前言
上一节中我们提到了同步异步与阻塞非阻塞的区别,知道了同步并不等于阻塞。而本节的主角NIO是一种同步非阻塞的I/O模型,并且是I/O多路复用模型。NIO在java中被称为 New I/O。它并不能提高I/O处理的效率,注意我这里说的是效率,而从根本上解决的是I/O处理的并发问题。
那么NIO的本质是什么样的呢?它是怎样与事件模型结合来解放线程、提高系统吞吐的呢?
回顾五种I/O模型

由上图可知,所有的系统I/O都分为两个阶段:等待数据和将数据从内核态复制到用户态。
举一个例子,传统的BIO中,当我们要读某块网卡接受到的网络数据的时候,程序会一直阻塞直到有数据到来,在此阶段cpu空转不干活。当监听到有数据的时候,就将数据从内核缓存区copy到用户缓存区,而且这个过程非常快,属于memory copy,带宽通常在1GB/s级别以上,可以理解为基本不耗时。
理解I/O的这两个阶段实际意义尤其的重要。下面讲NIO之前,我们先来深入剖析一下传统同步阻塞式BIO。
同步阻塞式BIO
下面这个伪代码是一个传统BIO模型,它的作用是打印客户端发来的数据并返回数据。
public class SocketServer {
public static void main(String args[]) {
ExecutorService executor = Executors.newFixedThreadPool(100);//线程池
try {
ServerSocket ss = new ServerSocket(8888);
System.out.println("启动服务器....");
while (true) {
//阻塞等待接受客户端连接。
Socket socket = ss.accept();
System.out.println("客户端:" + socket.getInetAddress().getLocalHost() + "已连接到服务器");
executor.submit(new DataHandler(socket));
}
} catch (IOException e) {
e.printStackTrace();
}
}
static class DataHandler implements Runnable {
Socket socket;
public DataHandler(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
//阻塞操作
try {
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String mess = br.readLine();
System.out.println("客户端发来的数据:" + mess);
//返回数据
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bw.write("服务器成功打印日志\n");
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}上诉代码中,总共有三处地方发生了阻塞,第一处是等待客户端连接,第二处是input操作,第三处是output操作。所以该模型必须使用多线程来操作,如果是单线程,系统必将挂死在那里。
对应上述图片,readLine()操作又有如下两个阶段(等待数据和将数据copy到用户缓存中):
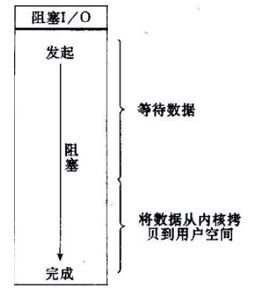
这个模型严格的来说效率是最快的,注意,我说的是效率。但是这种模型有一个缺点就是每当一个客户端发送请求的时候,服务器就会为其创建一个线程,在活动连接数不是特别高(小于1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
但是这个方式的缺点就是,一旦有客户端访问,都创建一个专属的线程去处理,即便有线程池的存在,当并发访问量上来以后,CPU使用率会迅速上升,导致系统几乎陷入不可用的状态。
NIO
接下来我们进入今天的主题:NIO。
如果是你在开发一个基于BIO模型的服务器,发现哪一天系统无法抗住庞大的并发,那么你有什么手段去优化你的服务器呢?
没错,如果你看了之前的章节,那么你的脑海一定会出现多路复用模型,在传统BIO模型中,并发量上限的根本原因就是启动了过多的线程。
对于BIO模型,之所以需要多线程,是因为在进行I/O操作的时候,一是没有办法知道到底能不能写、能不能读,只能”傻等”,即使通过各种估算,算出来操作系统没有能力进行读写,readLine()和write()函数中返回,这两个函数无法进行有效的中断。所以除了多开线程另起炉灶,没有好的办法利用CPU。
NIO的读写函数则可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(readLine()返回0或者write()返回0),我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
多路复用器Selector
当一个客户端请求到来的时候,我们会将其(Channel)注册到Selector上,然后Selector会不断的轮询注册在其上的Channel,如果某个Channel上面发生了读或者写事件,这个Channel就会处于就绪状态,会被Selector轮询出来,然后通过调用方法获取所有就绪Channel的集合,进行后续的操作。
一个多路复用器Selector可以同时轮询多个Channel,由于JDK使用了epoll()(Netty基础系列(1)中有介绍)代替传统的select,所以没有数量1024/2048的上限限制。这也就意味着每一个线程负责Seletor的轮询,就可以接入成千上万个客户端,这确实是非常巨大的进步。
通道Channel
可以将其想象成一个水管,一个客户端的连接成功,可以想象成这根水管一头插入了服务器,一头插入了客户端,它们之间的通信就靠的这根水管。
与传统的流不同,流只能在一个方向是移动(如上述代码,input只能写入,output只能写出)。但是Channel是全双工的,意思是能同时支持读写操作。
缓存区Buffer
在NIO库类中加入了一个Buffer对象。它区别于传统的流,能写入或者将数据直接读到Stream对象中。NIO所有数据都是基于Buffer处理的,在读取数据的时候直接读取Buffer里的数据,写数据的时候直接往Buffer里写数据。任何时候访问NIO中的数据,都是通过缓冲区进行操作的。
通常情况下,操作系统的一次写操作分为两步: 1. 将数据从用户空间拷贝到系统空间。 2. 从系统空间往网卡写。同理,读操作也分为两步: ① 将数据从网卡拷贝到系统空间; ② 将数据从系统空间拷贝到用户空间。
但是值得注意的是,如果使用了DirectByteBuffer(继承Buffer),一般来说可以减少一次系统空间到用户空间的拷贝。但Buffer创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能。
如果数据量比较小的中小应用情况下,可以考虑使用heapBuffer;反之可以用directBuffer。
总结
本章多个角度的解释了NIO,以及NIO的基本组件。
NIO编程的代码博主没有过多的解释,因为对于NIO编程博主也是个小菜鸡。但是!Netty将NIO进行了进一步的封装,让我们能使用更简单,更高效的API来完成我们NIO操作。比直接写NIO更轻松,也不必在意操作系统之间的区别。但是有兴趣的小伙伴可以自行学习NIO编程,然后再体会对比一下与Netty编程实现相同功能的难度与代码量。你就会深深感叹,Netty真他么的强大。
最后再提醒各位一点,使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。