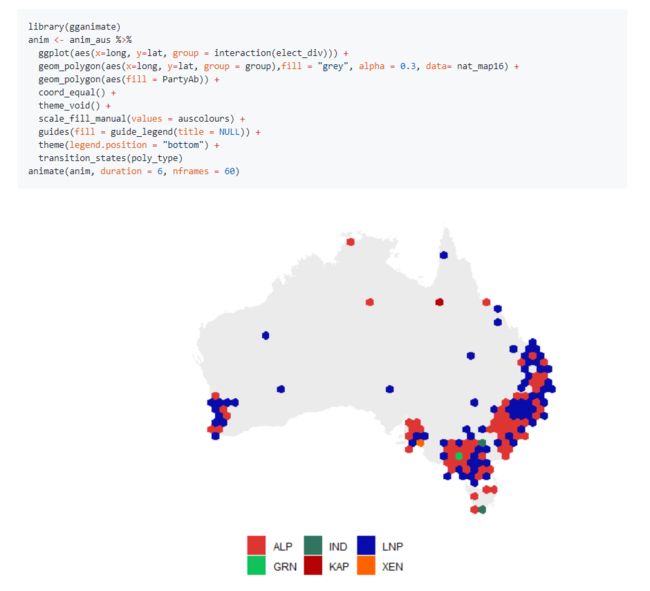
3.R语言包sugarbag,创建用于可视化地理空间数据的镶嵌六边形地图。 定位相同尺寸的六边形以最好地保持各个区域和最近焦点之间的关系,并最小化与其实际位置的距离。 该方法允许以相同的视觉比例对所有区域进行比较,并提供了对制图的替代方案。
sugarbag
4.R的docker镜像。
r docker
5.适用于Python的高级应用和仪表板解决方案,Panel提供了一些工具,可以轻松地将小部件,绘图,表格和其他可查看的对象和控件组合到控制面板,应用程序和仪表板中。 Panel使用来自Bokeh,Matplotlib,HoloViews和其他Python绘图库的可视化,使它们可以单独查看,也可以与控制它们的交互式小部件结合使用。 Panel在Jupyter笔记本中同样运行良好,用于创建快速数据探索工具,或作为独立部署的应用程序和仪表板,并允许您根据需要轻松切换这些上下文。
panel

6.无人机摄影测量和卷积神经网络增强自动化和准确的鲸类物种识别,发表于Methods in Ecology and Evolution的论文代码、docker镜像与数据。
cetacean photogram
7.R语言包encryptedRmd,目标是提供密码保护markdown html文档的功能,并安全地与他人共享。 解密文件所需的代码被捆绑到导出的html文件中,这使得生成的文件完全自包含。
encryptedRmd
8.本教程介绍了ncar数据处理工具Cheyenne/DAV Python环境的安装和设置。
ncar pangeo tutorial
9.R语言包validate,可以非常轻松地检查数据是否符合您对领域知识的期望。 它的工作原理是允许您定义独立于代码或数据集的数据验证规则。 接下来,您可以使用规则来对抗数据集或其各种版本。 结果可以汇总,绘图等。
validate
10.数据工程师秘籍。
Cookbook
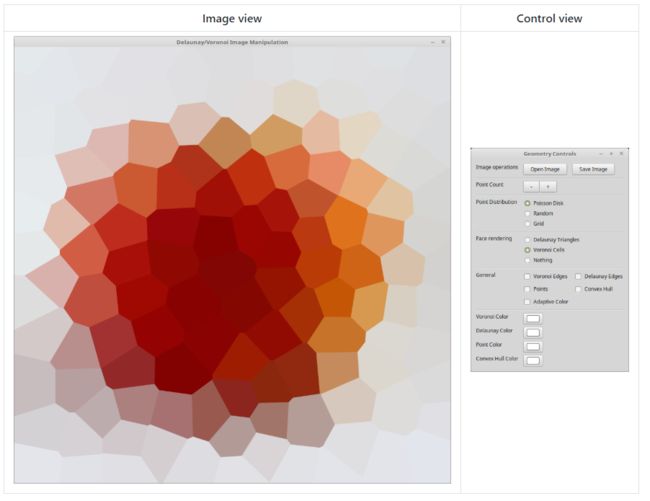
11.Voronoi/Delaunay图像处理,该项目实现了一个小型,轻量级的工具,用于使用Voronoi / Delaunay数据结构进行实时图像处理。
Voronoi Image Manipulation
12.GeoNode是一个开源平台,可以促进地理空间数据的创建,共享和协作使用。
geonode
13.一个功能齐全的pythonic库,用于表示和使用四元数组。
pyquaternion
14.dataretrieval是USGS-R的dataRetrieval包的Python替代方案,用于直接从Web服务获取USGS或EPA水质数据,流数据和元数据。 请注意,dataretrieval是R包的替代品,而不是端口,因为它重现了R包的功能,但其组织和功能通常不同。 Python版本还扩展了其前身,包括从NWIS和STORET以外的各种Web门户中提取数据的功能。如果有一个您希望与之合作的水文或环境数据门户,请将其作为一个问题提出。以下是如何使用dataretrievel从国家水信息系统(NWIS)反演数据的示例。
dataretrieval
15.用于分析USEPA GitHub组织存储库的使用的代码。
epa github org analysis
16.免费编程书籍。
free programming books
17.机器学习,统计和人工智能研究相关的幻灯片,纸质笔记,课堂笔记,博客文章。
csinva.github.io
18.缅因湾鱼类生物量的生态预测。
maine fish
19.plotly的R书籍。
plotly book
20.使用Kaggle内核立即运行任何Jupyter笔记本。
kernel run
21.火星坐标(GCJ-02, BD-09, WGS)转换工具,支持命令行和Python API,支持点、线、面,支持GeoJson、shapefile...
coord convert
22.R语言包dplyr,数据处理清洗神器。
dplyr
23.edaviz - 用于Jupyter Notebook或Jupyter Lab中的探索性数据分析和可视化的Python库,edaviz是一个用于Jupyter Notebook和Jupyter Lab中的数据探索和可视化的python库。 edaviz为您提供开箱即用的默认可视化。
edaviz
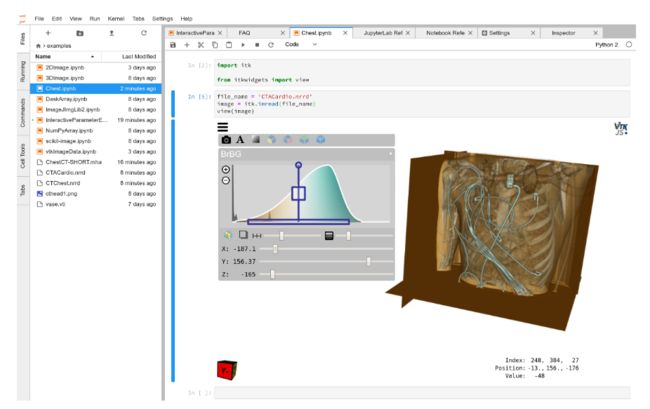
24.交互式Jupyter小部件可以在2D和3D中可视化图像,点集和网格。
itkwidgets
25.R语言包rasterFunctions,R语言包raster的自定义处理函数。它们扩展了R包栅格中的函数。
rasterFunctions
26.在LaTeX中绘制贝叶斯网络,图形模型和技术框架。
awesome latex drawing

27.Gensim是一个Python库,用于主题建模,文档索引和大型语料库的相似性检索。 目标受众是自然语言处理(NLP)和信息检索(IR)社区。
gensim
28.R语言包chromote,Chromote是Chrome Devtools协议的R实现。 它适用于Chrome,Chromium,Opera,Vivaldi和其他基于Chromium的浏览器。 默认情况下,它使用谷歌浏览器(必须已安装在系统上)。
chromote
29.R语言包bench,目标是对代码进行基准测试,跟踪执行时间,内存分配和垃圾收集。
bench
30.Python + NumPy程序的可组合转换:区分,矢量化,JIT到GPU / TPU等。
jax
31.geosnap是一个开源的Python3软件包,用于探索,建模和可视化邻域动态。geosnap旨在帮助填补这些空白。 它提供了一套工具,用于创建社会空间数据集,将这些数据集协调为一致的时间 - 静态边界集,并使用经典和空间统计方法对邻域变化进行建模。
geosnap
32.一个轻量的工具集合。
MikuTools
33.GDAL的js版本。
gdaljs
34.浏览器中的GDAL Javascript包装器。
loam
35.关于如何写学术论文review的仓库。
reviews
36.R语言包factory,目标是使函数的构建更加简单,而无需用户学习rlang包。
factory
37.Cmder是一个软件包,由于在Windows上缺少可用的控制台模拟器而完全失败。 它基于ConEmu的主要配置大修,配备Monokai配色方案,惊人的碰撞(通过碰撞完成进一步增强)和自定义提示布局。
cmder
38.可用于Shiny和Rmarkdown的titian图标。
titanicon
39.R语言包dashR,用于创建响应式Web应用程序的Dash生态系统的R接口。
dashR
40.R语言包dtplyr,dtplyr为data.table提供了一个dplyr后端。 dtplyr的目标是允许您编写自动转换为等效但通常更快的data.table代码的dplyr代码。
dtplyr
2 Paper:
1.Globally analysing spatiotemporal trends of anthropogenic PM2.5 concentration and population's PM2.5 exposure from 1998 to 2016/从1998年到2016年人为PM2.5浓度和人口PM2.5暴露的时空趋势全球分析
颗粒物(PM)形式的空气污染正在成为全球范围内对人类健康的最大威胁之一。本文首先提出了一种贝叶斯时空等级分段回归模型(BSTHPRM),它可以自适应地检测局部趋势的转变,从而解释空间相关性。通过提出的BSTHPRM研究了1998年至2016年全球大陆近似人为PM2.5去除天然尘埃(PM2.5 No尘)浓度和相应人群PM2.5 No粉尘暴露(PPM2.5E)的时空趋势。 PM2.5 No尘埃污染严重的地区的总面积,其PM2.5 No污染对全球大陆总体水平的空间相对大小在1.89和14.68之间,占全球陆地面积的13.4%,相应的暴露人口占全球总人口的56.0%。全球PM2.5 No污染的空间异质性从1998年到2016年普遍增加。随着PM2.5 No浓度趋势的增加,热点,暖点和冷点的面积最初收缩,然后扩大。全球大陆PM2.5 NoDust浓度和PPM2.5E的局部趋势可以使用BSTHPRM分为三个变化阶段,早期,中期和后期。 PM2.5 No浓度和PPM2.5E呈下降趋势的区域面积比例在中期比早期和后期更大。印度北部和中国东部和南部两个较高PM2.5 No污染区PM2.5 No浓度和PPM2.5E的局部趋势在早期增加,然后在中期减少。在后期(近年),印度北部呈增长趋势;尽管如此,中国东部和南部的后续下降趋势仍然存在。在前两个阶段,欧洲一半以上的地区经历了PM2.5 NoDust浓度和PPM2.5E的下降趋势;后来,欧洲一半以上的地区在后期呈现出越来越大的趋势。北美和南美经历了与欧洲相似的PPM2.5E局部趋势。在研究期间,非洲的PPM2.5E趋势普遍增加。发表于EI上的PM2.5浓度分析与人口暴露的研究。采用了一个贝叶斯的时空模型用于PM2.5空间分布建模,贝叶斯时空统计是近年来时空统计方向重要建模手段,这篇文章也是一个很有意思的研究。
2.Testing the Efficiency of Using High-Resolution Data From GF-1 in Land Cover Classifications/在土地覆盖分类中测试从GF-1使用高分辨率数据的效率
高分辨率遥感在研究地球表层变化方面发挥着重要作用。新轨道的中国GF-1卫星旨在以区域尺度观测地球表层;但是,卫星效率需要进一步调查。在本文中,通过考虑补充信息和不同的土地覆盖分类方法,测试了使用GF-1 01卫星图像监测复杂表面的效率。我们的工作表明,GF-1卫星观测可以有效地探测土地覆盖碎片。当应用支持向量机方法时,基于多源数据的总体分类精度达到90.5%。在分类图像中有效地减少了“盐和胡椒现象”。这些结果还表明GF-1图像分类的准确性优于使用Landsat 8和Sentinel-2A图像的相同方法的结果,总体分类准确度增加了23.6%和13.6%。我们的研究表明,GF-1卫星观测适用于复杂陆地表面的土地覆盖研究。这种方法可以使各种相关领域受益,例如土地资源调查,生态评估,环境评估等。探究了GF-1国产卫星在陆地表层对地观测的应用。GF-1卫星有效提升原本卫星监测精度,是一个很重要的卫星数据来源。
3.An Improved Single-Channel Polar Region Ice Surface Temperature Retrieval Algorithm Using Landsat-8 Data/利用Landsat-8数据改进单通道极区冰面温度反演算法
冰面温度(IST)是研究极地冰盖和冰架的关键参数。在本研究中,提出了一种基于辐射传输方程的改进单通道(ISC)算法,用于从Landsat-8频段10数据中进行IST检索。提出的ISC算法的主要步骤包括:1)通过回归大气水汽含量和有效平均大气温度来模拟大气辐射参数; 2)使用普朗克方程计算IST,而不是使用泰勒近似; 3)实现IST计算的迭代方案。定量估计了使用泰勒近似和大气辐射参数模拟的误差。还进行了ISC对大气水汽含量,亮度温度和卫星观测中可能的误差的灵敏度分析。灵敏度分析结果表明,该算法对大气水汽含量具有较强的鲁棒性,但对热红外传感器的校准精度较为敏感。使用模拟方法进行的验证显示,ISC的IST变异性优于原始SC算法[均方根误差(RMSEs)分别为0.3252和0.7176 K]。与格陵兰68个自动气象站数据和南极25个数据的近地面气温相比,ISC算法的偏差和RMSE再次优于SC算法。发现中等分辨率成像光谱仪(MODIS)的IST与SC和ISC算法的结果相比被低估了。提出了从Landsat-8图像样本得到的IST空间分布图。还提出了所提出的ISC算法中的每个步骤的基本原理,以便这可以为结果的真实性提供进一步的支持。发表在IEEE TGRS顶刊上的温度遥感反演算法,改进Landsat-8的单通道温度反演算法,非常不错的研究。
4.Impacts of air pollutants from rural Chinese households under the rapid residential energy transition/家庭能源快速转型下中国农村家庭大气污染物的影响
家庭固体燃料的使用构成了大量的空气污染,但在过去三十年中逐渐被其他清洁能源所取代。 在这里,作者调查了农村家庭对环境PM2.5污染的贡献以及由此产生的气候强迫和健康影响,并发现农村家庭使用的剩余大量固体燃料仍然是环境空气污染的主要原因,尽管 由于清洁的能源转换,其污染物排放量减少以及对PM2.5的相对贡献。发表于Nature Communication的文章,来自陶澍院士团队的成果,分析农村家庭燃煤对于PM2.5和气候强迫的影响。事实上PM2.5、气溶胶与气候有着密不可分的联系,这是一个非常复杂的海陆气耦合综合问题,未来的研究应当关注PM2.5与气候强迫的一些研究。
5.Quantitative estimates of collective geo-tagged human activities in response to typhoon Hato using location-aware big data/使用位置感知大数据定量估计对台风Hato响应的集体地理标记人类活动
来自社交媒体的位置感知大数据已广泛用于定量描述自然灾害和灾害造成的损失。目前尚不清楚人类活动如何共同应对灾难。在这项研究中,我们使用聚合位置请求数据检查了在多个空间尺度上响应台风哈托的集体人类活动。我们提出了一种多级突变检测(MACD)方法框架,用于检测和表征响应Typhoon Hato的位置请求的突然变化。结果表明,在网格水平上,大多数异常网格位于台风轨迹周围53公里半径范围内。在城市一级,人类活动恢复持续时间(平均230小时)存在显着的空间差异。在地方一级,突然的位置要求变化的绝对幅度与台风引起的经济损失和受影响的人口密切相关。基于社交媒体大数据与灾害应急方面的研究,分析了不同尺度下的影响,利用社交媒体数据定量估计人类活动将为防灾减灾提供重要的数据支撑。
6.Committed emissions from existing energy infrastructure jeopardize 1.5 °C climate target/现有能源基础设施的承诺排放危及1.5°C气候目标
到本世纪中叶(2050年),净人为二氧化碳(CO2)排放必须达到零,以将全球平均温度稳定在国际努力所针对的水平1-5。然而,化石燃料能源基础设施的持续扩张意味着已经“承诺”的未来二氧化碳排放。在这里,我们使用2018年当前化石燃料燃烧能源基础设施的详细数据集来估算“承诺的”二氧化碳排放的区域和部门模式,此类排放对假定的运行寿命和时间表的敏感性,以及相关基础设施的经济价值。我们估计,如果按历史运营,现有基础设施将排放大约658亿吨(Gt)的二氧化碳(取决于假定的寿命和利用率,从226到1,479 Gt二氧化碳)。预计这些排放中有一半以上来自电力部门,中国,美国和欧盟28国的基础设施分别约占总数的41%,9%和7%。如果建成,拟议的发电厂(计划,允许或正在建设中)将排放大约额外的188(范围37-427)Gt CO2。如果将平均变暖限制在1.5°C,概率为50-66%(420-580 Gt CO2),现有和拟议的能源基础设施(约846 Gt CO2)的承诺排放量将超过整个剩余的碳预算。如果将平均变暖限制在2°C以下(1,170-1,500 Gt CO2)5,则可能是剩余碳预算的三分之二。剩余的碳预算估计是多种多样的,细微差别,取决于气候目标和大规模负排放的可用性。尽管如此,我们的排放估算表明,很少或根本没有额外的二氧化碳排放基础设施,为了符合“巴黎协定”,可能需要早于历史基础设施退役(或采用碳捕集与封存技术的改造)。据每吨承诺排放的资产价值,我们估计,如果非排放替代技术可用且价格合理,那么最具成本效益的过早基础设施退役将在电力和工业部门进行。Nature上的一篇文章,探究能源基础设施数量、排放规模对于巴黎协定减排目标的影响,这些结果表明目前具有非常大的减排压力。气候变化仍旧道阻且长,当然carbon budget的估算方式仍然有多种多样。