目录
- 0. 数据库
- 1. 基本数据类型和引用数据类型的区别
- 2. 检查时异常和运行时异常的区别
- 3. Spring相关
- 4. Java 中的 HashMap 的工作原理是什么?
- 5. HashMap 和 Hashtable 有什么区别?
- 6. SQL优化
- 7. Redis
- 8. RabbitMQ
- 9. Collection
最近一直在面试。面试了大约有10来家公司,有1000人以上的大公司,也有50左右的小公司。时间仓促没有准备充分,面试的机会虽然很多,但是面试时表现的一般。通过这10来场的面试,我对自己的知识体系薄弱环节有了较为清楚的认识。这里记录一些我在面试中遇到的比较常见的面试题。这只是其中的小小一部分。
0. 数据库
好久没写代码了,SQL语句很生疏,导致我面试的时候简单的语法都忘了,吃了很大亏。这里推荐一篇大佬的博客。该博客中收录了常见的MySQL面试题和笔试题。SQL复习
1. 基本数据类型和引用数据类型的区别
问题分析:这个问题不是说有多难,只是我们平时专注于代码逻辑,很容易忽视代码的底层原理。
示例答案:
- 基本数据类型在创建时,在栈上给其划分一块内存,将数值直接存储在栈上。
- 引用数据类型在被创建时,首先要在栈上给其引用(句柄)分配一块内存,而对象的具体信息都存储在堆内存中,然后由栈上的引用指向堆中的对象的地址。
这道题主要考察JVM中内存模型,这块需要重点理解。
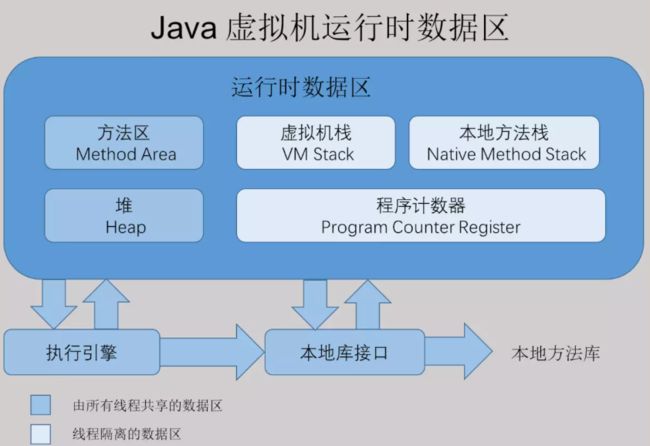
JVM区域划分为:程序计数器,虚拟机栈,堆,方法区,本地方法栈五个区域。
①程序计数器: Java代码会被翻译成字节码,不同字节码指令指挥计算机干不同的事。程序计数器是用来记录每个线程当前执行的指令的位置。因为程序可以是多线程的,所以每个线程都有自己的程序计数器。
②Java虚拟机栈:Java代码执行时,一定是线程执行某个方法中的代码。JVM中有一块区域用来保存每个方法内的局部变量等数据,这个区域就是Java虚拟机栈。为什么需要这个区域?因为每个线程都会去执行各种方法的代码,方法内还会嵌套调用其他的方法,所以每个线程都要有自己的Java虚拟机栈。
调用执行任何方法时,都会给方法创建栈帧,然后入栈。
③Java堆内存:用来存放Java中的创建的实例对象。比如Student对象。那么Java虚拟机栈中的变量student就会存放该对象的地址,或者说student指向了该对象。
④Java方法区:主要还是存放我们自己写的各种类相关的信息。
⑤本地方法栈:Java执行时会调用非Java代码,执行native方法,本地方法栈用来存放native方法的局部变量表等信息。
2. 检查时异常和运行时异常的区别
这个问题容易忽略。
Java中把所有的非正常情况分为两种:异常(Exception)和错误(Error),他们都继承Throwable父类。
Java的非正常情况可以分为检查异常和非检查异常。
其中Exception异常分为运行时异常和非运行时异常。

- 检查异常:
- 概念:就是编译器要求你必须要处理的异常。你的代码还没有运行时,编译器就会检查你的代码,对于可能出现的异常你必须使用try...catch...或者throws exception。
- 处理:①使用throws exception往上抛出,一直可以抛到Java虚拟机来处理。②使用try...catch...
- 范围:除了RuntimeException与其子类,错误Error以外的,差不多都是检查异常。
- 非检查异常:
- 概念:编译器不要求强制处置的异常,虽然可能出错,但是不会在编译时检查。
- 处理:①try..catch...②继续抛出③不处理
- 范围:RuntimeException与其子类,Error错误。
- 运行时异常:RuntimeException及其子类
- 非运行时异常:异常中除了RuntimeException及其子类以外都是非运行时异常。
3. Spring相关
如果你使用SSM框架,基本Spring一上来就问这几个问题,必须非常熟悉。
IOC:控制反转,传统的Java开发模式中,当需要一个对象时,我们会自己使用new或者getInstance等直接或者间接调用构造方法创建一个对象。而在Spring中,Spring容器使用了工厂模式为我们创建了所需要的对象,不需要我们自己创建了,直接调用Spring提供的对象就可以了。
DI:依赖注入,Spring使用JavaBean对象的set方法或者带参数的构造方法为我们在创建对象时将其属性自动设置所需要的值的过程,就是依赖注入的思想。
AOP面向切面编程:在面向对象编程思想中,我们将事物纵向抽取成一个个的对象。而在面向切面编程中,我们将一个个的对象某些类似的方面横向抽成一个切面,对这个切面进行一些如权限控制,事物管理,记录日志等公用操作处理的过程就是面向切面编程的思想。AOP的底层是动态代理,如果目标对象是接口采用JDK动态代理,如果是类采用Cglib方式实现动态代理。
动态代理的原理可以看看我之前写的一篇:动态代理
4. Java 中的 HashMap 的工作原理是什么?
面试官开始问你基础的时候,很多都从HashMap开始。
- Java 中的 HashMap 是以键值对(key-value)的形式存储元素的。HashMap 需要一个 hash 函数,它使用 hashCode()和 equals()方法来向集合/从集合添加和检索元素。当调用 put()方法的时候,HashMap 会计算 key 的 hash 值,然后把键值对存储在集合中合适的索引上。如果 key已经存在了,value 会被更新成新值。HashMap 的一些重要的特性是它的容量(capacity),负 载因子(load factor)和扩容极限(threshold resizing)。
5. HashMap 和 Hashtable 有什么区别?
HashMap 和 Hashtable 都实现了Map 接口,因此很多特性非常相似。但是,他们有以下不同点:
- HashMap 允许键和值是 null,而Hashtable 不允许键或者值是 null。
- Hashtable 是同步的,而 HashMap 不是。因此,HashMap 更适合于单线程环境,而 Hashtable适合于多线程环境。
- HashMap 提供了可供应用迭代的键的集合,因此,HashMap 是快速失败的。另一方面,Hashtable 提供了对键的列举(Enumeration)。一般认为 Hashtable 是一个遗留的类。
6. SQL优化
这里只是一些SQL优化的思路,远远不止这些。
- 使用JOIN的时候,应该用小的结果驱动大的结果『left join左边表结果尽量小,如果有条件应该放到左边先处理』
- 尽量把牵涉到多表联合查询拆分多个query,因为连表查询效率低,容易到之后锁表和阻塞。
- limit的基数比较大时使用between
- 尽量避免在列上做运算,这样导致索引失效。
select * from admin where year(admin_time)>2014
优化为:
select * from admin where admin_time>'2014-01-01'
7. Redis
谈到Redis的话可以从以下几个方面简单说说。
可以看看之前写的Redis复习一下:Redis
本质上是一个key~value类型的内存数据库。
数据结构:String Hash List Set Sorted Set
应用场景:会话缓存、全页缓存、队列、排行榜
Memcache和Redis的主要区别:
- 前者是把数据全部存在内存中,数据不能超过内存的大小,断电后数据库会挂掉。后者有部分存在硬盘上,这样能保证数据的持久化。
持久化:
- RDB持久化:该机制可以在指定的时间间隔内生成数据集的时间点快照。(适合用来备份)
- AOF持久化:记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。AOF文件中的命令全部以Redis协议的格式来保存,新命令会被追加到文件的尾部。(AOF文件是一个只进行追加操作的日志文件)
8. RabbitMQ
明白MQ的概念、原理、使用场景。
- 概念:MQ全称是Message Queue,可以理解为消息队列的意思,简单来说就是消息以管道的方式进行传递。RabbitMQ是一个实现了高级消息队列协议的消息队列服务,用Erlang语言的。
- 使用场景:比如秒杀系统中,当用户访问量很大时系统会提示我们排队结算。这种排队结算就使用到了消息队列,生产者生产的消息放入通道中一个个地被消费,而不是某个时间内突然出现大批量的查询新增把数据库给搞宕机了。所以RabbitMQ的作用是削峰填谷。
- 工作机制:
- 生产者:创建消息,发送消息到服务器
- 消费者:接受确认消息
- 代理:RabbitMQ本身,不产生消息,只是传递消息。
- 发送原理:首先要连接RabbitMQ。应用程序和RabbitMQ服务器之间会创建一个TCP连接,一旦TCP打开连接,并且通过了认证(认证就是尝试连接RabbitMQ服务器之前发送给服务器的连接信息,用户名和密码),应用程序和和Rabbit就创建了一条AMQP的信道。信道是创建在“真实”TCP上的虚拟连接,AMQP命令都是通过信道发送出去的,每个信道都会有一个唯一的ID,不论是发布消息,订阅队列或者介绍消息都是通过信道完成的。
- 为什么不通过TCP直接发送命令?
- 对于操作系统来说创建和销毁TCP会话是非常昂贵的开销,假设高峰期每秒有成千上万条连接,每个连接都要创建一条TCP会话,这就造成了TCP连接的巨大浪费,而且操作系统每秒能创建的TCP也是有限的,因此很快就会遇到系统瓶颈。
- 如果我们每个请求都使用一条TCP连接,既满足了性能的需要,又能确保每个连接的私密性,这就是引入信道概念的原因。
- 持久化工作原理:Rabbit会将你的持久化消息写入磁盘上的持久化日志文件,等消息被消费之后,Rabbit会把这条消息标识为等待垃圾回收
- RabbitMQ防止消息丢失?
- 客户端丢失消息确认:RabbitMQ引入了消息确认机制,当消息处理完成后,给Server端发送一个确认消息,来告诉服务端可以删除该消息了,如果连接断开的时候,Server端没有收到消费者发出的确认信息,则会把消息转发给其他保持在线的消费者。
9. Collection

- List接口:
- arrayList:底层实现基于动态数组,随机的访问查询比较快,插入,删除,修改比较慢,线程不安全。
- LinkedList 底层实现基于链表,所以查询慢,修改,删除,插入快,线程不安全。
- Vector :也是基于数组实现的,和arrayList的区别是线程安全,效率低。
- Set接口:不可重复
- HashSet: 使用哈希算法去重复, 效率高
- LinkedHashSet: HashSet的子类, 去重复并且保留存储顺序
- TreeSet: 可以用指定的比较方法进行排序