词向量也称为词嵌入,是指将词转换成为向量的形式。
为何需要词向量
对于非结构化的数据:音频,图片,文字。前面两种的数据存储方式是天然高维和高密度的,而且数据天然的就非常具有实际意义(相近的数据表示颜色或者音频接近),几乎可以直接进入模型进行处理。但是对于文字来说不同的词如果采用类似LabelEncoder来做的,不同的词ID取值接近并不能有实际的意义表示。而如果采用类似OneHot编码则会导致向量维度过高(词汇量少说也要几万),也过于稀疏,同时也依然难以在数值上表示出不同词之间的关系。
所以我们希望能找到一种词与向量的映射关系,使得向量维度不需要过大,而且词向量在向量空间中所表示的点具有实际的意义,也就是相似含义的词在空间中的距离更近。
Word2Vec就是一个可以达到上述要求的一种方法,它可以从原始文本(语料库)中读取词语然后生成词向量。word2vec从实现方法来看分为两个大的框架:一、Hierarchical Softmax模型框架;二、Negative Sampling模型框架。
Hierarchical Softmax模型框架
模型大致由输入层、投影层和输出层构成。
其中Hierarchical Softmax模型的输出层由语料库中词出现的频数当作权值构造出的哈夫曼树作为输出。具体实现由CBOW模型(Continuous Bag-of-Words Model)或者Skip-gram模型来完成。
假设词w的上下文窗口长度skip_window为c,那么对于模型的每一次迭代计算有【w之前c个词,w,w之后c个词】
- CBOW模型实现
CBOW考虑的主要思想是要P( w | Context(w) )的概率最大化,所以接下来看CBOW模型主要就是看如何定义和计算这个概率。(当然对于语言模型来说,实际的目标函数通常是对语料库中的每个词的概率P( w | Context(w) )取对数再累加)
输入层: 2c个词向量
投影层:2c个词向量的累加
输出层:哈夫曼树(重点是词w所在的叶子节点,以及w到根节点的路径)

接下来就是重点了,也就是怎么计算P( w | Context(w) )
- 2c个上下文词向量的累加,与根节点的参数(系数theta_0和常数项bias_0)计算概率P(0)
- 计算使用了Sigmoid函数,假设计算结果为S(0)
- 根据上面计算得到的S0以及词w所在路径对应的分支,决定P(0)=S(0)或者P0=1-S(0)
- 继续使用2c个上下文词向量的累加向量与路径中下一个节点的参数计算概率P(1)
- 一直计算到w所在的叶子节点直接相连的上面那个节点P(h)
- P( w | Context(w) ) = P(0) * P(1) * ... * P(h)
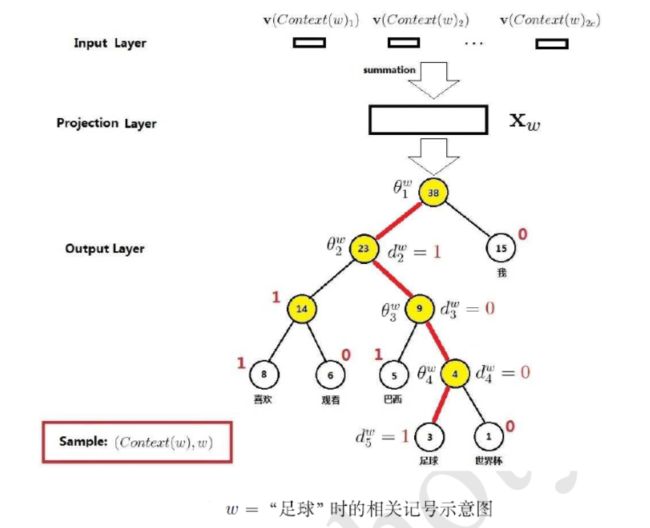 计算过程图示(不好写公式,所以省略了很多公式记号)
计算过程图示(不好写公式,所以省略了很多公式记号)
然后对P取对数,求梯度,可以得到两个部分的更新:
-
词w的路径中各个非叶节点的参数(系数theta_i和常数项bias_i)的更新
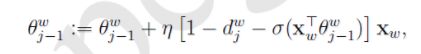 非叶节点的系数更新
非叶节点的系数更新 -
词w的上下文词向量的更新(所有w的上下文窗内词统一更新)
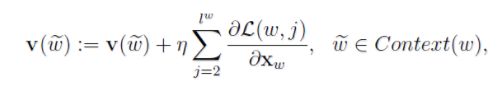 所有w的上下文词向量统一更新
所有w的上下文词向量统一更新
最后当把语料库遍历一遍或者几遍后就得到了全部词的词向量。
- Skip-gram模型实现
Skip-gram考虑的主要思想是要P( Context(w) | w )的概率最大化,所以接下来看Skip-gram模型主要就是看如何定义和计算这个概率。(当然对于语言模型来说,实际的目标函数通常是对语料库中的每个词的概率P( Context(w) | w )取对数再累加)
输入层:词w的向量
投影层:依旧是词w的向量
输出层:哈夫曼树(重点是词w的上下文窗内2c个词所在的叶子节点,以及各自到根节点的路径)
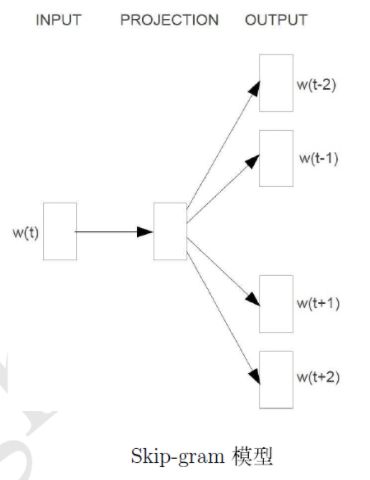
接下来的重点就是怎么定义和计算P( Context(w) | w )
- 对于词w的上下文窗内的一个词u(1):
- 计算P( u(1) | w ),其计算过程和前面的类似,都是先计算词向量w与u(1)到根路径中非叶节点的系数Sigmoid函数值,然后根据每个具体的分支得到P(i),然后将P(i)累乘得到。
- 遍历词w的上下文窗内的每个词u(i),都计算得到P( u(i) | w )
- P( Context(w) | w ) = P(u(1) | w) * P(u(2) | w) * ... * P(u(2c) | w)
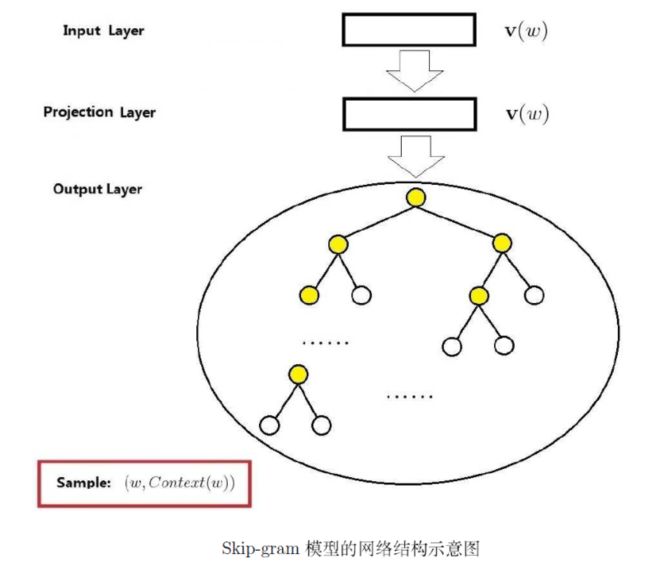 计算过程简易图示
计算过程简易图示
有了P( Context(w) | w )的计算,就可以通过取对数然后求梯度来对两个部分的参数更新:
-
每个上下文词u(i)对应的到根路径的节点的参数的更新:
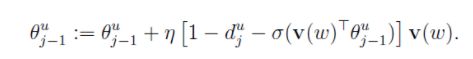 每个上下文词u所在路径的非叶节点参数更新
每个上下文词u所在路径的非叶节点参数更新 -
词w的向量的更新:
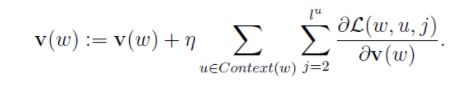 中心词w的词向量更新
中心词w的词向量更新
同样,把语料库遍历几遍后就可以得到全部词的词向量。
- 总结
- CBOW模型的一次更新是:输入2c个词向量的累加,然后对中心词w上的路径节点系数进行更新,然后对所有的上下文词的词向量进行整体一致更新。
- Skip-gram模型的一次更新是:输入中心词w的词向量,然后对每个上下文词u(i)所在的路径上的节点系数进行更新,然后对词w的词向量进行单独更新。
可见CBOW的一次更新计算量要小,Skip-gram模型计算量大,而且更新的系数也多。
Negative Sampling模型框架
Negative Sampling模型的输出层顾名思义,由对指定词的负采样来作为输出(与Hierarchical Softmax最大的不同就是用负采样替代了哈夫曼树,这样也就改变了条件概率的计算过程)。具体实现也是由两个算法模型CBOW和Skip-gram来实现。
为了解决新加入的概念带来的困扰,我们先看下负采样
- 负采样
负采样的算法思路其实还是比较简单,就是利用不同词在语料中出现的频次多少来决定被采样到的概率。
简单说就是每个词由一个线段构成(线段的长度由词频决定),所有的词构成一个大的线段,然后在这个总线段上用非常细的刻度来进行划分,采样的时候就是在这个细刻度的划分中随机选取一个,看其属于哪个词的线段内就表示本次采用选到了哪个词。
多说一句,方便接下来的算法理解,其实负采样的作用就是采用出一些“负”词(与采样词不同即为负),使得原来在哈夫曼树中需要用到的非叶节点参数以及分支选择的地方都替换成负采样出来的词。
- CBOW模型实现
输入层: 2c个词向量
投影层:2c个词向量的累加
输出层:负采样词集(重点是词w的负词词集的参数(θ),负词的概率永远是1-Sigmoid函数值)
接下来我们考虑的重点不是P( w | Context(w) )而是替换成g( w ):
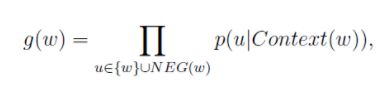
其中:

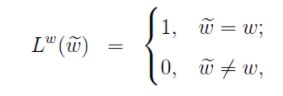

把上面的公式用通俗的语言表达就是:
- 输入词w的上下文词向量的累加:X_w
- 对词w进行负采样(得到一组非w的负词)
- X_w与词w的辅助向量(可训练的参数θ)的Sigmoid函数值越大越好
- X_w与词w的负词的辅助向量(可训练的参数θ)的Sigmoid函数值越小越好
也就是说每个词除了有自己的词向量之外,还有一个辅助向量θ
有了g( w )的定义后,就可以计算梯度,然后更新两个部分的参数:
-
每个词包括w及其采样得到的负词词集的参数θ更新:
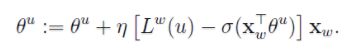
-
词w的上下文词向量的更新(所有上下文词一致更新):
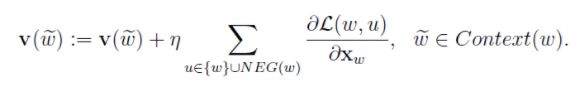
最后把语料库遍历几遍后,就可以得到全部的词向量。
- Skip-gram模型实现
输入层:词w的向量
投影层:依旧是词w的向量
输出层:每个上下文词u的负采样(重点是词u的负词词集的参数(θ),负词的概率永远是1-Sigmoid函数值)
接下来的重点不是P( Context(w) | w ),而是G

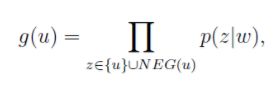
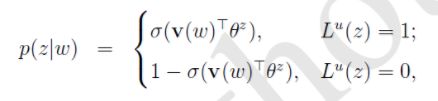
这里v(w)为词w的词向量。
通俗讲解:
- 输入词w的词向量
- 对于词w的上下文词u(i)进行负采样得到词集z(i),计算g( u(i) )
- 计算P( z(i)_j | w ),z(i)_j = u(i)时使用v(w)和z的θ的Sigmoid函数值,否则1 - Sigmoid函数值
- g( u(i) ) = 对上面j的遍历后的累积
- 对上下文词u(i)进行遍历,得到每个g( u(i) ),最后累积就是G
有了G之后就可以计算梯度进行参数更新:
- 每个负采样出来的词系数θ的更新
- 词w的词向量更新
同样把语料库遍历几遍后可以得到所有的词向量。
算法整体总结
- Hierarchical Softmax主要是通过哈夫曼树来计算,其中用到了非叶节点的系数θ。
- Negative Sampling主要是对词进行负采样,其中每个词除了有自己的词向量外还有辅助向量系数θ。
- CBOW的思想是在Context(w)基础上让w的条件概率越大越好,输入是w的上下文词向量累加,更新也是上下文的词向量一致更新。同时对于辅助向量θ的更新个数较少
- Skip-gram的思想是在w的条件上让Context(w)的条件概率越大越好,输入是w的词向量,更新的也是w的词向量。同时对辅助向量θ的更新个数较多
所以CBOW看起来更新的更平滑,适合小量文本集上的词向量构建,Skip-gram每次更新都更加有针对性,所以对于大文本集上表现更好。
接下来的TF实践,主要使用的就是Negative Sampling框架下的Skip-gram算法。
TensorFlow实践
在TensorFlow的教学文档中有一个关于词向量的基础代码实践:word2vec_basic.py。接下来提到的代码也是围绕这个进行。
-
- 读取语料构成输入数据集。
- 读语料文档
读取的细节代码就不细究了,这里想说下,因为语料第一次是需要下载的,如果直接用代码下载的话会比较慢,建议先用迅雷把文档下载下来text8.zip. 然后放入
from tempfile import gettempdir gettempdir()显示的临时文件夹中(程序中默认在这个文件夹中寻找语料文件,也可以手动修改成别的文件夹),再运行代码。
- 构建输入数据
def build_dataset(words, n_words): """Process raw inputs into a dataset.""" count = [['UNK', -1]] # 统计单词和词频的二维列表:[[单词,词频], ... ,[单词,词频]] count.extend(collections.Counter(words).most_common(n_words - 1)) dictionary = dict() # 单词和对应的索引,不常出现的词(排名在49999之后的),统统索引为0,用'NUK'表示 for word, _ in count: dictionary[word] = len(dictionary) data = list() # 语料中的单词转成索引的列表 unk_count = 0 for word in words: index = dictionary.get(word, 0) if index == 0: # dictionary['UNK'] unk_count += 1 data.append(index) count[0][1] = unk_count reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys())) # 索引->单词 return data, count, dictionary, reversed_dictionary输入:words是语料库中的词组list,以及n_words最大词数目的限制。
输出:data是语料文本中词的Index的list,count是[[词,词频], ... ,]组成的二维list,dictionary是词->索引,reversed_dictionary是索引->词。 -
- 为Skip-gram模型产生batch输入
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # [ skip_window target skip_window ] 前后skip窗长加上中心词自己后的个数
buffer = collections.deque(maxlen=span) # 双端队列,并设置最大长度
if data_index + span > len(data):
data_index = 0
buffer.extend(data[data_index:data_index + span]) # 接续上次读入的位置,读入span长度的文本内容
data_index += span
for i in range(batch_size // num_skips): # 分块总共采样batch_size个,其中每块随机选取上下文的词num_skips次,每一块的中心词固定
context_words = [w for w in range(span) if w != skip_window] # 得到不包含中心词的位置索引[0,1,3,4],假如skip窗长为2
words_to_use = random.sample(context_words, num_skips) # 得到随机选取的作为上下文的词的位置
for j, context_word in enumerate(words_to_use):
batch[i * num_skips + j] = buffer[skip_window] # 中心词
labels[i * num_skips + j, 0] = buffer[context_word] # 上下文词
if data_index == len(data):
buffer[:] = data[:span]
data_index = span
else:
buffer.append(data[data_index]) # 继续向后读入一个词,相当于读取下一块,中心词也向后偏移一个
data_index += 1
# Backtrack a little bit to avoid skipping words in the end of a batch
data_index = (data_index + len(data) - span) % len(data)
return batch, labels
输入:batch_size为一个batch的大小,num_skips为每个中心词选取上下文词的次数(要保证batch_size能整除num_skips,因为batch_size // num_skips是一个batch中会偏移向后取词的个数),skip_window是中心词的上下文词的范围(比如skip_window=2是指中心词的前面2个词和后面2个词共4个词作为这个中心词的上下文词集)
输出:batch是shape=(batch_size,)的中心词Index的np数组,labels是shape=(batch_size,1)的上下文词Index的np数组
-
- 构造Skip-gram模型
使用TF构造任何模型核心都是定义计算loss的公式以及具体计算中使用的优化方法。
- 构造Skip-gram模型
with graph.as_default():
# Input data.
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Ops and variables pinned to the CPU because of missing GPU implementation
with tf.device('/cpu:0'):
# Look up embeddings for inputs.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Construct the variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
# Compute the average NCE loss for the batch.
# tf.nce_loss automatically draws a new sample of the negative labels each
# time we evaluate the loss.
# Explanation of the meaning of NCE loss:
# http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
# Construct the SGD optimizer using a learning rate of 1.0.
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
# Compute the cosine similarity between minibatch examples and all embeddings.
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(
normalized_embeddings, valid_dataset)
similarity = tf.matmul(
valid_embeddings, normalized_embeddings, transpose_b=True)
# Add variable initializer.
init = tf.global_variables_initializer()
-
tf.nn.embedding_lookup
这个函数功能是根据输入的Index查找对应的向量,然后返回Tensor出来。喂给下面的计算NCE损失作为Input用。-
tf.nn.nce_loss
这个函数是重中之重,因为它直接作为loss的计算(再套一个tf.reduce_mean而已)。理解这个函数需要用到上面我们讲到Negative Sampling框架下的Skip-gram模型算法。
这里我们再回顾下Skip-gram模型都用到了哪些变量来计算:- 中心词w的词向量
- 上下文词u的辅助系数θ(以及bias)
- 对每个上下文词u进行负采样得到的其他词u_neg的辅助系数θ
然后我们再看下函数tf.nn.nce_loss都有哪些输入:
- weights:shape=[vocabulary_size, embedding_size]的Tensor,是全部词典的辅助系数θ
- biases:shape=[vocabulary_size]的Tensor,是全部词典的偏置项bias
- labels:中心词w对应的上下文词u的Index
- inputs:中心词w的词向量
- num_sampled:每次对于一个上下文词要采样多少个负词
- num_classes:词典的大小(词的类别个数)
通过对比可以发现tf.nn.nce_loss的输入正好涵盖了前面讲到Skip-gram模型时用到的计算变量。然后具体内部的实现细节可以通过源码或者查考其他资料。(与上面写的计算过程略有不同,除了计算Sigmoid的概率值之外,还计算了交叉熵损失,以及最后按行求和)
计算余弦相似度
最后还对词向量做了正则化(方便后面计算余弦相似度,直接使用矩阵乘积即可,因为除数已经被归一化了),然后对随机选取的词与全字典进行余弦相似度计算。另外需要注意的是不能用GPU来搭建模型,因为tf.nn.sampled_softmax_loss使用了GPU不支持的op
-
-
- 开始训练
with tf.Session(graph=graph) as session:
# We must initialize all variables before we use them.
init.run()
print('Initialized')
average_loss = 0
for step in xrange(num_steps):
batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)
feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels}
# We perform one update step by evaluating the optimizer op (including it
# in the list of returned values for session.run()
_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += loss_val
if step % 2000 == 0:
if step > 0:
average_loss /= 2000
# The average loss is an estimate of the loss over the last 2000 batches.
print('Average loss at step ', step, ': ', average_loss)
average_loss = 0
# Note that this is expensive (~20% slowdown if computed every 500 steps)
if step % 10000 == 0:
sim = similarity.eval()
for i in xrange(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8 # number of nearest neighbors
nearest = (-sim[i, :]).argsort()[1:top_k + 1]
log_str = 'Nearest to %s:' % valid_word
for k in xrange(top_k):
close_word = reverse_dictionary[nearest[k]]
log_str = '%s %s,' % (log_str, close_word)
print(log_str)
final_embeddings = normalized_embeddings.eval()
训练过程比较简单,就是从generate_batch中读取数据,然后设置好feed_dict后run得到loss,除了每隔2000打印一次平均loss外,还会每隔10000打印一次随机选取的验证词中余弦相似度最接近的词语。
最后通过normalized_embeddings.eval()得到正则化后的词向量final_embeddings
-
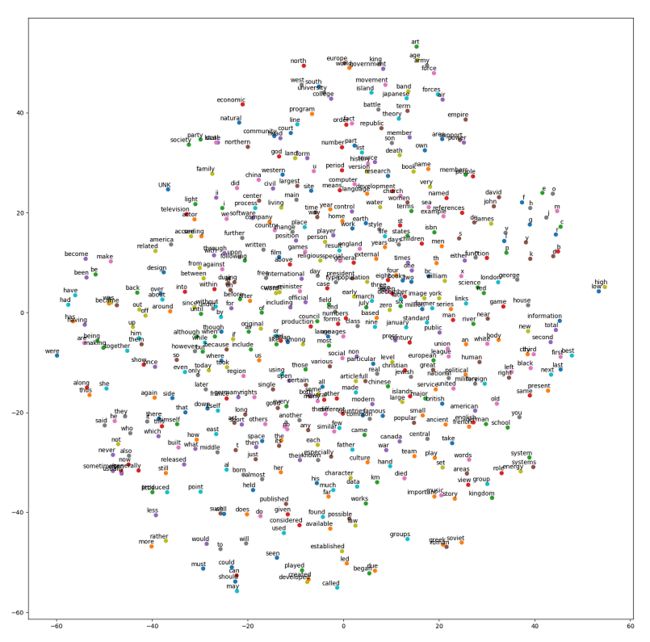
- 画图展示词向量
def plot_with_labels(low_dim_embs, labels, filename):
assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings'
plt.figure(figsize=(18, 18)) # in inches
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename)
try:
# pylint: disable=g-import-not-at-top
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000, method='exact')
plot_only = 500
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
labels = [reverse_dictionary[i] for i in xrange(plot_only)]
plot_with_labels(low_dim_embs, labels, os.path.join(gettempdir(), 'tsne.png'))
except ImportError as ex:
print('Please install sklearn, matplotlib, and scipy to show embeddings.')
print(ex)
通过使用t-SNE降维,来画图展示词向量: