| 作业链接 | 作业链接 |
|---|---|
| GIT地址 | GIT地址 |
| 结对人博客地址 | 结对人博客地址 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| Estimate | 估计这个任务需要多少时间 | 20 | 35 |
| Development | 开发 | 910 | 1270 |
| Analysis | 需求分析 (包括学习新技术) | 50 | 60 |
| Design Spec | 生成设计文档 | 40 | 55 |
| Design Review | 设计复审 (和同事审核设计文档) | 20 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| Design | 具体设计 | 40 | 60 |
| Coding | 具体编码 | 600 | 900 |
| Code Review | 代码复审 | 50 | 50 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 50 |
| Reporting | 报告 | 30 | 35 |
| Test Report | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 40 | 60 |
| 合计 | 1020 | 1415 |
二、实现过程
1.实现思路
思考:看完冗长的题目后,我们发现了需要有4个基础功能(字符统计、单词统计、行数统计、单词频率统计)、2个新功能( 词组统计、自定义输出)。2个新功能需要在基础功能上才能实现,所以我们首先需要完成基础功能。然后将新功能所属的类作为子类,基础功能所属类作为父类,通过继承能做到一部分代码复用,并且让代码结构更加清晰,编码时间也一定程度上减少了不少。同时,在程序运行时用户需要输入参数,我们将参数的输入和读取放在主函数里。
寻找资料:我们意识到在反复读取文档,匹配信息时可能需要用到一些算法,于是在网上搜索了一番,学习了正则表达式。由于很久都没有写C#代码了,我们又上网看了一些讲解C#的视频,在菜鸟教程复习了很多语法知识。
2.实现过程
以下是项目中存在的类、方法以及变量
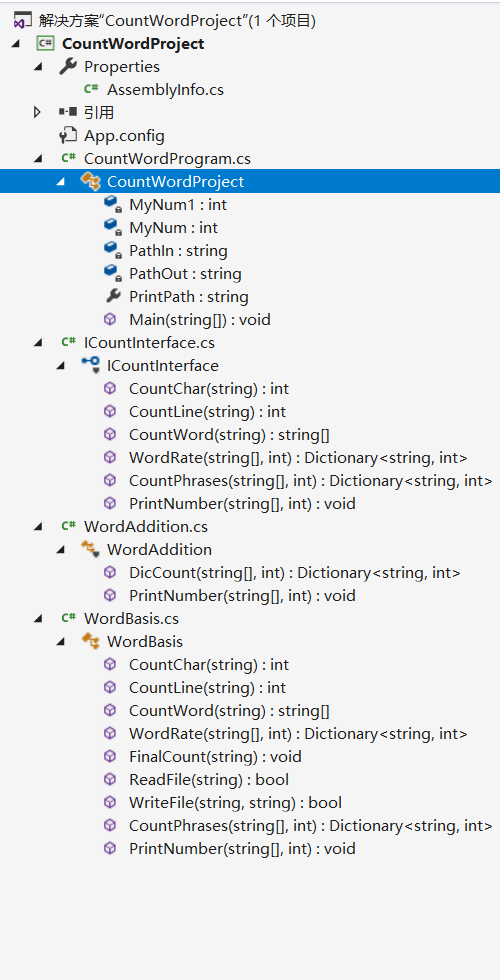
3.程序结构图
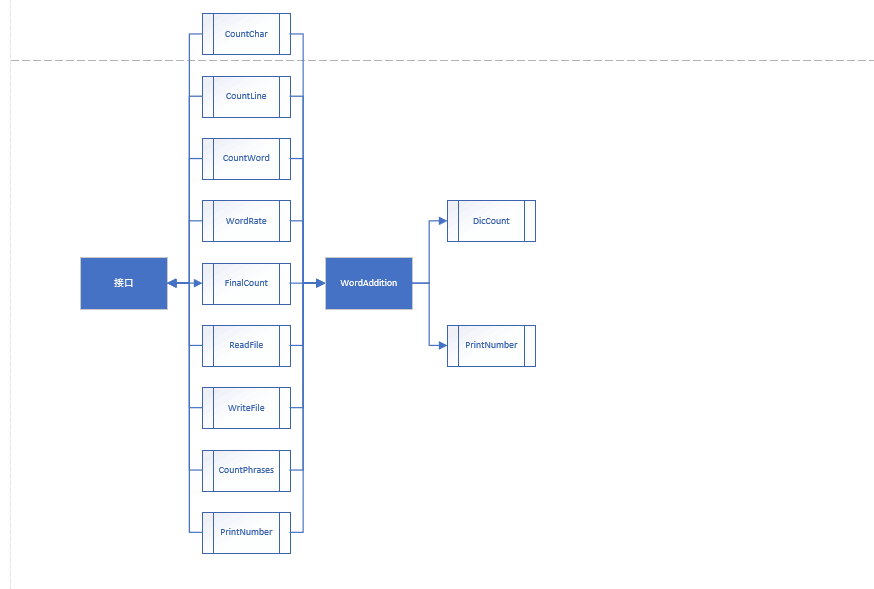
4.程序流程图
5. “Design by Contract”、“Information Hiding”、 “Interface Design”、 “Loose Coupling”
Design by Contract:我们的代码设计确保了在正确的输入下,能够得到正确的输出,完全遵照了契约式设计
Information Hiding:我们的代码做到了信息隐藏,两个没有交集的模块并没有多余的信息访问。
Interface Design:我们的代码中遵守了接口的六大原则,即单一职责原则、里氏替换原则、依赖倒置原则、接口隔离原则、迪米特法则、开闭原则
Loose Coupling:我们的代码通过多个接口实现了松耦合。
三、代码规范
- 缩进方式使用Tab缩进,大小为4个空格
- 函数、变量命名时使用英文命名,禁止使用拼音命名
- 函数名首字母大写,如WordCount是正确的命名方式,而不是wordCount
- 命名时不采用缩写,使用全称,如Imformation是正确的命名方式,而不是Info
- 每条语句单独占一行,每个花括号单独占一行
- 同类变量可以在一行定义多个
- 变量采用驼峰命名法,类名以及函数名采用首字母大写的方式,命名不加入下划线
- 对每个函数加入该函数功能说明的注释,对于实现特定功能的代码段也要加入该功能说明注释,对于较为复杂和容易使人产生疑惑的代码段和变量名也要添加注释。
四、代码互审
在审查王雷伙伴写的代码的时候发现的问题还是挺多的:王雷写的代码有很多地方读不懂,这个读不懂不是使用的语法高级,而是过多的使用了for循环和if语句还有一些乱七八糟的数组,读起来很费力,简直像一个俄罗斯人写的代码。然后我对王雷伙伴的代码进行了一些修改,将一些功能分离出来。王雷伙伴统计词频的方法是用一个string数组存放单词,然后用一个int数组存放相应的频率,将int数组进行排序的时候顺便相应的string数组也进行排序,实现对词频从大到小的输出。此方法真是出人意料,但是奈何效率太低,我对其进行改善,使用正则表达式代替,因此效率大大提升。
结对伙伴王雷的代码互审: 王雷的博客
五、关键代码
CountWord函数:
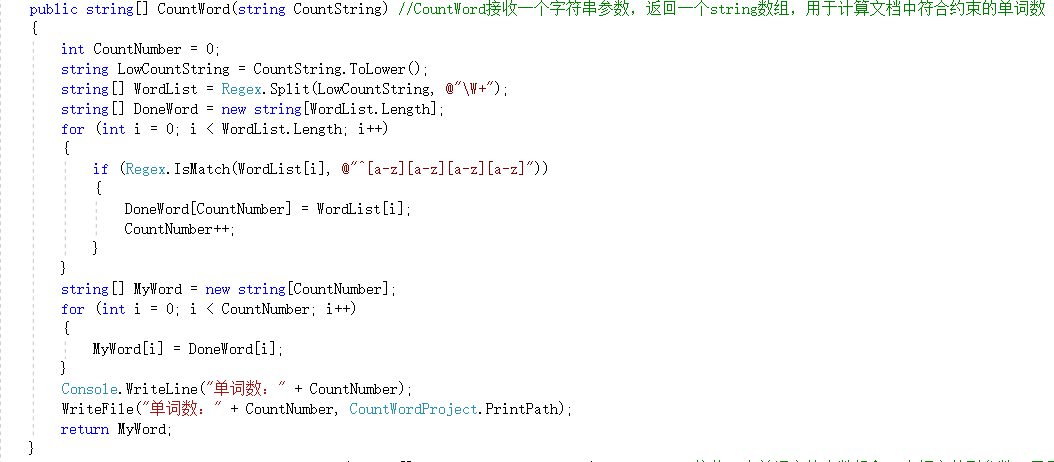
说明:首先将字符串中的字符全部转化为小写,在以空格为标志将字符串分隔并存入相应的字符串数组,找出字符串数组中长度大于4以及前4位都是字母的字符串(通过正则表达式)。
CountChar函数:

说明:首先读取文档里的内容,然后将其存入字符串,从而对字符串求长度即可得到文档字符数
WordRate函数:
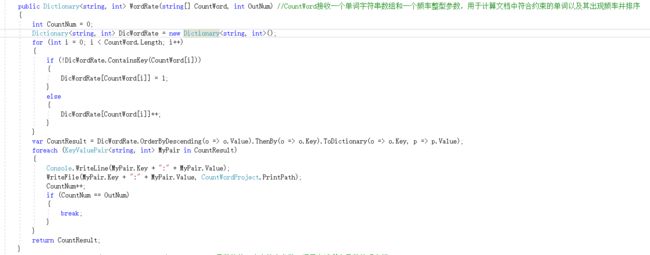
说明:通过字典类将得到的单词查出相应单词的频率,再首先按照频率次数、之后以单词字母顺序排序
CountLine函数:

说明:首先去除空行(通过正则表达式),再以换行符为标志分割统计行数。
DicCount函数:

说明:函数接受参数来组合词组、输出词组,通过循环的嵌套产生并将旧词组存入新词组。
六、运行结果:
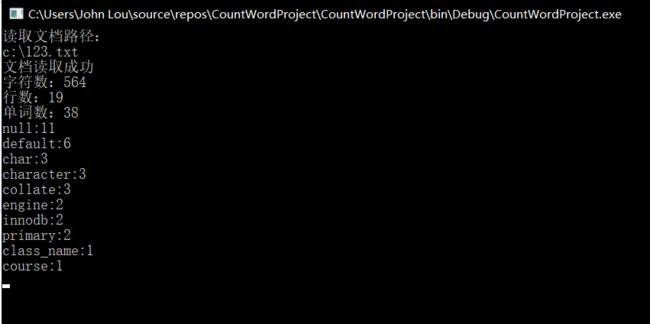
直接运行:
带命令行操作运行:
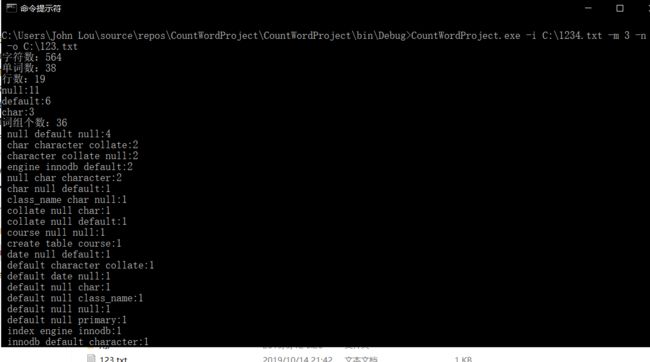
文档写入结果:

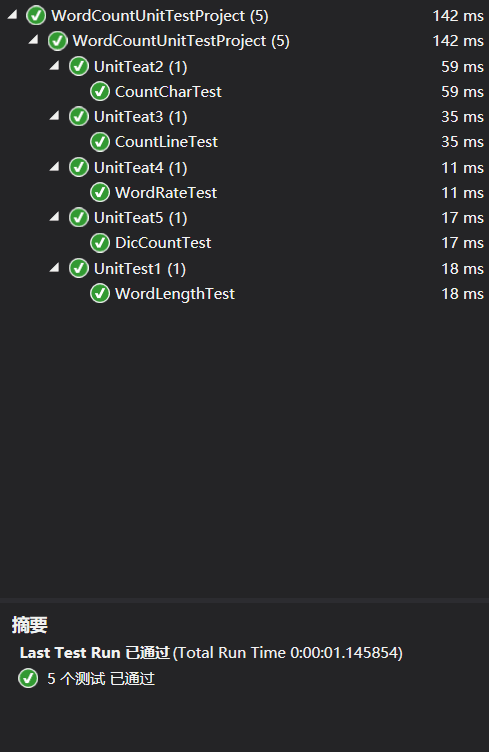
七、单元测试
测试结果:
部分测试代码:
对于CountWord函数的测试:
public void CountWordTest()
{
WordBasis.wordbasis = new WordBasis();
string[] word = { "sada", "fewa", "reht", "tyyn" };//测试方法得到的结果单词字符长度是否超过规定的4
string a = File.ReadAllText(@"D:\test.txt");
for (int i = 0; i < 4; i++)
{
Assert.AreEqual(word[i], WordBasis.CountWord(a)[i]);
}//测试CountWord方法得到的结果单词前四位是否都为字母
string b = File.ReadAllText(@"D:\test1.txt");
for (int i = 0; i < 4; i++)
{
Assert.AreEqual(word[i], WordBasis.CountWord(b)[i]);
}
}对于CountChar函数的测试:
public void CountCharTest()
{
WordBasis.wordbasis = new WordBasis();
int Num = 12;//测试CountWord得到的结果字符数
string a = File.ReadAllText(@"D:\test2.txt");
Assert.AreEqual(Num, WordBasis.CountWord(a));//测试CountWord得到的结果字符数是否符合要求
string b = File.ReadAllText(@"C:\test3.txt");
Assert.AreEqual(Num, WordBasis.CountWord(b));
}对于CountLine的测试:
public void CountLineTest()
{
WordBasis.wordbasis = new WordBasis();
int Num = 4;//测试得到的行数(不含空行)是否符合要求
string content5 = File.ReadAllText(@"D:\test2.txt");
Assert.AreEqual(Num, WordBasis.CountLine(content5));//测试得到的结果行数(含空行)是否符合要求
string content6 = File.ReadAllText(@"D:\test2.txt");
Assert.AreEqual(Num, WordBasis.CountLine(content6));
}八、性能分析
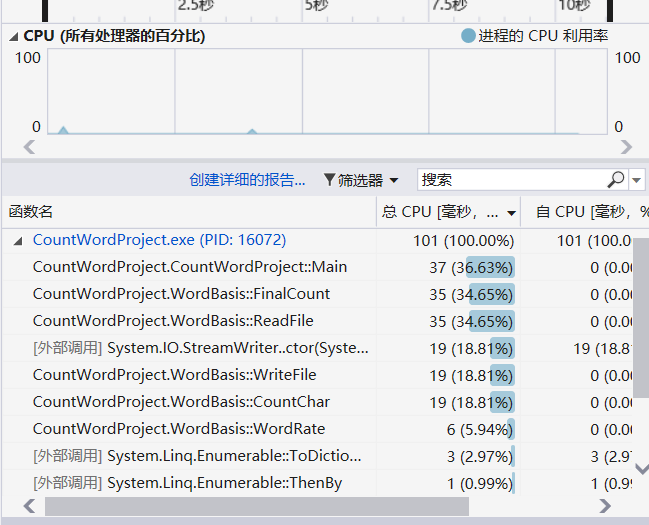
记录在改进程序性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2017的性能分析工具自动生成),并展示你程序中消耗最大的函数.
性能分析结果:
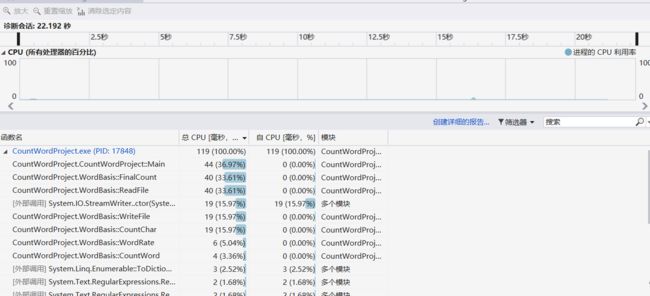
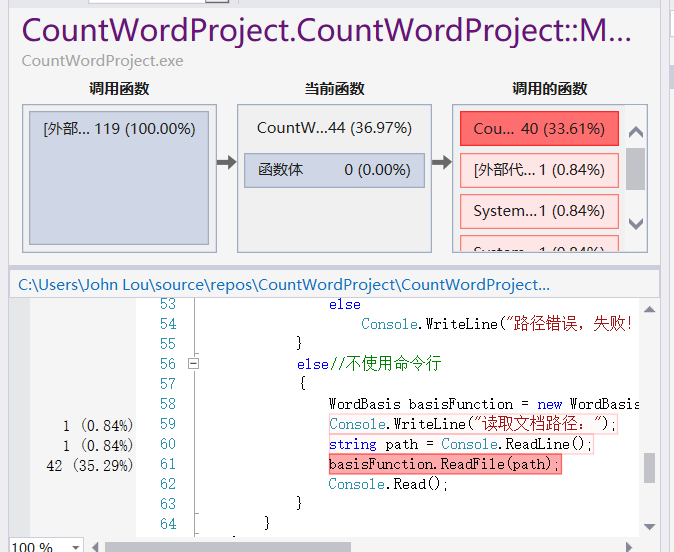
可以看到消耗最大的函数是这个读取文件的函数,之前在写代码的时候在ReadFile函数里所写的循环里每循环一次就会重新定义一个变量,耗费了不少资源,通过改进代码再次测试得到下面的结果,整体效能提高了20%左右。
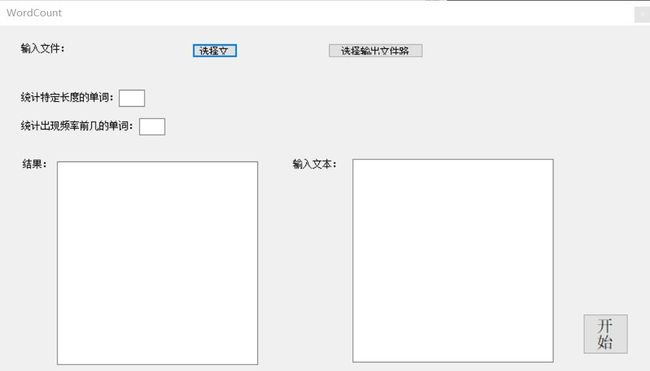
九、附加题
用户交互界面绘制
十、结对过程照片

十一、心得体会
此次结对编程很有意义,在结对过程中充当领航员和驾驶员的时候,我更多的了解了结对伙伴的编码思维,也学到了别人的编码技巧,当然,也指出了他不少错误。在自己作为驾驶员时,被伙伴指出了不少小问题,这才恍然:原来平时写代码我出了这么多错误!这些错误往往成为了一种习惯,每次编译之后出现毫无头绪的问题往往就是这种情况造成的,所以我们要格外注意。作为领航员时就像看别人下棋一样,对于整体的把控比当局者——驾驶员更加有力,往往能看的更远。大家都说观棋不语真君子,但在结对编程中,“观棋语”则是“真君子”。在这此结对中,我觉得1+1是>2的,但我认为不能为了得出结论而简单的得出这个1+1是否大于2这个结论,光从效率来讲可能有点太武断了,因为除此之外我们还互相学习了双方的优点,自省了双方的缺点,这在当前阶段比效率的提升重要太多了。