线索解释
一般来说,当提起解释器的时候,大部分人脑海里面浮现出来的模型都是:
while(instruction != null){
switch (instruction) {
case ins1: doSomething1();
case ins2: doSomething2();
...
}
instruction = getNextInstruction();
}
其典型特征就是,在一个主循环里面使用switch来做指令的分派。这种解释器模式被称为译码分派(decode-and-dispatch),使用switch的情况下,也被称为“switch-and-dispatch”。
这种实现方式虽然简单直接,但是其本身在性能上表现十分糟糕。这种模式,最为影响性能的地方就在于指令分派那一步。指令分派需要线性遍历每一条指令,最糟糕的情况下,就是要遍历整个指令集。控制流的转移也会对性能产生很大的影响。在现代处理器上,性能提高的一个很重要因素就是指令预测。然而在这种译码分派模式下,指令预测变得十分困难。
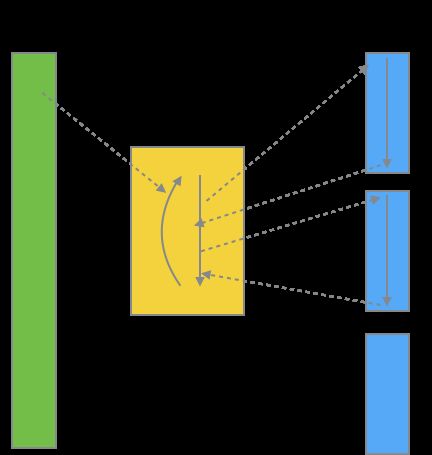
很显然,HotSpot并没有采用这种模式,它采用了一种被称为线索解释(Threaded interpretation)的方法。该方法对于译码分派有一个十分重大的改进:它将跳转地址直接附在了指令之后。如图:

这里的跳转地址,在HotSpot使用模板解释器的情况下,实际上是下一条字节码指令对应的机器码所在的地址。
模板解释器
模板解释器是一个很神奇的东西,它和一般人想的解释是有很大的区别的。按照一般的想法,我们知道HotSpot是利用C++来实现的,那么相当然的就是以为对于每一条字节码指令来说,其对应的解释例程就是一段C++代码。这也是对的,HotSpot早期的解释器就是这样实现的,这种解释器被称为字节码解释器。
但是用C++来解释一条字节码指令,肯定是很低效的。可以想见的是,每一条字节码的执行,都需要很长的一段C++代码。举个例子,add指令的C++实现方法,大概是先访问两次内存(也可以访问一次,而后在分割),将操作数从操作数栈取出来,而后使用C++的加法操作符将其相加,然后再将结果写进去操作数栈。整个过程,至少需要访问两次内存,还需要三个C++局部变量。
为了进一步提高性能,HotSpot使用了模板解释器。模板解释器概念上十分简单,就是每一条字节码指令都对应一个机器码模板。这部分模板被放置在HotSpot的TemplateTable中:
// src/share/vm/interpreter/templateTable.cpp
void TemplateTable::initialize() {
//其余代码,一些变量初始化
// interpr. templates
// Java spec bytecodes ubcp|disp|clvm|iswd in out generator argument
def(Bytecodes::_nop , ____|____|____|____, vtos, vtos, nop , _ );
def(Bytecodes::_aconst_null , ____|____|____|____, vtos, atos, aconst_null , _ );
def(Bytecodes::_iconst_m1 , ____|____|____|____, vtos, itos, iconst , -1 );
def(Bytecodes::_iconst_0 , ____|____|____|____, vtos, itos, iconst , 0 );
//其余指令的定义
// 其余代码
}
机器码生成是在前面代码中的generator那一列被指定的生成器完成的。举例来说,在Bytecodes::_iconst_0的字节码模板定义里面,指定的生成器叫做iconst。因为机器码是依赖于具体的指令集架构的,所以这部分代码放在:
// src/cpu/x86/vm/templateTable_x86_64.cpp
void TemplateTable::iconst(int value) {
transition(vtos, itos);
if (value == 0) {
__ xorl(rax, rax);
} else {
__ movl(rax, value);
}
}
机器码生成
前面我们还提到,HotSpot是依赖于线索解释的,也就是说,在当前字节码指令对应的机器码指令执行完成之后,应该跳转到下一条字节码指令对应的第一条机器码指令的地址上。
要理解这一点,要先回到机器码生成最开始的地方:
// src/share/vm/interpreter/templateInterpreter.cpp
void TemplateInterpreterGenerator::generate_and_dispatch(Template* t, TosState tos_out) {
//其余代码
// generate template
t->generate(_masm);
// advance
if (t->does_dispatch()) {
//...一些代码
} else {
// dispatch to next bytecode
__ dispatch_epilog(tos_out, step);
}
}
最关键就是t->generate(_masm)和dispatch_epilog(tos_out, step)。第一句就是生成该字节码对应的机器码,参数_masm就是汇编生成器。
后面一句则是跳转到了下一条字节码指令那里。事实上,HotSpot第一步的确是找到下一条字节码指令,这是通过将存储现在字节码地址的寄存器的值加上指令长度来实现的。但是HotSpot在执行机器码指令的时候,执行完当前字节码指令的最后一条机器码指令之后,跳转的是下一条字节码指令对应的第一条机器码指令地址。也就是意味着,在生成字节码对应的机器码之后,还要再生成跳转的机器码指令。
我们可以继续追溯这个dispatch_epilog(tos_out, step)方法,直到:
// src/cpu/x86/vm/interp_masm_x86_64.cpp
void InterpreterMacroAssembler::dispatch_base(TosState state,
address* table,
bool verifyoop) {
// ...其余代码
lea(rscratch1, ExternalAddress((address)table));
jmp(Address(rscratch1, rbx, Address::times_8));
}
jmp这一句,就是生成了这条跳转的机器码指令。
关于模板解释器的源码解读,网上有很多的资源,读者可以自行去查找,我这里就不重复前人已经做得很好的工作了