本博客在http://doc001.com/同步更新。
本文主要内容翻译自MySQL开发者Ulf Wendel在PHP Submmit 2013上所做的报告「Scaling database to million of nodes」。翻译过程中没有全盘照搬原PPT,按照自己的理解进行了部分改写。水平有限,如有错误和疏漏,欢迎指正。
本文是系列的第二篇,本系列所有文章如下:
- 百万节点数据库扩展之道(1): 传统关系型数据库
- 百万节点数据库扩展之道(2): NoSQL理论与Amazon Dynamo
- 百万节点数据库扩展之道(3): Google Bigtable
- 百万节点数据库扩展之道(4): Google Spanner
- 百万节点数据库扩展之道(5): NoSQL再讨论
NoSQL理论基础
CAP猜想
CAP猜想由Eric Brewer于2000年提出,其主要结论是,在一个分布式系统中存在无法同时满足的三个保证:连续性(consistency)、可用性(availability)、分区容忍(partition tolerance)。
大规模分布式系统中,节点数量众多,节点上下线频繁,分区容忍是避免管理紊乱的基础。而从用户体验来讲,互联网服务又希望是一直可用的。因此,一致性往往成为牺牲对象。
CAP之一致性
一致性要求分布式系统的所有节点在同一时刻看到相同的数据,这意味着:
- 手段:同一数据的副本进行更新时,以预先协商的顺序执行
- 持久性:所有已向用户确认的更新永远不会丢失
注意区分ACID的一致性和CAP的一致性。ACID中的一致性指的是数据始终处于有效状态,CAP的一致性指的是数据是一样的。
CAP之可用性
可用性意味着,请求不论成功还是失败,都得到确切的回复:
- 手段:即使副本崩溃/失去响应,也不会中断服务
- 性能:如果数据源失效,及时告知客户端,不让其傻等
- Brewer的原始表述是「几乎都能得到回复」
CAP之分区容忍
如果一个分布式系统是分区容忍的,那么任意数量的消息丢失或任意部分的系统失效都不影响系统正常工作。
在一个数据中心内部,机架内核机架间的网络分区很少发生,但是广域网(例如互联网)的网络分区现象非常普遍。
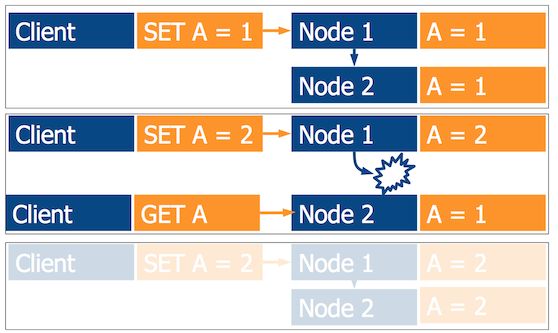
在上图的网络分区示例中,我们无法保证一个客户端能够观察到另外一个分区的客户端更新。我们能做的最佳措施是缓存所有的更新,在分区结束后重新发送它们,最终选取合适的时机合并数据。
CAP定理
CAP猜想在2002年被Gibert和Lynch证明,成为CAP定理。
BASE
关于CAP的讨论催生了BASE理论。BASE推荐使用弱一致模型。BASE的含义是:
- 基本可用(Base Available):可以偶尔不可用
- 软状态(Soft-state):不遵循ACID,就像缓存一样
- 最终一致(Eventual-consistency):有一定的不一致窗口期,但最终达到一致状态
早期的NoSQL趋势
CAP和BASE奠定了NoSQL的理论基础,促使人们变得更为实际,不再去试图发明一个完美的系统,而是针对业务的特定需求构建现实可用的解决方案。
早期的NoSQL存在两个不同的方向,则两个方向的代表系统分别是Amazon Dynamo和Google Bigtable。
Amazon Dynamo等系统使用分布式哈希表(distributed hash table,DHT)组织节点,专注于CAP中的AP。
Google Bigtable及其克隆满足一致性、分区容忍,实际的可用性也非常高(尽管master节点存在单节点故障隐患)。此类系统专注于CAP中的C(A)P。
接下来将对NoSQL领域的重要系统进行介绍。
Amazon Dynamo
分布式哈希表
P2P文件共享系统使用覆盖网(overlay network)提供服务。所谓覆盖网络是指建立在其它网络上的虚拟网络,主要指应用层网络。例如,互联网本身就是建立在底层物理网络上的覆盖网络。在P2P文件系统中,覆盖网络就是由那些共享文件的客户端组成。
不光是P2P系统,任何一个多节点协作的系统所需要的解决的一个核心问题就是路由问题,即怎样才能从一堆节点中找到应该负责处理某个请求的那个特点节点。使用中心节点是最简单的方法,但是当系统规模达到一定程度之后,中心节点的负担会很重,且容易导致单节点故障。
对于这个问题,P2P系统给出的答案就是DHT。DHT将键值空间映射到分布式的节点集合上,每一个节点负责维护键值空间的一个子集。路由协议保证从任意一个节点出发,都能够找到负责指定键值的节点,整个路由过程是完全去中心化的。
著名的DHT包括CAN、Pastry、Chord、Kademlia,它们的区别在于键值空间的形态。CAN是一个多维笛卡尔空间,Pastry是一个路由表,Chord是一个环,Kademlia是一个二叉树。有兴趣的读者可以参阅相关论文。
这些DHT中最优美、简洁的莫过于Chord,它成为了Dynamo的不二选择。
Chord:概述
Chord将网络中的节点组织成一个协作的在线内存系统。客户端通过两个最基本的API——put()和get()——来存储和获取数据。严格地讲,其实只有一种操作,那就是loopup(key):根据指定的键值查找对应的(存储)网络节点。搜索操作的时间复杂度是O(log n),其中n是节点的数量。
Chord是高度可扩展的,所使用的键值映射方法能够确保键值均匀地分布到节点上,达到很好地负载均衡。Chord是完全去中心化的,(几乎)没有特殊的节点,因而不存在单节点故障。更令人兴奋的是,Chord能够主动处理节点加入、失败等网络拓扑变化。
参见学术论文Chord: A scalable peer-to-peer lookup service for internet applications
Chord:虚拟环(virtual ring)
每一个数据根据其内容、所有者等信息计算出一个原始键值。该原始键值进一步被Chord映射为一个哈希键值。默认的算法是SHA1。SHA1返回一个160bit的哈希键值,因此键值空间总共有2^160-1个可用值。如此大的键值空间能够有效地减少冲撞概率。键值空间被组织成一个虚拟环,按照顺时针方向排序。

Chord:节点映射
在Chord中,每一个节点也被映射到和键值空间相同的虚拟环上。节点进行映射的原始键值需要能够区分出不同的节点,例如节点的IP地址就不失为一个好的选择。映射哈希函数的选择非常重要,一个好的哈希函数应该使节点均匀地分布在环上。
在Chord中,数据是这样被分配到每一个节点进行管理的。对于一个键值k,沿着虚拟环顺时针方向(包括k所在位置)找到的第一个节点,称之为它的后继节点,记作successor(k)。键值k被分配给其后继节点进行管理,即每个节点负责管理(上一个节点位置,本节点位置]的键值范围。
原PPT认为「每一个节点负责管理[本节点位置,下一个节点位置)的键值范围。」经查阅Chord原文修正。
Chord:搜索
如果每一个节点只知道自己的前驱节点(逆时针方向邻居)和后继节点(顺时针方向邻居)。仅仅通过这两个节点在Chord中搜索指定的键值,平均需要n/2跳(n是节点总数),太低效了!
Chord通过查找表(lookup table)来加速搜索过程。如果键值空间为m bit,那么每一个节点的查找表包含m个finger pointer。节点n查找表的第i项s是「顺时针方向上与n的距离不小于$2^{i-1}$」的第一个节点,即:
$s=successor((n+2^{i-1}) mod 2^m)$,其中$1<=i<=m$。
在查找过程中,一个节点根据查找表,选择离键值最近的后继finger pointer作为下一跳节点,每次可以将搜索空间减半。整个过程类似于二分查找。
通过缓存查询结果可以进一步加速查找过程。
Chord:副本
数据如果只存储在一个节点上,该节点下线可能造成数据丢失。为此,Chord为同一数据维护$N=log(2^m)$个副本。键值k的数据会被其后继的N个节点(即successor(k)和其后的N-1个节点)保存。

Chord:分区
Chord不限制所有的节点都要在一个位置,事实上,该理论原本就是为地理分布的P2P应用准备的。不论节点是位于同一机房内,还是不同机房间,网络故障都可能导致虚拟环的分区。分区后,Chord的节点加入退出机制导致每个分区的节点形成新的虚拟环。新虚拟环的形成过程完全是自动的,无需运维人员参与。
假设有一个虚拟环,其部分节点在欧洲数据中心,部分在亚洲数据中心。如果两个数据中心之间的网络连接中断,Chord会在每个数据中心形成新的虚拟环。
过了一段时间后,欧洲数据中心和亚洲数据中心的通信恢复,这个时候两个虚拟环需要合并。我们可以指定一些特殊的地标节点。无地标节点的环中的所有节点首先离开它们所在的环,再重新加入到地标节点所在环。一段时间后,整个系统又只剩下唯一的一个虚拟环。
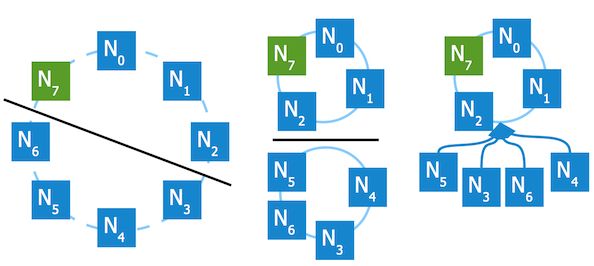
Chord表现强大的节点管理能力,能够在没有中心节点参与的情况下,自动处理网络中的节点故障。Chord的查找效率也很高,能够轻易扩展到很大规模。这些特点是Amazon Dynamo选择Chord的原因。
Amazon Dynamo:风险
Amazon Dynamo选择Chord作为整个系统的基础。
有时候,Dynamo表现出来的行为可能会使开发者困惑。前面提到,Chord会为键值k维护多个副本,Dynamo的情况也是类似。现在,一个副本节点a失去了响应。用户通过put()操作提交了一个新的数据d,该数据在保存的时候跳过了节点a。过了一段时间,节点a重新上线。在节点a同步完数据之前,用户查询数据d,而a节点恰好负责处理这次查询。由于a节点没有数据d,从用户角度看,就好像系统把数据d丢了。
为了降低这种风险,Dynamo后台修复进程会负责不断地将数据迁移到正确地节点上。
Amazon Dynamo:最终一致
Dynamo中的副本数量N是可以配置的。其中,每个键值的直接后继是键值的协调者。
为了加快put()操作的回复速度,协调者使用异步方式同步修改。经过一段时间后,所有副本上的键值才会被更新到最新版本。在这段同步时间内,客户端有可能根本看不到键值,也有可能会读到键值的旧版本。
也就是说,Dynamo是一个弱一致的系统,仅仅保证数据的最终一致性。
Amazon Dynamo:法定人数
Dynamo为每个写操作配置法定人数W(W<=N)。该值的含义是,一个写操作只有成功更新了W个副本,才会被认为操作成功。
同样,读操作也有读法定人数R(R<=N),这是一个读操作需要读取的副本数量。
显然,W、R值越低,操作的速度越快。
举一个简单地例子,如下图所示。假设Dynamo设置副本数量N=4,那么每个写操作需要异步复制到4个副本;W设为2,那么一个写操作只有收到两个确认才认为操作成功;R设为1,那么读操作在读取到一个副本后就立刻返回。现在,进行一次put()操作,紧接着立刻进行一次get()操作。负责响应get()操作的节点恰好还未能完成更新。显然,这次get()操作得到了一个过时的数据。即使我们将R增大到2,还是可能会发生这种状况。

那么,怎样设置R和W的值才能保证读操作总能读到最新的数据呢?答案是,R + W > N。
R + W > N能够保证读操作和写操作有节点交集。也就是,至少有一个节点会被读操作和写操作同时操作到。
R + W > N并不意味着强一致性。考虑一个金融系统,一个用户的账户中有1块钱,N = 4, R = 3, W = 2。现在用户的账户余额增加1,写操作作用到前两个副本C0和C1,这两个副本的账户余额变为2。操作完成后C0和C1系统同时下线了,后两个副本C2、C3尚未应用更新。紧接着用户取出了1块钱,操作作用到C2、C3副本上,这两个副本的账户余额变为0。C0、C1又重新上线,这时用户查询到的账户余额是两个冲突值0、2。哪一个值是正确的?两个值都不正确!
Dynamo并不负责处理这种冲突,而是把这个烫手山芋丢给了客户端。下面将会讲到。
Amazon Dynamo:向量钟(vector clock)
哪种机制适用于Dynamo检测数据的最新版本呢?首先,让我们看一下传统的方案:
-
时钟
大部分情况下,时间戳作为版本号并不是第一选择。云计算环境中既有虚拟机又有物理主机,很难期望这些机器的时钟是完全同步的。如果这些时钟不同步,时间戳很容易导致紊乱。
当然,如果你像Google一样壕一样屌,可以使用原子钟和GPS来提供精确的时间同步(参见Google Spanner)。
版本号
在使用版本号的系统中,每应用一次更新,版本号就会递增。有两种方式来实现版本号递增:第一种方式,是由一台服务器完成所有的更新操作;第二种方式,是由一个全局、单一的服务器产生递增序列。不管哪种方式,都存在单节点故障隐患。
对于Dynamo这样的P2P系统,引入一个负责更新或产生时间戳的节点,违背去中心化的原则。
Dynamo给出的解决方案是向量钟。每一个节点为其管理的每一个数据副本维持一个向量钟。
考虑这样一个场景,一个数据有3个副本N0、N1、N2。我们在N0上进行了一次更新操作,同时,操作被复制到N1。N0在更新时递增了向量钟里的版本号,该向量钟随着被修改的数据一同被发送给其它节点。当其它节点接收到更新,逐项对比本地向量钟和待更新数据的向量钟。如果待更新数据的向量钟的每一项都不小于本地向量钟,那么数据无冲突,新的值可以被接受。Dynamo并不会贸然假定数据的冲突合并准则,而是保留全部的冲突数据,等待客户端处理。

原文是 “If all version stamps are lower than the local ones, there's no conflict. Then, the new value is accepted and the local vector clock is updated.” 应该是一个书写错误。
原文没有描述向量钟的具体格式,给出的示例也是一个简化版本。因此,根据Dynamo论文稍作补充。
向量钟记录同一对象不同版本间的因果关系,实际上是一个(node,counter)列表(即(节点,计数器)列表)。如果第一个向量钟每一个计数器都小于第二个向量钟对应的计数器,那么第二个向量钟是由第一个修改而来的(第一个是第二个的祖先),可以被忽略;否则,这两个向量钟是冲突的,需要协调。一个客户端更新数据时,必须指定它更新的是哪个版本,这个版本由更早的读操作获取。
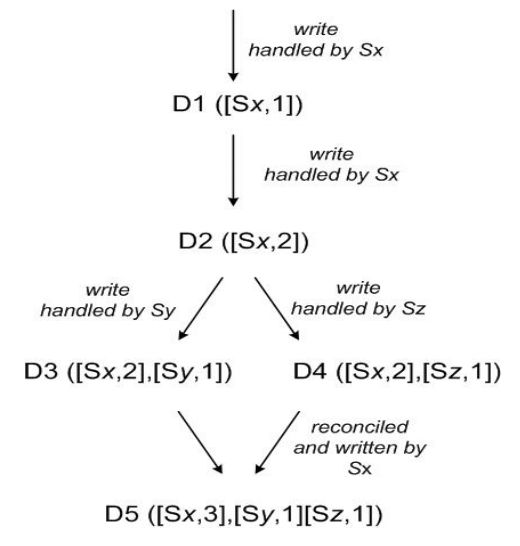
下图给出一个例子。一个客户端写了一个新数据。节点Sx处理了这个请求,创建了数据的向量钟[(Sx,1)]。紧接着,客户端又更新了数据,又是Sx处理了这次更新,向量钟变为[(Sx,2)]。[(Sx,2)]可以安全地覆盖[(Sx,1)],当然这时候其它的副本可能还没看到这次修改,它们的向量钟仍然是[(Sx,1)]。两个客户端同时进行了第二次更新,这两个更新分别被Sy、Sz处理了,Sy、Sz的向量钟变为[(Sx,2),(Sy,1)]和[(Sx,2),(Sz,1)]。实际上,这时候出现了两个冲突的数据版本,Dynamo并不能决定哪个数据是正确地,所以这两个版本都被保存下来。接下来,某个客户端同时读到了这两个版本的数据,可以合写作[(Sx,2),(Sy,1),(Sz,1)]。它进行了数据合并,处理了冲突,提交了新的数据版本[(Sx,3),(Sy,1),(Sz,1)]。这个版本可以安全地覆盖之前的所有旧数据。
Riak
Dynamo不是一个开源系统,而Riak是一个按照Dynamo论文设计的开源分布式键值数据库,使用Apache License 2.0协议发布。单个Riak节点据称每秒能够处理数万请求。考虑到Dynamo的论文已经展示了单集群扩展到数百节点的能力,类似设计的Riak也应该能够做到这一点。
Riak背后的公司是Basho Technologies,其中一位创始人就是Eric Brewer。
Riak的主要特点概括如下:
- 键值存储,按照Dynamo论文构建
- REST风格API、Google Protobuf API
- 客户端支持Java、Python、Perl、PHP、.NET等
- 支持存储各类数据,包括JSON、XML、文本、图片等
- 2.0版本有强一致性选项
- 集群搜索
- MapReduce、全文搜索(基于Solr)
- 二级索引(内存、LevelDB引擎)
- 存储引擎插件
- Bitcast、内存、LevelDB
Riak 2.0引入了「无冲突复制的数据类型CRDT」(conflict-free replicated data type,CRDT)来处理数据冲突,简化系统使用。
CRDT是一类抽象数据类型(abstract data type),它们能够自行解决数据冲突,并达到最终一致状态。换一种说法就是:你可以在这类数据类型上随时进行任何允许的操作,而不用去担心数据冲突,数据冲突的处理将由节点/副本完成。
CRDT背后的把戏其实很简单,这些数据类型要么操作是可以交换的,要么明确规定了冲突情况下应该遵循的规则。例如,Riak的冲突合并规则就是「加操作优先」。
Riak 2.0提供的CRDT包括计数器、集合、map、寄存器、flag等。
举一个例子。假设你在两个节点/副本上保存有一个集合{a}。两个节点被分区后,变成了两个数据版本,分别为{a}、{}。怎样合并冲突呢?首先要明白,导致这种情况的原因有两个,要么在分区前两个集合都是空的,要么在分区后其中一个集合的元素被移走了。Riak通过比较副本维护的向量钟能够区分这两种情况。在这个例子中,第二种情况才是正确的。
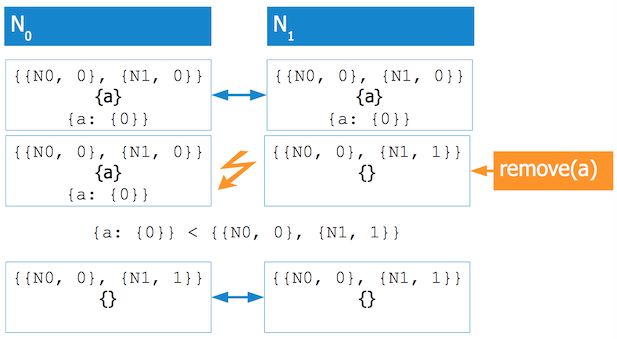
原PPT的这个例子没有很好地体现CRDT,根据Dynamo论文的描述,有{{N0,0},{N1,1}} > {{N0,0},{N1,0}},两个数据其实没有冲突,只是一个较旧而已。
Dynamo及类似系统总结
在CAP语境下,Dynamo是一个极端的AP系统的例子。
Dynamo能够工作在高度不稳定的网络环境下,使用高度不稳定的硬件提供无限的存储空间。整个系统是完全去中心化的,所有的数据都有多个副本。由于没有确保一致性,系统的响应速度很快。系统具备无限扩展的能力。系统最大的缺陷在于需要客户端来修复不一致数据。
Dynamo的数据模型具备以下特点:
- 以字符串为键,二进制数据为值的键值存储
- 提供很少的抽象数据类型,多数是BLOB对象
- 不同的键之间的联系很弱
- 搜索速度取决于键值查找速度和批处理策略
- 分片(sharding)、垂直分区(vertical partitioning)
Dynamo适用场景:
- 简单的模式
- 简单的ad-hoc查询
- 扩展性、可用性是必要需求
Dynamo不适用场景:
- 事务
- 范围扫描
未完待续...
下一部分将介绍另外一种重要的NoSQL,Google Bigtable,参见:
- 百万节点数据库扩展之道(3): Google Bigtable