原文: https://medium.com/coinmonks/gaia-df6b86a17d50
我们先理解传统的web或移动app如何与存储交互。每当用户登录到app时,app从远程存储器中获取用户数据并将其显示给用户。所有复杂的计算都运行在云服务器上,而不是客户端上,客户端充当一个简易的显示终端。
下面是两个虚构角色Alice和Bob与传统web/移动app交互的例子。
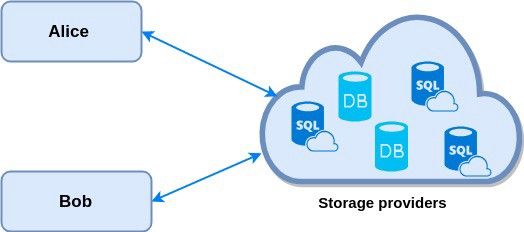 传统App如何工作
传统App如何工作
假设我们有两个用户Alice和Bob。他们都有 App:Whatsapp,Facebook 或者 Snapshot。他们与App的提供者交互。这些App基本上运行SQL或者其他数据库为用户提供服务。
当Alice想要使用即时通讯应用与Bob交互时,Alice将消息发送给服务提供者,而服务提供者将消息发送给Bob。
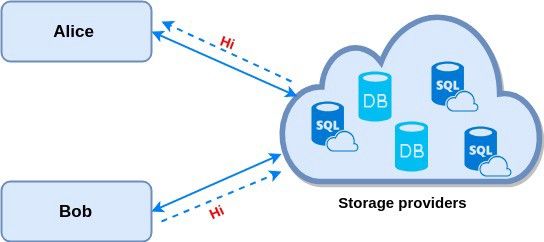 在传统应用程序中,两个用户之间如何通信
在传统应用程序中,两个用户之间如何通信
例如,Alice首先向存储服务器发送信息“Hi”,然后存储服务器将信息发送给Bob。交互路径是 Alice→存储服务器→Bob,Alice←→Bob之间没有直接路径。这是个中心化的过程,服务提供者代表Alice和Bob传递数据,并控制如何共享数据。Alice和Bob都是通过查询中新心服务器来查找彼此的消息。服务提供者总是信任的唯一来源。
中心化存储带来的问题
读取写入数据与用户身份标识没有严格关联。
不能保证Bob收到的消息确实来自于Alice,或者消息是篡改的。而且,这些大公司也并不是免费提供服务的。他们向广告商出售用户数据,从用户数据中牟利。这样,他们可以更好地锁定潜在客户。在某些情况下,他们的做法是违法的:德国一家法院本月刚刚裁定,Facebook非法收集数据,违反了消费者相关的法律。用户不能选择不同的存储提供者 ,
只有app才能选择存储器以及把用户数据保存在什么位置用户无法控制谁查看他们的数据,
存储器总是可以查看他们的数据
Blockstack 如何解决中心化存储问题
以便使用户能够控制自己的数据,并严格地将自己的数据与用户身份标识关联起来。Blockstack提供了去中心化存储系统(Gaia)和区块链命名系统(blockchain naming system即BNS)。
用户可以使用BNS提供的数字身份登录到blockstack App。用户数据将与用户公钥强关联。App将代表用户读写数据到Gaia hub(当且仅当用户允许时)。所有用户数据将被传输到他们的Gaia hub。
Gaia hub可以由用户自己拥有,也可以使用blockstack提供的默认存储空间。blockstack 在默认情况下,hub用于存储由用户的公钥加密的用户数据。这样,存储器只能看到加密好的数据块。
介绍 Gaia
Gaia是由完全由用户拥有的存储,用户决定谁能看到它,并将其写入存储。他们可以随时更改存储器。它是基于驱动程序模型构建的分布式高性能存储系统,支持许多存储服务。它是基于驱动程序模型构建的分布式高性能存储系统,支持许多存储服务。只需做很少的工作,开发人员就可以通过Gaia为Dropbox、azure、S3 实现存储。
Gaia vs IPFS:Gaia和IPFS的主要区别在于,Gaia用户对他们的数据的控制权,但在IPFS中有一个开放的网络,你的数据被放置在不同的人的设备上。
Blockstack app 如何存储数据以及用户如何控制自己的数据?
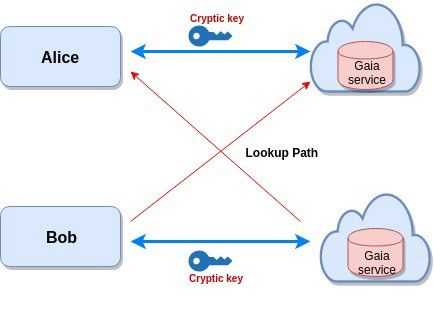 客户端如何与gaia存储交互
客户端如何与gaia存储交互
假设现在Alice正在使用一个blockstack 消息App。她使用自己的Gaia服务和她自己的公钥进行交互。Bob有相同的App。Alice和Bob都想和对方交流。为了相互通信,Alice 的 Gaia服务和Bob 的Gaia服务之间必须有读/写路径。
问题出现了,Blockstack App如何与Gaia存储交互,以及Gaia如何为用户提供全面控制?
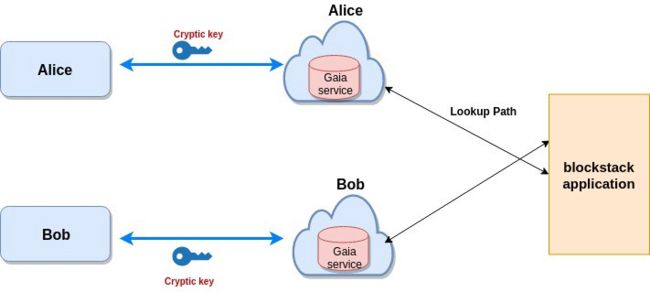 Blockstack App与Gaia服务之间的交互
Blockstack App与Gaia服务之间的交互
用户和存储后端都定义了URL。Blockstack App定义了用户存储的URL路径。它根据用户从不同的存储器进行读写,这种方式允许用户对数据的控制。查找路径允许用户控制和存储他们的数据。
Blockstack App 如何在 Gaia 中查找数据?
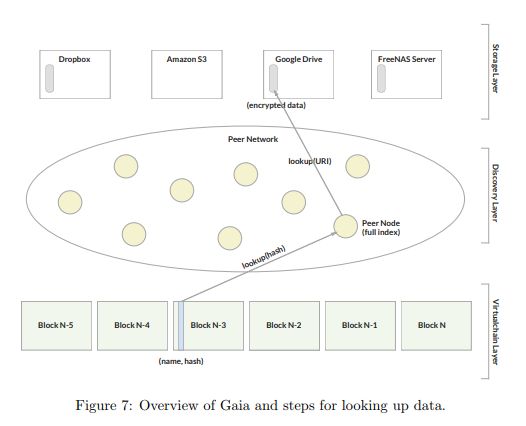 image.png
image.png
这个过程分 3 步:
在虚拟链中查找名称以获得(名称、散列)对
将用户名解析为数据(通过BNS和Atlas网络控制),以获得相应的区域文件
从zonefile中发现存储后端URI,并查找连接到存储后端的URI
从Gaia服务中获取数据
解释
App将给定的用户名解析为某些数据。假设我们有一个用户sidra.id。App将使用blockstack.js 程序库中的Blockstack BNS。Atlas网络获取根文件(区域文件),这个文件定义很多关于名称的信息。它还将提供存储 App数据的URL。
一旦App完成了对 App根文件 的查找。申请者将能够获得更具体的数据。假设想查找文件foo.json。然后,唯一的要求是执行一个正常的URL获取。最后的设置是在Gaia规范中定义的。
如何更改 Gaia的储存器?
在系统中,如果用户想要更改正在运行的Gaia储存器。因为用户拥有自己的用户名,所以他们可以很容易地将不同的数据与他们的用户名相关联,这允许他们选择不同的App路由。这最终允许他们更改App执行这些查找的方式。查找定义了数据的控制,只要用户能够控制数据的查找就控制了数据。
Gaia 接口
Gaia是一个存储后端,它提供了一个简单的接口。因此,App可以像普通的post、get和put请求工作一样进行读写。Gaia定义了三种路径:
 Gaia
Gaia
PUT/store/通过App代表用户向Gaia服务写入数据/ GET/store/从公钥哈希定义的用户中读取文件/
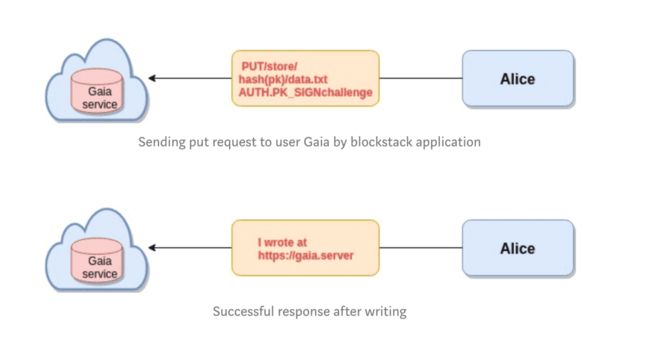
写一个 Gaia hub
Blockstack App代表用户编写,例如,app调用PUT请求将一些数据提交到Gaia服务,并提供和验证头,就像公钥签名文本一样。Gaia服务将验证此App实际上被授权向用户Gaia写入数据。
 image
image
从 Gaia 中读取数据
获取zone文件和数据
验证zonefile hash 是否匹配用户公钥
结论
Gaia是Blokckstack App的存储后端。它提供了用户拥有自己数据的能力,但是存储的数据仍然依赖于传统的DNS服务和复杂的云存储。它还将大多数用户设备无法处理的计算负载强加给用户。对于去中心化的互联网来说,用户隐私还有很长的路要走。 大多数用户还没有为这种变化做好准备。DApp需要对用户友好,并使其他人做的工作更少才能成功。
参考
https://github.com/blockstack/gaia
https://blockstack.org/whitepaper.pdf
https://www.youtube.com/watch?v=aF4IGcwMgmM&t=503s
https://www.youtube.com/watch?v=e4xIGGv3Wpc