| GIT地址(伙伴的) | https://github.com/ccfuncy/WordCount |
| 结对伙伴的博客地址 | https://www.cnblogs.com/ccfuncy/p/11657167.html |
| 我的博客地址 |
https://www.cnblogs.com/sparrowchengyu/p/11643086.html |
| 结对伙伴的学号 |
201731062424
|
| 作业的链接 | https://www.cnblogs.com/harry240/p/11524113.html |
一、结对过程
我们在结对编程时,找了一个可以讨论,又可以给电脑充电的地方(^-^)
结对的照片如下:

二、PSP表格
| PSP |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
| Planning |
计划 |
30 |
25 |
| · Estimate |
· 估计这个任务需要多少时间 |
840 |
1200 |
| Development |
开发 |
710 |
950 |
| · Analysis |
· 需求分析 (包括学习新技术) |
40 |
60 |
| · Design Spec |
· 生成设计文档 |
20 |
30 |
| · Design Review |
· 设计复审 (和同事审核设计文档) |
40 |
60 |
| · Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 |
20 |
| · Design |
· 具体设计 |
30 |
40 |
| · Coding |
· 具体编码 |
400 |
600 |
| · Code Review |
· 代码复审 |
60 |
40 |
| · Test |
· 测试(自我测试,修改代码,提交修改) |
90 |
100 |
| Reporting |
报告 |
100 |
90 |
| · Test Report |
· 测试报告 |
40 |
50 |
| · Size Measurement |
· 计算工作量 |
30 |
20 |
| · Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
20 |
|
|
合计 |
810 |
1040 |
三、解题思路
拿到题目后,首先仔细阅读了题目要求,根据要求,模拟了一个大概的框架,将整个题目要求细分成不同的模块,再思考如何去实现这些模块,对于不懂的部分通过百度查询相关资料。和结对伙伴讨论后,对于题目的要求我们明确了具体的解决方案。
对于题目中的要求:
1.判断是否是一个单词时(要求:一个单词必须以4个英文字母开头),可以用正则表达式去判断是否符合要求;
2.排序的部分算是我们遇到的一个难点,经过结对伙伴的建议,我们决定在统计单词次数的时候采用字典贮存,再通过C#中字典自带的orderby排序(支持多级排序);
3.代码封装部分,我们决定将实现的类封装成类库;命令行部分,我们采用[commandlineparser]( https://github.com/commandlineparser/commandline) 开源库来完成命令解析,最后GUI再调用封装好的类库就行了。
https://github.com/commandlineparser/commandline) 开源库来完成命令解析,最后GUI再调用封装好的类库就行了。
四、代码设计及接口封装设计
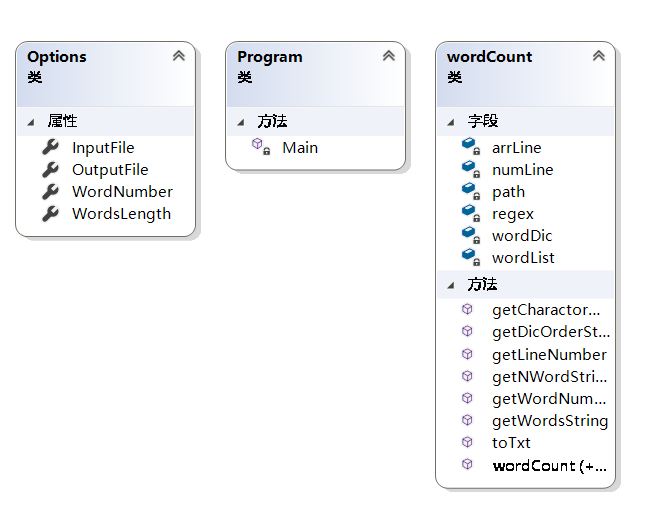
通过分析题目要求,设计了三个类:Options类、wordCount类、Program类
1.Options这个类负责解析文件或者输入的字符串:其中-i参数设定读入的文件路径(对应InputFile这个属性);-o参数设定生成的文件的存储路径(对应OutputFile这个属性);-m参数设定统计的词组长度(对应WordsLength这个属性);-n参数设定输出的单词数量(对应WordNumber这个属性)。
2.wordCount类负责此题目中的基本功能的实现:其中包括判断单词是否匹配的构造方法、处理文本的构造方法、获取字典序、词组等各种方法。(具体在下面的内容中叙述)。
3.Program类中就是main方法。
在进行接口的封装时,就是将统计字符数、单词数、最多单词及其频数这些模块独立出来,独立成为WordCountLib。
代码实现部分:我负责的主要是对传入文本的处理以及对词组的处理的方法(此处就不粘贴代码以及具体阐释了,后续代码展示部分粘贴及阐释)。
这是我们的代码流程:
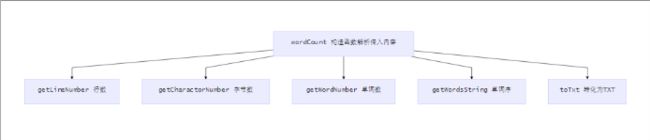
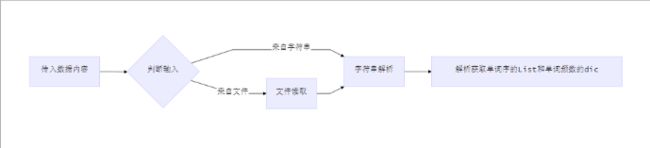
重要方法的流程:
五、代码规范
- 左右花括号要独自一行,括号内容为空时不用2.if/for/while/do等关键字后面与左括号之间需要加空格:if (x == 1)
- 方法名和左括号之间不能有空格
- for语句中的表达式之间要加一个空格
- 运算符左右需要加空格:a = b * c
- 要求代码行下一行相对于上一行缩进4个空格
- 适当增加空行,增强代码的可读性
- 注释应当增加代码的可读性,但注释也要保持简洁,过多显得繁琐
- 每行代码或注释不应超过屏幕宽度,超过要换行,换行后的代码要缩进4个空格
- 将注释放在单独的行上,而不是将其放在每行代码的末尾。且对于不同地方的注释有不同要求
- 对于属性及方法注释
例: ///
/// 获取行数
///
///
public int getLineNumber()
- 单行代码注释
//单行注释
- 多行代码注释
/*
多行注释
多行注释
*/
10. 命名规则:所有命名空间、类、方法、接口、属性、参数和变量等命名规则——我们采用的是驼峰命名法(小驼峰法):混合使用大小写字母,即除第一个单词之外,其单词首字母大写,譬如方法名:wordCount
六、代码复审及部分单元测试
1.代码复审
在审查同伴的代码时,发现了如下情况:
1.虽然制定了编码规范,可能由于个人习惯原因,仍然存在个别命名不规范问题。
2.注释仍然存在可能不是很理解的问题,注释的可理解性不够强。
3.伙伴的某些代码最开始不是很理解(可理解性不强),经过他的讲解,最终明白了。
PS:在对代码进行互审的过程中发现的问题,最终和结对伙伴一起改进,使得我们最终的代码更加规范。
2.部分单元测试
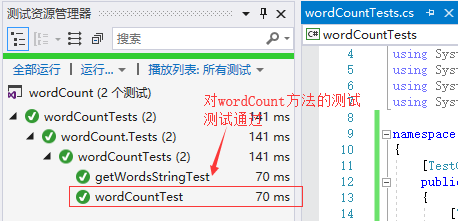
这是对wordCount这个构造方法的测试:因为这个方法是对输入的文本进行处理,所以我测试传入的文本是否为空。
测试代码:
[TestMethod()] public void wordCountTest() { wordCount word = new wordCount(@"./test.txt"); Assert.IsNotNull(word); }
这是测试的结果:
这是对处理词组那个方法的测试:处理词组的时候,最后返回词组字符串。所以测试时,如果我测试时返回的词组要不为空。
测试代码:
[TestMethod()] public void getWordsStringTest() { wordCount word = new wordCount("qwerr asdfa FILE222 assert!", 1); string str = word.getWordsString(); Assert.IsNotNull(str); }
测试结果:
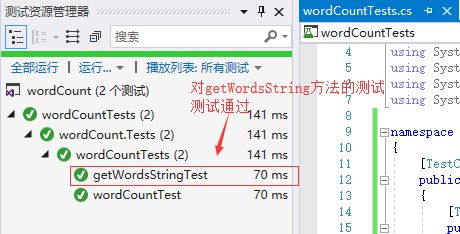
由于这个VS是社区版,所以没有测试覆盖率的地方。

使用的10个不同的测试用例及其结果
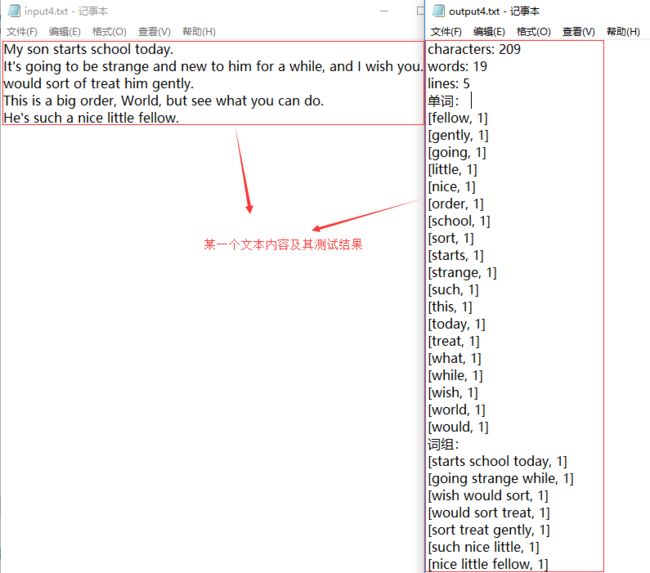
对其中的一个文本及其结果截图:
七、异常处理及改进代码
异常处理以及代码的改进部分是和结对伙伴一起再次审查代码后一起做的改进。
我们的附加功能部分,处理了窗体的输入异常,代码如下:
string path = fileName.Text; string strWord = richTextBox1.Text; if(path.Length<2 && strWord.Length < 2 ) { MessageBox.Show("请至少选择一个txt文件或者输入长度大于2的字符","提示"); return; } if(textBox3.Text.Length < 3) { MessageBox.Show("无输出路径", "提示"); return; }
我们通过效能分析测试了计算模块接口部分的性能,具体截图如下:
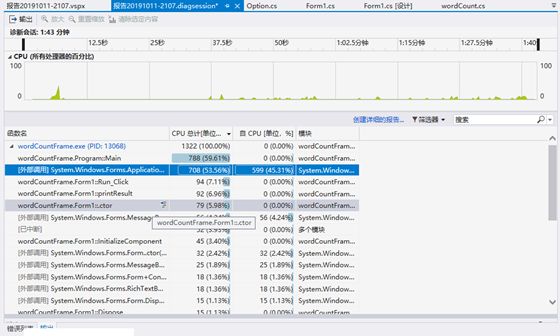
接着创建详细的报告:
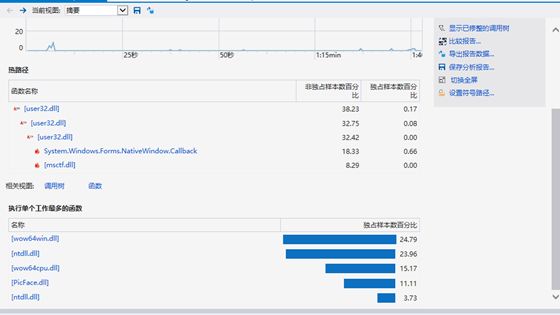
通过测试的结果,我们觉得存在代码复用性不太好、双次读取文件、耗用内存过高等问题,所以我们讨论后决定将复用的代码提取出来,减小内存消耗。
下面是我们讨论后优化的代码:
public wordCount(string arrLine,int numLine) { this.arrLine = new StringBuilder(arrLine); this.numLine = numLine; char[] sep = { ' ', ',', '.', ',' }; foreach (string i in arrLine.ToString().ToLower().Split(sep)) { if (i.Length >= 4 && Regex.IsMatch(i, regex)) { wordList.Add(i.ToLower()); } } wordList.ForEach(x => { if (wordDic.ContainsKey(x)) { wordDic[x] += 1; } else { wordDic[x] = 1; } }); }
八、部分代码展示
1.这是对传入的文本进行处理的函数:先是接收一个参数,是传入的文本的路径,再进行读取;对于文本中的单词,由于题目要求,单词必须是以4个英文字母开头,所以文本中的单词进行匹配;当然还有处理行数等操作。
//构造函数,处理文本 public wordCount(string path) { this.path = path; StreamReader reader = new StreamReader(path, Encoding.Default); string line; while ((line = reader.ReadLine()) != null) { arrLine.Append(line); if (line != "") { numLine++; } } char[] sep = { ' ', ',', '.', ',' }; foreach (string i in arrLine.ToString().ToLower().Split(sep)) { if (i.Length >= 4 && Regex.IsMatch(i, regex)) { wordList.Add(i.ToLower()); } } wordList.ForEach(x => { if (wordDic.ContainsKey(x)) { wordDic[x] += 1; } else { wordDic[x] = 1; } }); }
2.这是对文本中的词组进行处理的函数:我们默认的词组长度是3,即在用户不进行设定时,我们长度为3确定为一个词组,对词组数也进行处理。
///sparrow /// 获取词组 /// public string getWordsString(int wordsLength=3) { List<string> wordListTmp = new List<string>(); List<string> listTmp = new List<string>(); List<string> listTmp1 = new List<string>(); char[] sep1 = { ',', '.', ',' }; foreach (string i in arrLine.ToString().Split(sep1)) { wordListTmp.Add(i.ToLower()); } foreach (string i in wordListTmp) { foreach (string s in i.Split(' ')) { if (s.Length >= 4 && Regex.IsMatch(s, regex)) { listTmp.Add(s); } //词组数 if (listTmp.Count().Equals(wordsLength)) { listTmp1.Add(string.Join(" ", listTmp.ToArray())); listTmp.RemoveAt(0); } } listTmp.Clear(); } Dictionary<string, int> wordDicTmp = new Dictionary<string, int>(); listTmp1.ForEach(x => { if (wordDicTmp.ContainsKey(x)) { wordDicTmp[x] += 1; } else { wordDicTmp[x] = 1; } }); return string.Join("\n", wordDicTmp.ToArray()); } /// 词组单词数 /// 词组字符串
3.主函数展示:
static void Main(string[] args) { Parser.Default.ParseArguments(args) .WithParsed (o => { StringBuilder result = new StringBuilder(); wordCount word = new wordCount(o.InputFile); result.Append("characters: " + word.getCharactorNumber()+"\n"); result.Append("words: " + word.getWordNumber()+"\n"); result.Append("lines: " + word.getLineNumber()+"\n"); if (o.WordNumber!=0) { result.Append("单词: \n"); result.Append(word.getNWordString(o.WordNumber)); result.Append("\n"); } else { result.Append("单词: \n"); result.Append(word.getNWordString()); result.Append("\n"); } if (o.WordsLength != 0) { result.Append("词组: \n"); result.Append(word.getWordsString(o.WordsLength)); result.Append("\n"); } word.toTxt(o.OutputFile, result.ToString()); Console.WriteLine("write success"); }); }
PS:只对部分代码进行了展示,详细代码见git。
九、附加功能展示
这是我们设计的一个简单的GUI界面
1.模拟一下输入文本:
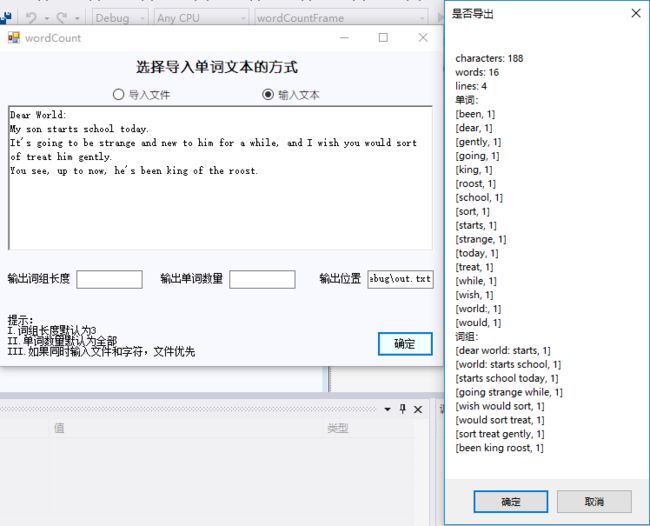
导出后就会在输出文件的位置有一个.txt文件。
2.模拟一下导入文件
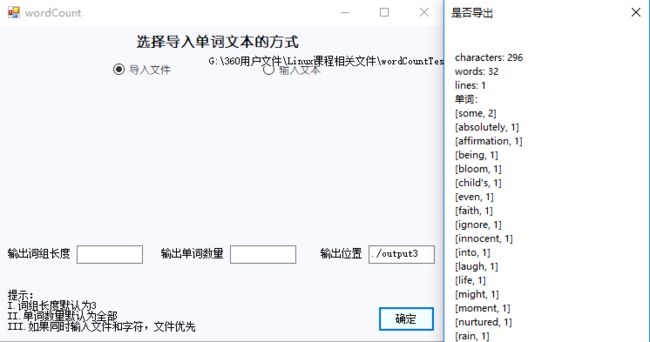
3.用户异常输入后的提示(只截图了单词数量异常输入的情况)
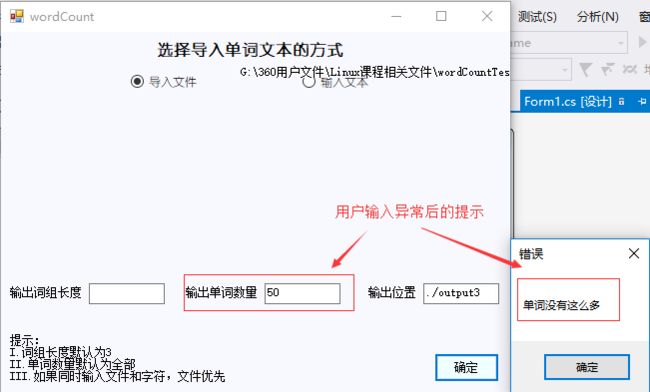
十、总结
这次作业算是一次全新的体验过程,跟一个伙伴结对编程,以前都是自己个人编码。结对过程中,也渐渐发现了结对的一些好处以及存在的问题。首先:结对的好处就是,比如这次的项目,如果个人完成,工作量比较大,遇到不会的一些问题只能自己默默查资料,而且还不排除走弯路从而花费更多的时间的情况;但是有一个伙伴就不一样,在编码过程中遇到的一些问题可以相互讨论,毕竟两个人的想法会比一个人的想法更加灵活完善。结对过程中,队友属于编码能力比较ok的,所以我遇到的问题队友可以给我提出意见;队友的问题,我不能解决的,也会通过查找资料来节省时间。结对过程中存在的问题就是由于个人习惯的原因,所以即便统一了编码规范,也会出现编码不符合规范的情况,所以又在后期需要花费时间来解决这个问题;而且,两人结对,需要有交流、沟通,总的来说,时间成本较高。但是总的来说,此次结对还是很有收获的,也实现了1+1>2,如果以后有机会,也会继续尝试结对这种形式的编程。