一:printf 格式化输出
%ns: 输出字符串。n 是数字指代输出几个字符
%ni: 输出整数。n 是数字指代输出几个数字
%m.nf: 输出浮点数。m 和 n 是数字,指代输出的整数位数和小数位数。如%8.2f
代表共输出 8 位数,其中 2 位是小数,6 位是整数。
split , substr , strlen
输出格式:
\a: 输出警告声音
\b: 输出退格键,也就是 Backspace 键
\f: 清除屏幕
\n: 换行
\r: 回车,也就是 Enter 键
\t: 水平输出退格键,也就是 Tab 键
\v: 垂直输出退格键,也就是 Tab 键
printf '%s' $(cat student.txt)
printf '%s\t %s\t %s\t %s\t %s\t %s\t \n' $(cat student.txt)
3: awk 基本使用
awk ‘条件 1{动作 1} 条件 2{动作 2}…’ 文件名
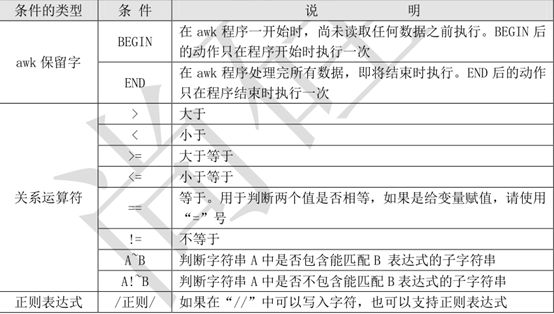
条件(Pattern):
一般使用关系表达式作为条件。这些关系表达式非常多,具体参考表 12-3 所示,例如:
x > 10 判断变量 x 是否大于 10
x == y 判断变量 x 是否等于变量 y
A ~ B 判断字符串 A 中是否包含能匹配 B 表达式的子字符串
A !~ B 判断字符串 A 中是否不包含能匹配 B 表达式的子字符串
(1)格式化awk输出
awk '{printf $1 "\n"}' student.txt
printf '%s' $(cat student.txt)
awk '{printf $2 "\t" $6 "\n"}' student.txt
#输出第二列和第六列
(2)条件输出打印分数》90同学的姓名
grep -v "Name" student.txt | awk '$4>=90{ printf $2 "\n" }'
(3)awk执行过程
1: 如果有 BEGIN 条件,则先执行 BEGIN 定义的动作
2: 如果没有 BEGIN 条件,则读入第一行,把第一行的数据依次赋予$0、$1、$2 等变量。其中$0代表此行的整体数据,$1 代表第一字段,$2 代表第二字段。
3: 依据条件类型判断动作是否执行。如果条件符合,则执行动作,否则读入下一行数据。如果没有条件,则每行都执行动作。
1 读入下一行数据,重复执行以上步骤。
4: awk 内置变量
$1 表示第一列等
$0 代表目前 awk 所读入的整行数据。我们已知 awk 是一行一行读入数据的,$0 就代表当前读入行的整行数据。
$n 代表目前读入行的第 n 个字段。
NF 当前行拥有的字段(列)总数。
NR 当前 awk 所处理的行,是总数据的第几行。
FS 用户定义分隔符。awk 的默认分隔符是任何空格,如果想要使用其他分隔符(如“:”),就需要 FS 变量定义。
例子:根据 FS定义分隔符查看用户
cat /etc/passwd | grep "/bin/bash" | awk 'BEGIN {FS=":"} {printf $1 "\t\n" } '