作者的设计思路和细节参看这里:YYCache 设计思路
YY给我印象最深的是他做事的方式,文章里写到他调研了多个相关的库,包括开源和闭源的。按照他一贯的风格,有性能评测。不过这次咋没有单元测试呢?:)
我简单了画了一张类图,(原谅我笨拙的Keynote技能,我自己已经不能容忍了,已将Keynote学习列入日程。)
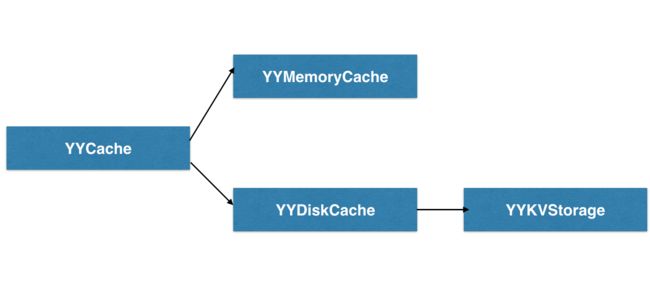
缓存YYCache包括两层
内存缓存
磁盘缓存
他们可以单独使用,也可以组合使用。
内存缓存基于双向链表和字典实现的。考虑到缓存的局部性,性能接近O(1).
磁盘缓存同时使用了文件和数据库的方式,根据测试的结果,sqlite的写入性能高于文件写入,但是读取性能,在读大文件是(根据内存页设置不同,值会不一样,这个值在20K左右),性能低于文件读。所以数据中只存了文件的名称。将文件的实际内容写在磁盘上。
这里有个典型的应用是网络图片库的下载,用到内存+磁盘的两级缓存,因为图片一般不会小,也将图片保存在磁盘上。在作者的YYWebImage库里也用到了这个缓存库。
留有的疑问
Open-sourcing PINCache(多线程同步问题)
https://engineering.pinterest.com/blog/open-sourcing-pincache
问题:("TMMemoryCache 在设计时,主要目标是线程安全,它把所有读写操作都放到了同一个 concurrent queue 中,然后用 dispatch_barrier_async 来保证任务能顺序执行。"
barrier准确的说应该是保证被包裹的代码块在并发队列中执行时的独占性,就如同跑在串行队列中一样,不知道这样说对不对。
还有想请教一点:它错误的用了大量异步 block 回调来实现存取功能,以至于产生了很大的性能和死锁问题,这个能否多解释一下?)
提问者的回答
“看了PinCache 的源码明白了,PinMemoryCache 同步读的时候,是真正的同步读,并且用信号量控制了同步读在并发队列的并行量;而 TMMemCache的同步读,其实是用信号量将异步变成了同步,但是会存在并发队列忙碌时,无法执行回调发信号造成死锁。”
思维很严密,该做判断的地方都判断到了。代码只有想清楚才能写清楚!要不然,写多少测试用例都没用,不知道做到了多少才是合适的,不多也不少。
- (BOOL)saveItemWithKey:(NSString*)key value:(NSData*)value filename:(NSString*)filename extendedData:(NSData*)extendedData {
if(key.length== 0 || value.length== 0)returnNO;
if(_type==YYKVStorageTypeFile&& filename.length== 0) {
returnNO;
}
if(filename.length) {
if(![self_fileWriteWithName:filenamedata:value]) {
returnNO;
}
if(![self_dbSaveWithKey:keyvalue:valuefileName:filenameextendedData:extendedData]) {
[self_fileDeleteWithName:filename];
returnNO;
}
returnYES;
}else{
if(_type!=YYKVStorageTypeSQLite) {
NSString*filename = [self_dbGetFilenameWithKey:key];
if(filename) {
[self_fileDeleteWithName:filename];
}
}
return[self_dbSaveWithKey:keyvalue:valuefileName:nilextendedData:extendedData];
}
}