参考文献如下:
(1) A Context-Sensitive-Chunk BPTT Approach to Training Deep LSTM/BLSTM Recurrent Neural Networks for Offline Handwriting Recognition
(2) Training Deep Bidirectional LSTM Acoustic Model for LVCSR by a Context-Sensitive-Chunk BPTT Approach
(3) Improving Latency-Controlled BLSTM Acoustic Models for Online Speech Recogintion
前言 众所周知,BLSTM是双向的LSTM,它可以同时兼容上下文的信息,从而在一般序列任务上的表现很好。但是BLSTM有一个很致命的弱点,那就是因为有逆向LSTM的存在,它需要有后文的后验,使得它无法在实时的序列任务上也有好的表现。基于实时任务的需求,出现了两种BLSTM的变体——CSC-BLSTM和LC-BLSTM
1. CSC-BLSTM结构解析
CSC-BLSTM结构全名——Context-Sensitive-Chunk Bidirectional Long Short-Term Memory,是BLSTM的第一种改进版本。请看结构图:

CSC-BLSTM首先把序列按照图示的方法分割成多组chunk,除了首尾位置,其他位置处的都是由Nl+Nc+Nr构成,分割的大小事先给定,一般选做30帧+60帧+30帧的模式。
其核心思想在于,Nl用来初始化Nc的前向细胞层状态,Nr用来初始化Nc的后向细胞层状态。Nl和Nr不参与误差反向传播。如下图:

很显然,CSC-BLSTM的这种结构改进可以减小实时任务的延迟,用不着整段话都输入完毕才有结果。但是从整体上看,它是以牺牲计算量为代价的。因为与BLSTM相比,它多出了Nl和Nr上的计算。在此基础之上,为了减少这种计算量,又出现了更加简化了的LC-BLSTM。
2. LC-BLSTM结构解析
LC-BLSTM结构全名——Latency-Controlled Bidirectional Long Short-Term Memory,它改进了CSC-BLSTM。请看结构图:
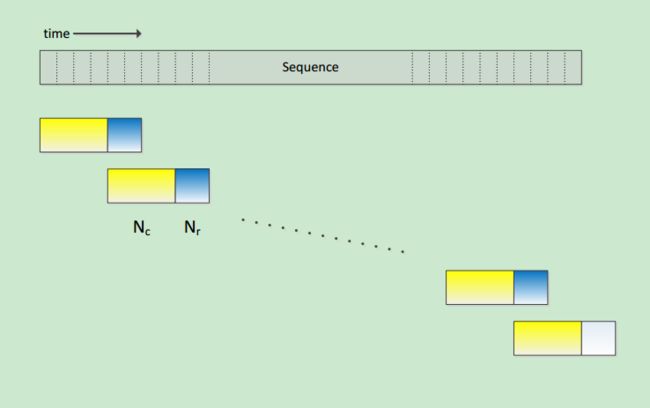
可以发现,相比于CSC-BLSTM,LC-BLSTM取消了Nl,只保留了Nc+Nr。但是如此在计算上必然有差异。
原来,LC-BLSTM的计算也并不复杂,同CSC-BLSTM一样,Nr用来初始化Nc的后向细胞层状态。但是,Nc的前向细胞层状态直接由它的前一个Nc的输出状态得到。这样,相比于CSC-BLSTM,LC-BLSTM避免了Nl的计算量。
But!!!很不幸,通过实验发现,为了保证准确率,LC-BLSTM必须要保证Nr划分的足够大,比如在原论文中,Nc=22的情况下,Nr需要有21,这几乎使得Nr需要有Nc同样的大小。在Nc=Nr=30的情况下,LC-BLSTM的计算量是传统BLSTM的两倍。
3. 改进的LC-BLSTM
通过上述分析,LC-BLSTM的表现依然不好。阿里的研究人员改进了这个结构。他们总结LC-BLSTM的结构,多出来的计算量就在于Nr,但是Nr的作用无非两点:
- 用于初始化当前Nc的后向细胞状态;
- 用做下一层网络的输入(因为正常都会使用多层BLSTM)
于是作者分别采用了两种简化的网络结构代替Nr的BLSTM结构。分别是LC-BLSTM-FABDI和LC-BLSTM-FABSR
3.1 LC-BLSTM-FABDI

首先对于时间轴上正向移动的LSTM,去掉了Nr部分的计算。而对于时间轴上反向移动的LSTM,Nr部分的计算主要是为Nc提供cell的初始状态,作者简化了这部分的计算,使用正向全连接来代替LSTM,将f()的输出取平均后作为Nc的初始状态。
3.2 LC-BLSTM-FABSR

首先对于时间轴上正向移动的LSTM,同样去掉了Nr部分的计算。另外作者发现对于BLSTM模型,时间轴上反向传播的LSTM不如时间轴上正向传播的LSTM重要,因此使用简单RNN模型来代替时间轴上反向传播的LSTM。
但RNN会有梯度爆炸的问题,所以对其进行strict gradient-clipping。同时为了利用未来的信息,加入了target delay。
作者在320小时的Switchboard数据集上进行测试,在不影响wer的情况下,这个两种方法的解码速度分别相对提升40%和27%。