1.linux文件描述符
描述符从3开始以由小到大的顺序编号,0,1,2,分配给标准I/O用作标准输入、标准输出和标准错误。Windows下叫句柄
2.协议族与套接字类型(socket函数第一、二个参数)
#include
int socket(int domain,int type,int type, int protocol);
domain常用 : IPv4协议族 PF_INET;
type: SOCK_STREAM(面向连接,TCP), SOCK_DRGAM(面向消息, UDP)
第三个参数:决定最终采用的协议,选用TCP时,第三个参数可以为0。
3.地址族与数据序列
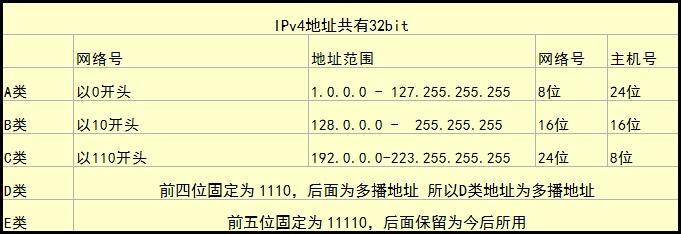
端口号:操作系统参考端口号把数据传输给相应端口的套接字。端口号范围0 65535,其中01023位知名端口。TCP套接字和UDP套接字可以重复使用同一端口号。
4.IPv4地址结构体
struct sockaddr_in
{
sa_family_t sin_family; //
uint16_t sin_port; //16位TCP/UDP端口号
struct in_addr sin_addr; //32位IP地址
char sin_zero[8]; //不使用
};
其中in_addr定义如下:
struct in_addr
{
In_addr_t s_addr; //32位IPv4地址
}
- sin_zero为了让sockaddr_in的大小与sockaddr结构体保持一致,便于传参的时候进行强制类型转换。
- 为什么不直接填写sockaddr而要填写sockaddr_in再强转是因为sockaddr定义中一个sa_data[14]表示地址信息,不好填入。bind函数里传的是(struct sockaddr*)
- sockaddr_in是专为IPv4设计,但其仍然要传入地址族信息是由于sockaddr的要求,sockaddr中需要地址族信息(其不是为IPv4单独设计)。
5.网络字节序
大端序:先保存高位字节,再保存低位字节(高字节在低地址);
| 内存号 | 0x20号 | 0x21号 | 0x22号 | 0x23号 |
|---|---|---|---|---|
| 存储内容 | 0x12 | 0x34 | 0x56 | 0x78 |
小端序:先保存低位字节,再保存高位字节(高字节在高地址)。
| 内存号 | 0x20号 | 0x21号 | 0x22号 | 0x23号 |
|---|---|---|---|---|
| 存储内容 | 0x78 | 0x56 | 0x34 | 0x12 |
CPU存储时多用小端序(Intel和AMD均是),网络字节序为大端序。
字节序转换函数:htons,htonl,ntohs,ntohl (h代表主机,n代表网络,l代表long,s代表short)。
注:除了向sockaddr_in结构体填充数据外,其余情况无需考虑字节序问题。
6.网络地址初始化与分配
字符串形式的IP地址与32位整数型数据的转换:
#include
in_addr_t inet_addr(const char* s); //成功返回32位大端序整数,失败返回INADDR_NONE
int inet_aton(const char* s, struct in_addr* add) //成功返回1,失败返回0
二者功能相同,inet_addr需要将转换后的IP地址待遇sockaddr_in结构体声明的in_addr结构体变量中。
inet_aton则通过参数自动把结果填入该结构体遍历。
INADDR_ANY可以自动获取IP地址,而不必手动输入。
7.TCP服务器端函数(listen与等待连接请求;accpet与受理连接请求)
#include
int listen(int sock, int backlog); //backlog表示连接请求等待队列的长度
客户端请求连接时,受理之前一直使请求处于等待状态。
#include
int accept(int sock, struct sockaddr* addr, socklen_t* addrlen);
addr保存发起连接请求的客户端地址信息的变量地址值
accept函数受理连接请求队列中待处理的客户端连接请求
函数调用成功后,accept函数内部产生用于数据I/O的套接字,并返回其文件描述符,这个套接字创建时自动的,并自动与发起连接请求的客户端建立连接。
8.TCP客户端函数(connect与请求连接)
#include
int connect(int sock, struct sockaddr* servaddr, socklen_t addrlen);
servaddr保存目标服务器端地址信息
connect在服务器端接收连接请求后返回,但注意这里的接收连接是服务器端把连接请求信息记录到等待队列,所以connect函数返回后并不立即进行数据交换(等待accept)
9.TCP的服务器端/客户端函数调用关系
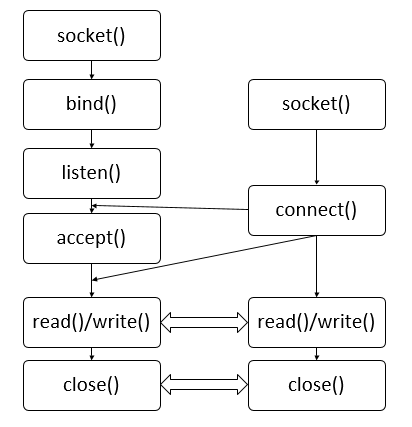
注:客户端只能等到服务器调用listen之后才能调用connect。但是在客户端调用connect之前,服务端可能率先调用accept,这时服务端进入阻塞状态,只到客户端调用connect函数为止。
10.TCP套接字中的I/O缓冲
调用write函数,数据将移到输出缓冲,在适当的时候(不管是分别传送还是一次性传送)传向对方的输入缓冲
调用read函数从输入缓冲读取数据,特性如下:
- I/O缓冲在每个TCP套接字中单独存在
- I/O缓冲在创建套接字时自动生成
- 即使关闭套接字也会继续传递输出缓冲中遗留的数据
- 关闭套接字将丢失输入缓冲中的数据
11.TCP三次握手
在谢希仁著《计算机网络》第四版中讲“三次握手”的目的是“为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”。
在谢希仁著《计算机网络》第四版中讲“三次握手”的目的是“为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”。
三次握手实际上是对通信双方数据原点的序列号达成共识(TCP连接的一方A,由操作系统动态随机选取一个32位长的序列号(Initial Sequence Number)),所以是双向的通道连接确立。
- 如果仅两次连接可能出现一种情况:客户端发送完连接报文(第一次握手)后由于网络不好,延时很久后报文到达服务端,服务端接收到报文后向客户端发起连接(第二次握手)。此时客户端会认定此报文为失效报文,但在两次握手情况下服务端会认为已经建立起了连接,服务端会一直等待客户端发送数据,但因为客户端会认为服务端第二次握手的回复是对失效请求的回复,不会去处理。这就造成了服务端一直等待客户端数据的情况,浪费资源。
12.TCP数据交换过程
主机A:SEQ 1200 , 100 byte data
主机B:ACK 1301
主机A:SEQ 1301 , 100 byte data
主机B:ACK 1402
ACK = SEQ号 + 传递的字节数 + 1,相当于告诉对方,下次要传递的SEQ号
13.TCP的四次挥手
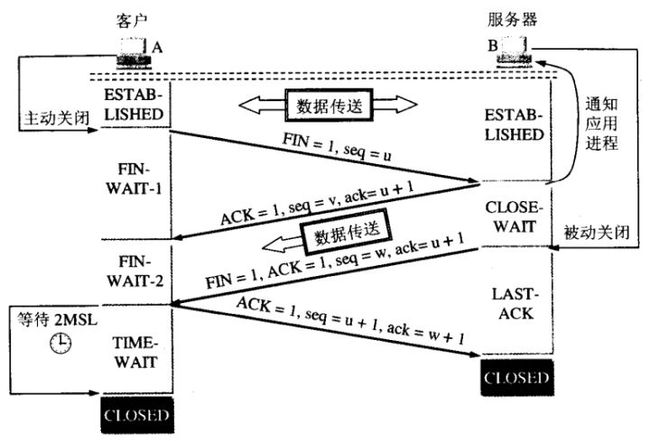
TCP连接是双向的,因此在四次挥手中,前两次挥手用于断开一个方向的连接,后两次挥手用于断开另一方向的连接。
第一次挥手
若A认为数据发送完成,则它需要向B发送连接释放请求。该请求只有报文头,头中携带的主要参数为:
FIN=1,seq=u。此时,A将进入FIN-WAIT-1状态。
- PS1:FIN=1表示该报文段是一个连接释放请求。
- PS2:seq=u,u-1是A向B发送的最后一个字节的序号。
第二次挥手
B收到连接释放请求后,会通知相应的应用程序,告诉它A向B这个方向的连接已经释放。此时B进入CLOSE-WAIT状态,并向A发送连接释放的应答,其报文头包含:
ACK=1,seq=v,ack=u+1。
- PS1:ACK=1:除TCP连接请求报文段以外,TCP通信过程中所有数据报的ACK都为1,表示应答。
- PS2:seq=v,v-1是B向A发送的最后一个字节的序号。
- PS3:ack=u+1表示希望收到从第u+1个字节开始的报文段,并且已经成功接收了前u个字节。
A收到该应答,进入FIN-WAIT-2状态,等待B发送连接释放请求。
第二次挥手完成后,A到B方向的连接已经释放,B不会再接收数据,A也不会再发送数据。但B到A方向的连接仍然存在,B可以继续向A发送数据。
第三次挥手
当B向A发完所有数据后,向A发送连接释放请求,请求头:FIN=1,ACK=1,seq=w,ack=u+1。B便进入LAST-ACK状态。
第四次挥手
A收到释放请求后,向B发送确认应答,此时A进入TIME-WAIT状态。该状态会持续2MSL时间,若该时间段内没有B的重发请求的话,就进入CLOSED状态,撤销TCB。当B收到确认应答后,也便进入CLOSED状态,撤销TCB。
为什么A要先进入TIME-WAIT状态,等待2MSL时间后才进入CLOSED状态?
为了保证B能收到A的确认应答。
若A发完确认应答后直接进入CLOSED状态,那么如果该应答丢失,B等待超时后就会重新发送连接释放请求,但此时A已经关闭了,不会作出任何响应,因此B永远无法正常关闭。
之所以不是三次而是四次主要是因为被动关闭方将"对主动关闭报文的确认"和"关闭连接"两个操作分两次进行。因为客户端有可能还要向服务端发送数据呢。
14.TCP的半关闭
- 单方面断开可能带来的问题:
主机A调用close后,主机B传输给主机A的数据也无法接受 -
include
int shutdown(int sock, int howto);
howto取 SHUT_RD 断开输入流;SHUT_WR断开输出流; SHUT_RDWR同时断开I/O流 - 断开输出流时向对方主机传递EOF。close也会向对方发送EOF,但是无法再接收了
15.IP地址与域名的转换
IP地址比域名发生变更的频率高,利用IP域名编写程序是更好的选择,所以说,程序需要IP地址和域名之间的转换函数。
#include
struct hostent* gethostbyname(const char* hostname);// 成果返回hostent结构体地址,失败返回NULL指针
关于hostent结构体
struct hostent {
char* h_name; // official name
char** h_aliases; //alias list
int h_addrtype; //host address type
int h_length; //address length
char** h_addr_list; //address list
};
最重要的成员是 h_addr_list,可以通过此变量与整数形式保存域名对应的IP地址。用户较多的网站有可能分配多个IP给同一个域名。
h_addr_list指向字符串指针数组,字符串指针数组中的元素实际是in_addr结构体变量的地址值(声明为char而不是in_addr因为hostent不仅仅为IPv4准备)。

16.套接字可选项
获取和更改套接字选项
#include
int getsockopt(int sock, int level, int optname, const void* optval, socklen_t* optlen);
int setsockopt(int sock, int level, int optname, const void* optval, socklen_t* optlen);
sock:用于查看选项套接字的文件描述符;
level:要查看的可选项的协议层。有SOL_SOCKET(套接字相关), IPPROTO_IP(IP相关), IPPROTO_TCP(TCP协议相关)
optname:要查看的可选项名;
optval: 保持查看结果的缓冲地址值;
optlen:optval的缓冲大小。getsockopt调用函数后,保存可选项信息的字节数。
举例:(通过SO_TYPE查看套接字类型)
int sock_type;
int tcp_sock = socket(PF_INET, SOCK_STREAM, 0);
int state = getsockopt(tcp_sock, SOL_SOCKET, SO_TYPE, (void*)&sock_type, &optlen);
if (state) {
error_handling("getsocket() error");
}
else {
printf("SOCKET_STREAM: %d \n", sock_type);
}
SO_SNDBUF & SO_RCVBUF
SO_SNDBUF 是输入缓冲大小相关可选项;SO_REVBUF是输出缓冲大小相关可选项。
用这两个可选项既可以读取当前I/O缓冲大小, 也可以进行修改。(注:修改时不会完全按照请求更改大小)
SO_REUSEADDR 和 Time_wait
在TCP断开连接四次挥手过程中,先断开连接(先发送FIN消息的)主机需要经过Time_wait状态,因此若服务器端先断开连接,则无法立即重新运行,套接字处在Time_wait过程时,相应端口是正在使用的状态,因此,bind函数调用过程会发生错误。
客户端套接字也会经过Time_wait过程,先断开连接的套接字必然经过Time_wait,但是由于客户端套接字的端口号是任意指定的,所以无需考虑。
SO_REUSEADDR可以将Time_wait状态下的套接字端口号重新分配给新的套接字:
int optlen = sizeof(option);
int option = 1;
setcsockopt(serv_sock, SOL_SOCKET, SO_REUSEADDR, (void*)&option, optlen);
Nagle算法与TCP_NODELAY
Nagle算法会最大限度进行缓冲,直到收到ACK,从而保证网络中任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
否则都是小包的话,即使只传输一个字节的数据,其头信息几十个字节,效率低。
“传输大文件数据”,可以考虑金庸Nagle算法,无需等待ACK的前提下连输传输。
禁用方法:将套接字可选项TCP_NODELAY改为1(真)即可
int opt_val = 1;
setsockopt(sock, IPPROTO_TCP, TCP_NODELAY, (void *)&opt_val, sizeof(opt_val));
17.僵尸进程
产生原因:fork函数产生子进程,终止方式有exit或者return,都会传递给操作系统,而操作系统不会销毁子进程,需要父进程主动发起请求,操作系统才会传递返回值,也就是说父进程要负责回收子进程。
销毁僵尸进程:
- wait:成功时返回终止的子进程ID,但是父进程会阻塞直到有子进程终止
- waitpid:
pid_t waitpid(pit_t pid, int * statloc, int options);
options传递 WHOHANG,即使没有终止的子进程也不会进入阻塞状态,而是返回0并退出函数,所以一般需要while循环来检测
18.信号处理
父进程不能只调用waitpid函数以等待子进程终止,解决方案:信号!
#include
void (signal(int signo, void (func)(int)))(int);
函数名:signal
参数:int signo, void (*func)(int)
返回类型: 参数为int, 返回void型 的函数指针
当发生第一个参数中的信号类型时,调用第二个参数所指的函数,也就是信号处理函数
19.fork会复制套接字吗?
调用fork函数时复制父进程的所有资源,但是套接字是属于操作系统的,进程只是拥有代表相应套接字的文件描述符
所以调用fork后,2个文件描述符指向同一套接字
借此可以实现分割TCP I/O程序
20.进程间通信
管道也是属于操作系统的,用来提供给两个进程进行通信。
#include
int pipe(int filedes[2]);
// filedes[0] 通过管道接收数据时使用的文件描述符,即管道出口
// filedes[1] 通过管道发送数据时使用的文件描述符,即管道入口
通过一个管道可以进行双向通信,但是会产生问题!!
数据进入管道后成为无主数据,通过read先读取数据的进程将得到数据,所以有可能读自己发出的数据
解决办法: 创建两个管道负责不同的流
21.I/O复用
比如read和write,通常IO操作都是阻塞I/O的,也就是说当你调用read时,如果没有数据收到,那么线程或者进程就会被挂起,直到收到数据。
select,poll,epoll都是IO多路复用的机制。I/O多路复用(又被称为“事件驱动”)就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。
简单版:提供服务的进程只有一个!
select函数
int select( int maxfd, fd_set* readset, fd_set* writeset, fd_set* exceptset, const struct timeval * timeout);
//maxfd 监视对象文件描述符数量
//readset 监视“是否存在待读取数据”
//writeset 监视“是否可传输无阻塞数据”
//exceptset 监视“是否发生异常”
//timeout,调用select函数后,防止陷入无限阻塞状态,传递超时信息
//返回值:错误返回-1,超时返回0,因发生关注的事件返回时,返回文件描述符数
调用select函数后,第二到第四个参数传递的fd_set变量将发生变化,原来为1的所有位均变为0但发生变化的文件描述符对应位除外,因此,可以认为值仍为1的位置上的文件描述符发生了变化
几大缺点:
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大,向操作系统传递监视对象信息开销大
- 每次调用select都需要在内核遍历传递进来的所有fd
- select支持的文件描述符数量太少,默认1024
22.多种I/O函数
linux中的send&recv
#include
ssize_t send(int sockfd, const void* buf, size_t nbytes, int flags);
//成功返回发送的字节数,失败-1,
ssize_t recv(int sockfd, const void* buf, size_t nbytes, int flags);
//flags 指定的可选项信息
MSG_OOB可选项:用于传输带外数据,比如紧急消息,并不会加快数据传输速度,而是通过单独的通信路径高速传输数据,利用TCP的紧急模式进行传输
readv & writev 函数
对数据进行整合传输及发送的函数,减少I/O函数的调用次数
23.多播与广播
多播是基于UDP的,加入特定组即可接收发往该多播组的数据,多播组地址是D类IP地址,前四位1110,224开头
多播需要借助路由器完成
广播也是一次性向多个主机发送数据,但是只能向同一网络中的主机传输数据
直接广播:192.12.34
本地广播:255.255.255.255
24.套接字与标准I/O
标准I/O函数具有良好的移植性,可以利用缓冲提高性能
fopen feof fgetc fputs
创建套接字返回文件描述符,为了使用标准I/O函数,需要将其转换为FILE结构体指针
#include
FILE * fdopen(int fildes, const char *mode);
//fildes 需要转换的文件描述符 mode : "r" "w"
int fileno(FILE* stream);
//成功时返回转换后的文件描述符
文件描述符的复制和半关闭
可以通过两个FILE指针(读和写)来实现流分离

但是上图中针对任一FILE指针调用fclose函数都会关闭文件描述符,也就终止套接字
所以应该也复制文件描述符,如下图
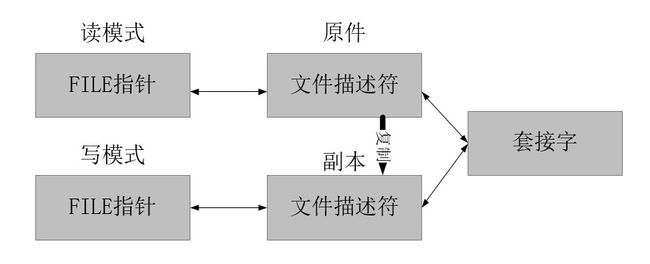
但是还应调用shutdown函数发送EOF并进入半关闭状态,然后fclose对应的FILE指针
复制文件描述符:
include
int dup(nit fildes);
int dup2(int fildes, int fildes2);
//filedes2明确指定的文件描述符整数值
25.优于select的epoll
epoll的优点:
- 无需编写以监视状态变化为目的的针对所有文件描述符的循环语句
- 调用对应于select函数的epoll_wait函数时无需每次传递监视对象信息
epoll_create:创建保存epoll文件描述符的空间
epoll_ctl:注册监视对象文件描述符
#include
int epoll_ctl(int epfd, int op, int fd, struct epol_event * event);
//成功时返回0,失败返回-1
//op用于指定监视对象的添加、删除或更改等操作
//fd 需要注册的监视对象文件描述符
//event 监视对象的事件类型
epoll_wait:最后调用,返回发生事件的文件描述符数,同时在第二个参数指向的缓冲中保存发生事件的文件描述符集合
#include
int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
//events 保存发生事件的文件描述符集合的结构体地址
//maxevents 第二个参数中可以保存的最大时间数量
//等待时间
条件触发和边缘触发
条件触发方式中,只要输入缓冲有数据就会一直通知该事件,只要剩余缓冲中还有数据,就将以事件方式再次注册
边缘触发中,输入缓冲收到数据时仅注册一次该事件
select是以条件触发方式工作的,epoll默认也是条件触发
如果实现边缘触发,那么就不知道输入缓冲是否读完,需要通过errno变量验证错误原因
以阻塞方式工作的read&write函数有可能引起服务器端的长时间停顿,因此需要采用非阻塞read&write
潜台词:read&write默认是阻塞方式工作的
将套接字改为非阻塞方式:
int flag = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flag|O_NONBLOCK);
综上,read函数返回-1,变量errno中的值为EAGAIN时,说明没有数据可读
孰优孰劣?
边缘触发可以分离接收数据和处理数据的时间点,条件触发如果延迟处理数据,则会累积事件
26.线程
多进程模型缺点:
- 创建开销
- 进程间通信开销
- 上下文切换开销
线程为了保持多条代码执行流隔开了栈区域,共享数据区和堆
线程的创建和执行流程:
#include
int pthread_create(pthread_t* restrict thread, const pthread_attr_t* resctrict attr, void*(*start_routine)(void*), void* restrict arg);
//thread 保存新创建线程ID的变量地址值
//attr 传递线程属性的参数
//start_routine 相当于线程main函数,在单独执行流中执行的函数地址值(函数指针)
//arg 通过第三个参数传递调用函数时包含传递参数信息的变量地址值
注意:主函数返回后整个进程将被销毁,可以通过sleep函数向线程提供充足的执行时间,但这会干扰正常执行流
#include
int pthread_join(pthread_t thread, void ** status);
//thread 该参数值ID的线程终止后才会从该函数返回
//status 保存线程的main函数返回值的指针变量地址值
简而言之,调用该函数的进程或线程进入等待状态,直到特定线程终止,而且可以得到返回值
临界区
多个线程访问同一变量,由于不是原子操作,会导致同步问题
临界区即为访问变量的代码语句
互斥量
用来实现线程同步,保护临界区
#include
int pthread_mutex_init(pthread_mutex_t* mutex, const pthread_mutexattr_t* attr);
int pthread_mutex_destroy(pthread_mutex_t * mutex);
//成功返回0,失败返回其他
//mutex 创建互斥量时传递保存互斥量的变量地址
//attr 即将创建的互斥量属性
int pthread_mutex_lock(pthread_mutex_t* mutex);
int pthread_mutex_unlock(pthread_mutex_t* mutex);
信号量
信号量两个操作,P+1,V-1
#include
int sem_post(sem_t* sem);
int sem_wait(sem_t* sem);
//post信号量增1,wait信号量减一
当信号量为0时,调用sem_wait函数,调用函数的线程将进入阻塞状态,此时如果其他线程调用sem_post,信号量的值变为1,而原本阻塞的线程可以将该信号量重新减为0并跳出阻塞状态
一般使用两个信号量,可以使得线程交替按序运行
销毁线程
pthread_join:等待线程终止,销毁线程,但是线程终止前,调用该函数的进程将会进入阻塞状态
pthread_detach:不会引起线程终止或进入阻塞状态