一. XML数据交换格式
XML数据交换格式是一种自描述的数据交互格式,虽然XML数据格式不如JSON "轻便",但也是非常重要的数据交互格式。
-
XML文档的基本结构
XML文档结构要遵守一定的格式规范。XML虽然形式上与HTML很相似,但是它有着严格的语法规则,只有严格按照规范编写的XML文档才是有效的文档,称为“格式良好"(well-formed)的XML文档
先来看几张图



XML文档的基本架构,可以分为下列几个部分:
1 . 声明:如图3-3所示的 就是XML文件的声明,它定义XML文件的版本和使用的字符集,此例为1.0版,使用中文UTF-8 字符。
2 . 根元素:如图3-3所示的note是XML文件的根元素,
3 . 子元素:如图3-3所示的to、content、from和date是根元素note的子元素。所有元素都要有结束标签,开始和结束标签必须一致。如果开始标签和结束标签之间没有内容,可以 写成
4 . 属性:图3-4所示,是具有属性的XML文档。图3-4的XML文档中没有属性,属性是定义在开始标签中的,在开始标签
引号之间。一个元素不能有多个相同名字的属性。
5 . 命名空间:**用于 **一个XML文档中提供名字唯一的元素和属性 **。例如: 在一个学籍信息的XML 文档中需要引用到教师和学生,他们都有一个子元素id,这时候直接引用id元素会造成名称冲突。但是如果将两个id元素放到不同的命名空间中就会解决这个问题。图3 -5 中的“xmIns:”开头的内容,xmIns: xsi="http://www.w3.org/2001/XMLSchema " 等都属于命名空间。
6. ** 限定名:由命名空间引出的概念, 定义了元素和属性的合法标识
符。限定名通常在XML 文档中用作特定元素或属性的引用。图3 -5 中的标签
-
XML文档的解析与框架性能
对于XML文档操作包括了 “读”与“写”,读人 XML 文档 并 分析 的过程称为 “解析”XML 文档; 事实上,在使用XML 开发过程中,“解析”XML 文档工作占很大的比重。
读写XML 文档,目前流行的有两种模式: SAX和 DOM。
SAX 是一种基于事件驱动的解析模式。并不需要读入整个文档,文档的读入过程也就是SAX的解析过程。解析XML的时候,程序从上到下读取XML文档,简单地说就是对XML文档进行顺序扫描,当扫描到 文档 的 开始 与 结束 ,元素(element)的 开始 与 结束 时,就会触发相应的事件处理 函数,由事件处理函数做相应的动作,处理完后继续扫描,直到文档结束,则解析完毕。但是这种解析XML 文件有一个弊端就是只能读取XML文档,不能写人XML 文档。它的优点是解析速度快,iOS重点推荐使用SAX模式解析,而且对内存的要求通常会比较低,特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展功能得到了更好的体现。
DOM是一种基于文档驱动的解析模式 。DOM 需要读入整个XML文档,DOM是将XML 文档作为一棵树状结构进行分析,提供获取节点的内容,以及相关属性,或者新增、删除和修改节点的内容.DOM将XML文件的元素视为树状结构的节点,一次性读入到内存中。如果文档比较大,解析速度就会比较慢,所以对性能和内存的要求比较高。但是DOM模式有一点是SAX无法取代的,就是DOM可以修改XML 文档。
延伸:SAX和DOM的区别
- SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。而且由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上应用程序甚至不必解析整个文档;他可以在某个条件得到满足时停止解析。一般来说,SAX还比它的替代者DOM快许多。另一方面,由于应用程序没有以任何方式存储数据,使用SAX还比它的替代者DOM快许多。另一方面,由于应用程序没有以任何方式存储数据,使用SAX来更改数据或在数据流中往后移是不可能的。
- DOM以及广义的基于树的处理有几个优点首先由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构做出更改。它还可以在任何时候在树中上下导航,而不像SAX那样一次性的处理。DOM使用起来简单的多。
- 选择DOM还是SAX,这取决于以下几个因素:
应用程序的目的;数据容量。 - 对速度的需要:SAX实现通常要比DOM实现更快。
iOS SDK提供了两个的XML框架:
1. NSXML,基于Objective-C语言的SAX解析框架,它是iOS SDK默认的XML解析框架,它不支持DOM模式。
2. libxml2,基于C语言的第三方(http://xmlsoft.org/)提供的SAX解析框架,被苹果整合在iOSSDK中,它支持SAX和DOM模式,所以使用起来相对不太方便,但它同时支持DOM和SAX解析,尤其是它的SAX解析方式很酷,可以边读边解析,非常适用于从网上下载一个很大的XML文件,可极大提供解析效率。
此外,iOS中解析XML还有很多第三方框架可以采用,这些框架主要有:
1. TBXML,是轻量级的DOM模式解析库,有很好的性能和低内存占用,不过它不对XML格式进行校验,不支持XPath,并且只支持解析,不支持对XML进行修改;
2. TouchXML,基于DOM模式解析库,支持XPath,只支持解析,不支持XML的修改;
3. KissXML,基于DOM模式解析库,它是基于TouchXML,主要的不同是可以写如XML文档;
4. TinyXML,基于C++语言的DOM模式解析库,支持对XML的读取和修改,不直接支持XPath,需要借助TinyXPath才可以支持XPath;
5. GDataXML,基于DOM模式解析库,是由Google开发,支持读取和修改XML文档,支持XPath方式查询。
这么多的框架我们选择哪一个呢?解析性能是选择的主要指标,我自己没测试过,别人编写了一个测试程序来测试这些框架测试程序采用GHUnit单元测试框架。
测试文件是MyNotes应用中的XML文档,我准备了10000条Note数据的XML 文档,保存后文件大小达到了1.2M。在第4代iPod touch设备上运行GHUnit测试程序,结果如图3-6所示。

从图3-6中可以看出TBXML框架花费时间最短,TouchXML框架花费时间最长。当然 速度并不能说明一切,还要看看内存占用这个指标。上面的测试程序 还可以进行 内存占用峰值和 执行后驻留内存比较, 内存占用峰值是衡量解析过程中占用的最大内存,它会 影响应用程序当前运行状况,影响是暂时的。而 执行后驻留内存是 衡量解析完成之后内存的驻留情况,它会 影响应用程序运行后的状况,影响是长期的。
使用Xcode自带的Instrument检查工具来检查内存占用情况图3-7所示是Instrument工具运行的结果,我们只需要查看Allocations中的最大值就是内存占用峰值了(图中所示是9.12MB),趋于平稳后的内存就是驻留内存占用了(图中为2.96MB)。

在图3-8中有 内存占用峰值、 执行后驻留内存和 解析时间3个指标的比较。TouchXML应该是最差的了,TBXML虽然是DOM解析模式,但解析速度是最快的,但是内存占用峰值比较高,驻留内存较低。而KissXML和TinyXML也是一个不错的选择,还有 iOS SDK中的NSXML在速度和内存占用都比较优秀,如果这几个指标都想兼顾情况下NSXML是不错的选择。
我们从性能的3个主要指标分析了这7个XML解析框架。当然这是从用户的角度出发,如果从开发人员的角度出发,除了上面的两个指标外,还要关注开发是否方便,以及对于XML文档的读写是否支持等。它们的对比如表3-1所述。

在 iOS下开发一般使用Objctive-C,因此从开发人员的学习曲线角度看,支持Objctive-C的框架是比较s容易使用的。但是如果读者具有C或C++基础的话,这就不是问题了。 XPath是一个不错的技术,用于XML的查询。如果把XML文档看做数据库,那么XPath就相当于SQL查询语言。因此 能够支持XPath的框架,开发起来比较方便,这个 前提是你对于XPath技术比较熟悉。前面分析的都是读取XML文档,如果需要写入XML文档就需要注意了。
- 如果是读取很小的XML文档,性能基本上没有什么差别,不过从调用的方便性来说,建议使用TouchXML、KissXML或GDataXML。
- 如果是需要读取和修改XML文档,建议使用KissXML或GDataXML。
- 如果需要读取非常大的XML文档,则建议使用libxml2或TBXML。
- 如果你不想去调用第三方类库,那么使用NSXML也可以。
-
实例 : MyNotes 应用 XML
其他第三方XML解析框架,可以百度一下
下面通过一个实例介绍NSXML框架解析XML的过程,现在有一个记录我的备忘录信息的Notes. xml文件,内容如下:
2012-12-21
早上8点钟到公司
tony
2012-12-22
发布iOSBook1
tony
2012-12-23
发布iOSBook2
tony
2012-12-24
发布iOSBook3
tony
2012-12-25
发布2016奥运会应用iPhone版本
tony
2012-12-26
发布2016奥运会应用iPad版本
tony
文档中的根元素是Notes,其中有很多子元素Note,每个Note 元素都有一个id 属性(表示“备忘录”的序号),以及3 个子元素CDate (表示“备忘录”的日期).Content(表示“备忘录”的内容)和UserID(表示“备忘录”的创建人ID)。

应用运行画面如图3 9所示。其中的数据来源于本地资源文件中的Notes.xml 文件。我们需要使用NSXMLParser 框架解析XML 文档,并将数据放置于画面表视图中。
1. 使用NSXML
NSXML是iOSSDK 自带的,也是苹果默认解析框架,采用SAX模式解析。它是SAX解析模式的代表。NSXML框架中的核心是NSXMLParser 和它的委托NSXMLParserDelegate。主要的解析工作是在委托协议NSXMLParserDelegate 的实现类中完成的,委托中定义了很多回调方法,在SAX解析器从上图3-9 MyNotes应用设计到下遍历XMI文档的过程中,遇到开始标签、结束标签、文档 原型草图开始、文档结束和字符串就会触发这些方法。这些方法有很多,我们列出5 个常用的:
(1) parserDidStartDocumet,在文档开始的时候触发;
(2) parser:didStartElement :namespaceURI: qualifiedName: attributes,遇到一个开始标签时触发,其中namespaceURI 部分是命名空间,qualifiedName 是:限定名,attributes 是字典类型的属性集合;
(3) parser:foundCharacters,遇到字符串时触发;
(4) parser:didEndElement:namespaceURIqualifiedName,遇到结東标签时出发;
(5) parserDidEndDocument,遇到文档结束时触发。
其中前5个方法都是按照解析文档的顺序触发的,理解它们先后顺序很重要,可以通过图3 -10所示的UML时序图了解它们的触发顺序。
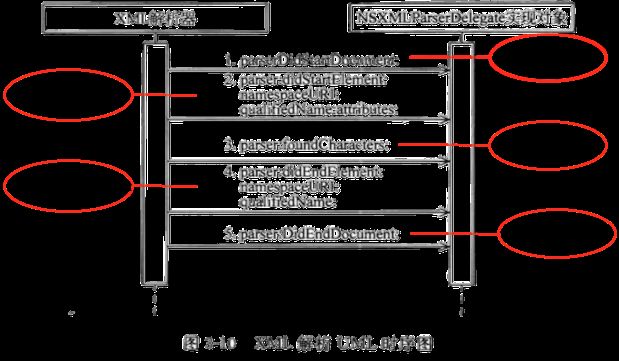
就同一个元素而言触发顺序是按照图3-10所示进行的,在整个解析过程中它们的触发次数是: 1方法和5 方法为一对,都只触发1次,2 方法和4 方法为一对,都触发多次,3方法是在2 方法和4 方法之间触发它也会多次触发, 触发的字符包括了换行符和回车符等特殊字符串,在编程时需要注意。
编写了一个专门解析类NotesXMLParser,
NotesXMLParser.h 文件代码如下:
#import
@interface NotesXMLParser : NSObject
//解析出的数据内部是字典类型
@property (strong,nonatomic) NSMutableArray *notes;
//当前标签的名字
@property (strong,nonatomic) NSString *currentTagName;
//开始解析
-(void)start;
@end
NotesXMLParser 实现NSXMLParserDelegate 协议,还定义了currentTagName 属性的目的是在图3 -10所示的2 方法到4 方法执行期间临时存储正在解析的元素名,在3 方法(parser:foundCharacter )触发时,能够知道目前解析器处于哪个元素之中。
NotesXMLParser.m 中的start 方法代码如下
-(void)start
{
NSString* path = [[NSBundle mainBundle] pathForResource:@"Notes" ofType:@"xml"];
NSURL *url = [NSURL fileURLWithPath:path];
//开始解析XML
NSXMLParser *parser = [[NSXMLParser alloc] initWithContentsOfURL:url];
parser.delegate = self;
[parser parse];
NSLog(@"解析完成...");
}
NSXMLParser是解析类,它有 3 个构造方法:
1.initWithContentsOfURL,可以使用URL 对象创建解析对象,本例中采用的是该方法,先从资源文件中加载获得URI对象,再使用URL对象构建解析对象;
- initWithData,可以使用NSData 创建解析对象;
- initWithStream,可以使用IO 流对象创建解析对象。
解析对象创建好后需要指定委托属性delegate为self,然后发送parse消息,开始解析文档。
NotesXMLParser.m 中 的方法代码如下:
/**
文档开始的时候触发
只在解析开始时 触发一次 ,因此可以在这个方法中 初始化解析过程中用到的一些 成员变量
@param parser 解析对象
*/
- (void)parserDidStartDocument:(NSXMLParser *)parser
{
_notes = [NSMutableArray new];
}
/**
文档出错的时候触发
@param parser 解析对象
@param parseError 解析错误
*/
- (void)parser:(NSXMLParser *)parser parseErrorOccurred:(NSError *)parseError
{
NSLog(@"%@",parseError);
}
/**
遇到一个开始标签时候触发
@param parser 解析对象
@param elementName 表示正在解析的元素的名字
@param namespaceURI 部分是命名空间
@param qualifiedName 限定名
@param attributeDict 字典类型的属性集合
*/
- (void)parser:(NSXMLParser *)parser didStartElement:(NSString *)elementName
namespaceURI:(NSString *)namespaceURI
qualifiedName:(NSString *)qualifiedName
attributes:(NSDictionary *)attributeDict
{
_currentTagName = elementName;//需要把elementName参数赋值给成员变量_currentTagName
if ([_currentTagName isEqualToString:@"Note"]) {
NSString *_id = [attributeDict objectForKey:@"id"];//从字典中取出id属性
NSMutableDictionary *dict = [NSMutableDictionary new];//实例化一个可变字典对象,用来存放解析出来的Note元素数据,成功解析之后字典中应该有4对数据,即id、CDate、Content和UserID
[dict setObject:_id forKey:@"id"];//把id放人可变字典中
[_notes addObject:dict];//把可变字典放人到可变数组集合_ notes 变量中
}
}
/**
遇到字符串时候触发,该方法是解析元素文本内容主要场所
@param parser 解析对象
@param string 字符串
,由于换行符和回车符等特殊字符也会触发该方法,因此在第①行是用剔除换行符和回车符,其中stringByTrimmingCharactersInSet:方法是剔除字符方法,[NSCharacterSet whitespaceAndNewlineCharacterSet]指定字符集为换行符和回车符。
*/
- (void)parser:(NSXMLParser *)parser foundCharacters:(NSString *)string
{
//替换回车符和空格
/*
由于换行符和回车符等特殊字符也会触发该方法,因此在第①行是用剔除换行符和回车符,
其中stringByTrimmingCharactersInSet:方法是剔除字符方法,[NSCharacterSet whitespaceAndNewlineCharacterSet]指定字符集为换行符和回车符。
*/
string =[string stringByTrimmingCharactersInSet:[NSCharacterSet whitespaceAndNewlineCharacterSet]];
if ([string isEqualToString:@""]) {
return;
}
NSMutableDictionary *dict = [_notes lastObject];
if ([_currentTagName isEqualToString:@"CDate"] && dict) {
[dict setObject:string forKey:@"CDate"];
}
if ([_currentTagName isEqualToString:@"Content"] && dict) {
[dict setObject:string forKey:@"Content"];
}
if ([_currentTagName isEqualToString:@"UserID"] && dict) {
[dict setObject:string forKey:@"UserID"];
}
}
/**
遇到结束标签时候出发
在该方法中主要是清理刚刚解析完成的元素产生的影响,以便于不影响接下来的解析
@param parser 解析对象
@param elementName 表示正在解析的元素的名字
@param namespaceURI 部分命名空间
@param qName 限定名
*/
- (void)parser:(NSXMLParser *)parser didEndElement:(NSString *)elementName
namespaceURI:(NSString *)namespaceURI
qualifiedName:(NSString *)qName;
{
self.currentTagName = nil;//在该方法中主要是清理刚刚解析完成的元素产生的影响,以便于不影响接下来的解析
}
/**
遇到文档结束时候触发
该方法就意味着解析完成,需要清理一些成员变量,同时要将数据返回给表示层
(表视图控制器),我们使用了通知机制将数据通过广播通知投送回表示层。
@param parser 解析对象
*/
- (void)parserDidEndDocument:(NSXMLParser *)parser
{
[[NSNotificationCenter defaultCenter] postNotificationName:@"reloadViewNotification" object:self.notes userInfo:nil];
self.notes = nil;
}
表示层的主要代码:
- (void)viewDidLoad
{
[super viewDidLoad];
[[NSNotificationCenter defaultCenter] addObserver:self
selector:@selector(reloadView:)
name:@"reloadViewNotification"
object:nil];
NotesTBXMLParser *parser = [NotesTBXMLParser new];
//开始解析
[parser start];
}
#pragma mark - 处理通知
-(void)reloadView:(NSNotification*)notification
{
NSMutableArray *resList = [notification object];
self.listData = resList;
[self.tableView reloadData];
}
二. JSON数据交换格式
JSON数据交换格式是一种轻量级的数据交换格式。所谓的轻量级与XML文档结构相比而言,描述项目字符少,所以描述相同的数据的所需字符个数要少,那么传输的速度就会提高而流量也会减少。
由于
-
JSON的文档结构
构成JSON 文档两种结构: 对象和数组。
对象是 “名称-值”对 集合,它类似于Objective-C 中的字典类型。
数组是一连串元素的集合。
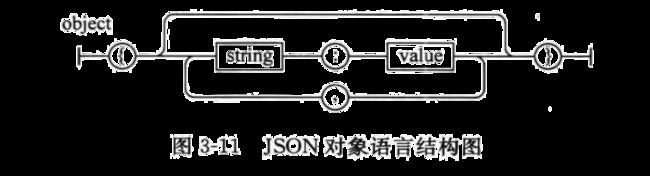
对象是一个无序的“名称/值”对集合,一个对象以“{”(左括号)开始,“}”(右括号)结束。每个“名称”后跟一个“:”(冒号),“名称-值”对之间使用“,”(逗号)分隔,JSON 对象语法表如图3-11所示。
下面是一个JSON的对象例子:
{
"name" :"a.htm",
"size" :345,
"saved" :true
}
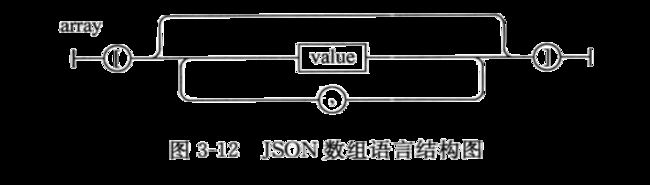
数组是一个值的有序集合,一个数组以“[”(左中括号)开始,“]”(右中括号)结束,值之间使用“,”(逗号)分隔,JSON数组语法表如图3-12所示。
下面是一个JSON的数组例子:
["text","html","css"]
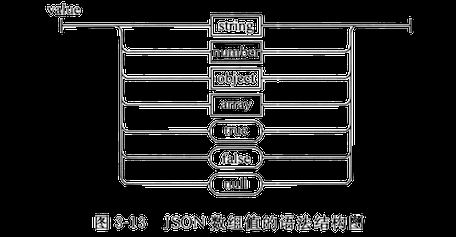
在数组中值可以是双引号括起来的字符串、数值、true、false、null、对象或者数组,而且这些结构可以嵌套,数组中值的JSON语法结构图3-13所示。
-
JSON的文档的解析与框架性能
把数据写成JSON结构过程称为“编码”过程,即写入过程。把数据从JSON文档中读取处理的过程称为“解码”过程,即解析和读取过程。
由于JSON基本比较成熟,在iOS平台上也会有很多框架可以进行JSON的编码/解码。这些框架包括:
- SBJson是比较老的JSON编码/解码框架,原名是json-framework,这个框架现在更新仍然很频繁,支持ARC。
- TouchJSON也是比较老的JSON编码/解码框架,支持ARC和MRC
- YAJL是比较优秀的JSON框架,它基于SBJson,里面进行了优化,底层API使用C编写,上层API是Objective-C编写,使用者可以有多种不同的选择。它不支持ARC。
- JSONKit 是更为优秀的JSON框架,它的代码很小,但是解码速度很快,不支持ARC,源码下载地址https://github.com/johnezang/JSONKit。
- NextiveJson 也是非常优秀的JSON框架,它与JSONKit性能差不多,但是在开源社区中没有JSONKit 知名度高,不支持ARC,源码下载地址https://github.com/nextive/NextiveJson。
- NSJSONSerialization 是iOS5 之后苹果提供的API,它是目前非常优秀的JSON编码/解码框架,支持ARC,iOS5之后的SDK就已经包含了,不需要额外的安装和配置,这是它的另外一个优点。但是如果你的应用要兼容iOS5 之前的版本这个框架不能使用。
为了解析这些框架的性能,我们可以参照XML为了解析这些框架的性能,我们可以参照XML实现MyNotes 应用,我准备了10000 条Note 数据的JSON 文档,保存后文件大小达到了700KB,而同样信
息的XML文档是1.2M,这也印证JSON是轻量级的数据交互格式。同样是在第4 代iPod touch设备上运行GHUnit测试程序,结果如图3-14 所示。

从图中可以看出苹果提供的NSJSONSerialization 框架花费时间最短,TouchJSON 和SBJson框架花费时间基本上最长。我们再来看看内存占用指标,使用Instrument 检查工具来检查内存占用情况,最后将内存占用峰值、驻留内存占用和上面的解码花费时间,一起绘制成如图3-15所示的图表。
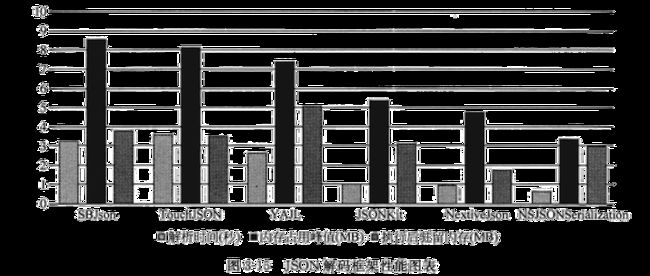
在该图表中有内存占用峰值、执行后驻留内存和解析时间3 个指标的比较。TouchJSON和SBJson应该是很差的,事实上SBJson 在iOS 5 之前的用户很多。NSJSONSerialization 是解
码速度最快的,内存占用峰值是最低的,可见NSJSONSerializatio是一个非常优秀的JSON解码框架,但是它的执行后驻留内存却比Nextivelson要高, NextiveJson解码速度也是比较快的,内存峰值要比NSJSONSerialization略高一些。
事实上,执行后驻留内存多少对于应用程序的影响是比较大的,而且是长期的影响,这些内存不经过特殊释放就会一直保持在那里。它们将伴随整个应用程序生命周期,直到应用被终止才被释放,对于整个设备都会有比较大的影响。
因此,综合考虑,如果需要考虑兼容iOS5之前的版本,NextiveJson和JSONKit都是不错的选择。它们都不支持ARC,使用起来有点麻烦,需要安装和配置到工程环境中。
-
实例: MyNotes应用JSON解码
上一节从性能的3个主要指标分析了这6个JSON编码/解码框架。这一节介绍一下NSJSONSerialization如何实现JSON的解码的。实例还是采用MyNote应用,重新设计数据结构为JSON格式,备忘录信息的Notes. json文件,它的内容如下:
{"ResultCode":0,
"Record":[
{"ID":"1","CDate":"2012-12-23","Content":"发布iOSBook0","UserID":"tony"},
{"ID":"2","CDate":"2012-12-24","Content":"发布iOSBook1","UserID":"tony"},
{"ID":"3","CDate":"2012-12-25","Content":"发布iOSBook2","UserID":"tony"},
{"ID":"4","CDate":"2012-12-26","Content":"发布iOSBook3","UserID":"tony"},
{"ID":"5","CDate":"2012-12-27","Content":"发布iOSBook4","UserID":"tony"}
]
}
注意:在上面介绍的6个框架中对于JSON文档的结构要求比较严格,每个JSON数据项目“名称”必须使用双引号括起来,不能使用单引号或没有引号,如下代码文档中“名称”省略双引号,该文档在iOS平台解析时会出现异常,而在Java等其他平台就没有这些限制,也不会出现异常,而我们的JSON数据很多情况下编码和解码并非是一种语言的。
{ResultCode:0,
Record:[
{ID:'1',CDate:'2012-12-23',Content:'发布iOSBook0',UserID:'tony'},
{ID:'2',CDate:'2012-12-24',Content:'发布iOSBook1',UserID:'tony'}
]
}
JSON的解码过程就是将字符串,分析之后读入到一个集合对象中,这个集合对象的结构可能是数组,也可能是字典。Notes. json解码之后整个的结构是一个字典,这个字典有两个“名字值”,与Record名字对应的值是一个数组,而数组中的每一个元素又是一个字典对象。取得其中的内容也相似“剥洋葱皮”。
使用NSJSONSerialization实现解码过程是非常简单的,因为简单,所以没有必要再为解码单独创建一个类,直接使用就可以了。
- (void)viewDidLoad
{
NSString* path = [[NSBundle mainBundle] pathForResource:@"Notes" ofType:@"json"];
NSData *jsonData = [[NSData alloc] initWithContentsOfFile:path];
NSError *error;
/*
使用NSJSONSerialization的类方法JSONObjectWithData: options; error;进行解码其中options参数指定了解析JSON模式,它是枚举类型NSJSONReadingOptions中定义了三个常量:
(1) NSJSONReadingMutableContainers,指定解析返回的是可变的数组或字典,如果以后需要修改结果,这个常量是合适的选择;
(2) NSJSONReadingMutableLeaves,指定叶节点是可变字符串;
(3) NSJSONReadingAllowFragments,指定顶级节点可以不是数组或字典。
此外,NSJSONSerialization还提供了JSON编码的方法: dataWithJSONObject;options:error:和writeJSONObject; toStream; options:error:,关于JSON的编码方法的使用与解码非常类似
*/
id jsonObj = [NSJSONSerialization JSONObjectWithData:jsonData
options:NSJSONReadingMutableContainers error:&error];
if (!jsonObj || error) {
NSLog(@"JSON解码失败");
}else{
self.listData = [jsonObj objectForKey:@"Record"];
//然后处理数据和刷新界面
}
}
JSON是轻量级的数据交换格式,在应用开发时候优先考虑使用JSON而不是XML。XML的最优解析框架是TBXML,JSON的最优解码框架是NSJSONSerialization。
-
总结
XML与JSON两种数据结构的优缺点
- XML
优点:
- 格式统一, 符合标准
- 容易与其他系统进行远程交互, 数据共享比较方便
缺点:
XML文件格式文件庞大, 格式复杂, 传输占用带宽
服务器端和客户端都需要花费大量代码来解析XML, 不论服务器端和客户端代码变的异常复杂和不容易维护
客户端不同,浏览器之间解析XML的方式不一致, 需要重复编写很多代码
服务器端 和 客户端 解析XML花费资源和时间
- JSON
优点:
数据格式比较简单, 易于读写, 格式都是压缩的, 占用带宽小
易于解析这种语言
支持多种语言, 包括ActionScript, C, C#, ColdFusion, Java, JavaScript, Perl, PHP, Python, Ruby等语言服务器端语言, 便于服务器端的解析
因为JSON格式能够直接为服务器端代码使用, 大大简化了服务器端和客户端的代码开发量, 但是完成的任务不变, 且易于维护
缺点:
- 没有XML格式这么推广的深入人心和使用广泛, 没有XML那么通用性
- JSON格式目前在Web Service中推广还属于初级阶段
XML和JSON的优缺点对比
- 可读性方面
JSON和XML的数据可读性基本相同,JSON和XML的可读性可谓不相上下,一边是建议的语法,一边是规范的标签形式,XML可读性较好些。 - 可扩展性方面
XML天生有很好的扩展性,JSON当然也有,没有什么是XML能扩展,JSON不能的。都具有很好的扩展性。 - 编码难度方面
XML有丰富的编码工具,比如Dom4j、JDom等,JSON也有json.org提供的工具,但是JSON的编码明显比XML容易许多,即使不借助工具也能写出JSON的代码,可是要写好XML就不太容易了。相对而言:JSON的编码比较容易。 - 解码难度方面
json解码难度基本为零,xml需要考虑子节点和父节点。 - 传输速度方面
JSON的速度要远远快于XML - 流行度方面
XML已经被业界广泛的使用,而JSON才刚刚开始,但是在Ajax这个特定的领域,未来的发展一定是XML让位于JSON。到时Ajax应该变成Ajaj(Asynchronous Javascript and JSON)了。 - 解析手段方面
JSON和XML同样拥有丰富的解析手段。 - 数据体积方面
JSON相对于XML来讲,数据的体积小,传递的速度更快些。 - 数据交互方面
JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互。 - 数据描述方面
JSON对数据的描述性比XML较差。
-
XML与JSON数据格式比较
关于轻量级和重量级
轻量级和重量级是相对来说的,那么XML相对于JSON的重量级体现在哪呢?应该体现在解析上,XML目前设计了两种解析方式:DOM和 SAX。
- DOM
DOM是把一个数据交换格式XML看成一个DOM对象,需要把XML文件整个读入内存,这一点上JSON和XML的原理是一样的,但是XML要考虑父节点和子节点,这一点上JSON的解析难度要小很多,因为JSON构建于两种结构:key/value,键值对的集合;值的有序集合,可理解为数组; - SAX
SAX不需要整个读入文档就可以对解析出的内容进行处理,是一种逐步解析的方法。程序也可以随时终止解析。这样,一个大的文档就可以逐步的、一点一点的展现出来,所以SAX适合于大规模的解析。这一点,JSON目前是做不到得。
所以,JSON和XML的轻/重量级的区别在于:
JSON只提供整体解析方案,而这种方法只在解析较少的数据时才能起到良好的效果;
XML提供了对大规模数据的逐步解析方案,这种方案很适合于对大量数据的处理。
关于数据格式编码及解析难度
在编码方面。
虽然XML和JSON都有各自的编码工具,但是JSON的编码要比XML简单,即使不借助工具,也可以写出JSON代码,但要写出好的XML代码就有点困难;与XML一样,JSON也是基于文本的,且它们都使用Unicode编码,且其与数据交换格式XML一样具有可读性。
主观上来看,JSON更为清晰且冗余更少些。JSON网站提供了对JSON语法的严格描述,只是描述较简短。从总体来看,XML比较适合于标记文档,而JSON却更适于进行数据交换处理。在解析方面。
在普通的web应用领域,开发者经常为XML的解析伤脑筋,无论是服务器端生成或处理XML,还是客户端用 JavaScript 解析XML,都常常导致复杂的代码,极低的开发效率。
实际上,对于大多数Web应用来说,他们根本不需要复杂的XML来传输数据,XML宣称的扩展性在此就很少具有优势,许多Ajax应用甚至直接返回HTML片段来构建动态Web页面。和返回XML并解析它相比,返回HTML片段大大降低了系统的复杂性,但同时缺少了一定的灵活性。同XML或 HTML片段相比,数据交换格式JSON 提供了更好的简单性和灵活性。在Web Serivice应用中,至少就目前来说XML仍有不可动摇的地位。实例比较
XML和JSON都使用结构化方法来标记数据,下面来做一个简单的比较。
中国
黑龙江
哈尔滨
大庆
广东
广州
深圳
珠海
台湾
台北
高雄
新疆
乌鲁木齐
用JSON表示中国部分省市数据如下
{
name: "中国",
provinces: [
{ name: "黑龙江", citys: { city: ["哈尔滨", "大庆"]} },
{ name: "广东", citys: { city: ["广州", "深圳", "珠海"]} },
{ name: "台湾", citys: { city: ["台北", "高雄"]} },
{ name: "新疆", citys: { city: ["乌鲁木齐"]} }
]
}
编码的可读性来说,XML有明显的优势,毕竟人类的语言更贴近这样的说明结构。JSON读起来更像一个数据块,读起来就比较费解了。不过,我们读起来费解的语言,恰恰是适合机器阅读,所以通过JSON的索引country.provinces[0].name就能够读取“黑龙江”这个值。
编码的手写难度来说,XML还是舒服一些,好读当然就好写。不过写出来的字符JSON就明显少很多。去掉空白制表以及换行的话,JSON就是密密麻麻的有用数据,而XML却包含很多重复的标记字符。
参考文献:
JSON与XML的区别比较
IOS网络编程与云端应用最佳实践.pdf