之前强化学习理论给予了神经科学以灵感和启发:
最近在理解奖励驱动学习所涉及的机制方面取得了令人振奋的进展。这一进展部分是通过输入强化学习领域(RL)的思想来实现的。最重要的是,这种输入导致了基于RL的多巴胺能功能理论。在这里,相位多巴胺(DA)释放被解释为传达奖励预测误差(RPE)信号,这是在时间差RL算法中集中计算的意外指数。根据该理论,RPE驱动纹状体中的突触可塑性,将经验丰富的动作
- 奖励关联转化为优化的行为政策。在过去二十年中,该提案的证据稳步增加,将其作为奖励驱动学习的标准模型。
近期神经科学在前额皮质(PFC)的研究有了新发现又可以反过来指引RL:
前额皮质(PFC)研究引发了一个窘境。越来越多的证据表明,PFC实施了基于奖励的学习机制,执行与基于DA的RL相似的计算。它早已确立
PFC的各个部分代表着行动,对象和状态的期望值。最近,PFC中也出现了最近的行动和奖励的历史序列。编码的变量集以及关于PFC中神经激活的时间分布的观察结果得出结论:“PFC神经元动态[编码]转换来自奖励和
选择的历史
到对象值,从对象值到对象选择“。简而言之,PFC中的神经活动似乎反映了一组操作,它们共同构成了一个独立的RL算法。在DA旁边放置PFC,我们获得了一个包含两个完整RL系统的图片,一个利用基于活动的表示,另一个是有关突触的学习。
接下来,看这两个基于DA和PFC的强化学习如何整合:
他俩系统之间有什么关系?如果两者都支持RL,那么它们的功能是多余的?一个建议是DA和PFC提供不同形式的学习,其中DA实现基于直接刺激 - 响应关联的无模型RL,而PFC执行基于模型的RL,其利用任务结构的内部表示。然而,这种双系统视图的一个明显问题是重复观察到DA预测误差信号是由任务结构告知的,反映了“推断的”和“基于模型的”值估计很难与原始框架的标准理论。
论文中几个实验通过这个框架达到了他们各自的任务目的,下面具体地,由论文的simulation4来讲解一下,这是一个什么样的任务,又用什么样的架构解决了这个任务的问题:
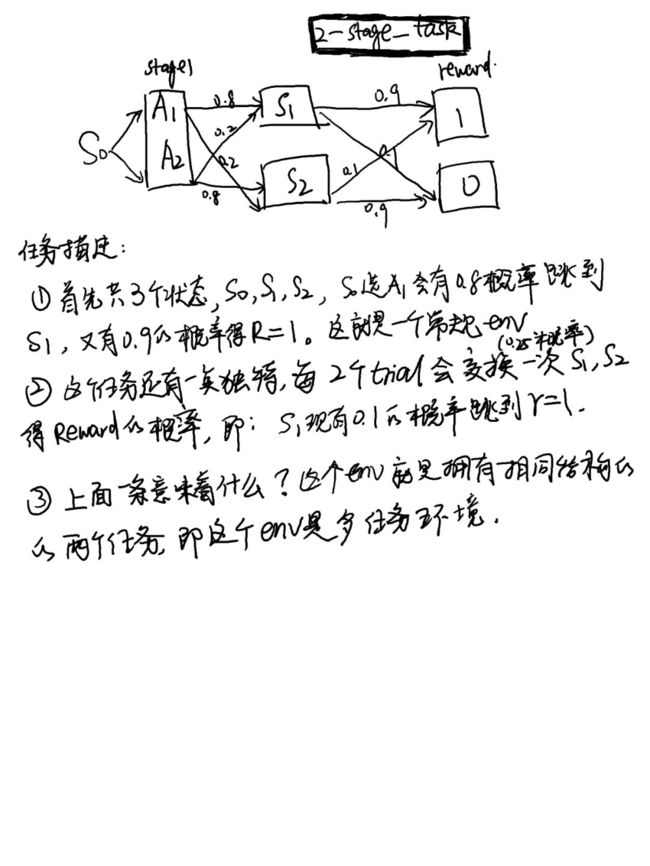
下面说它用的什么框架:
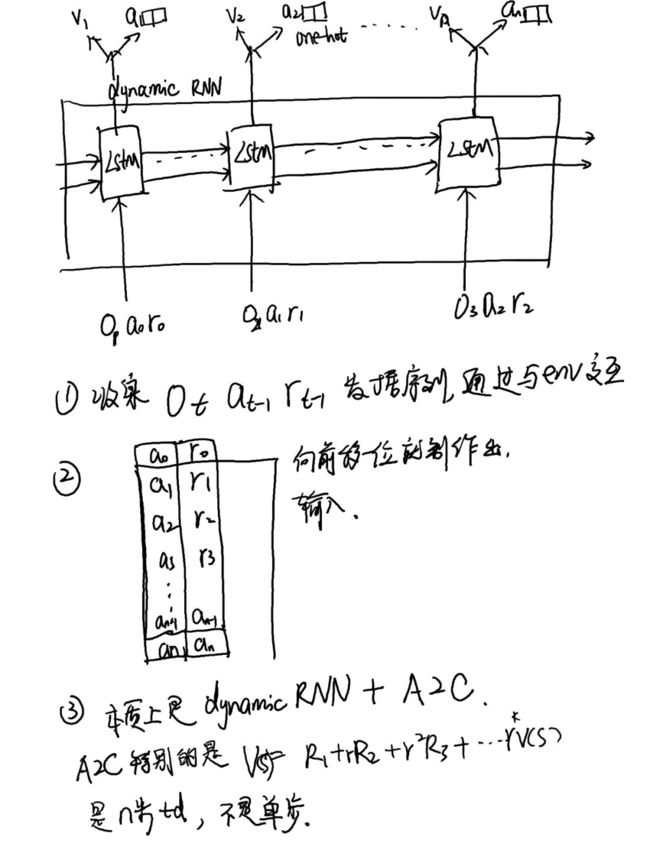
这样训练完成它解决了什么问题:
当有一个新的序列输入时候,模型能分辨出这是哪一个任务,从而得出接下来该执行什么动作。更具体地说:比如上一个奖励是1,动作是A1,经过这个模型它能知道这个奖励是通过common 还是uncommon transition 得到的,(s0到s1再到奖励1是大概率跳转时称为common transition,是通过小概率跳转得到的奖励成为uncommon transition).因此,当通过模型知道奖励1是通过common transition得到时,模型知道接下来要多重复这个动作能得到更多奖励(论文中重复概率称为stay probability )。同样地,如果执行动作A2也得到奖励了1,但是模型学会了这是uncommon transition,它不会重复A2这个动作。同样都是得到奖励1,通过这个模型才可以知道该不该跟着干这个动作以或者更多奖励。 这就是这个模型要学到的最终效果,这个任务的效果,从另一个角度来说,是用RNN达到了world base的效果,尽管它并没有训练一个world 模型。
原文:Another
important setting where structure-sensitive DA signaling has been
observed is in tasks designed to probe for model-based control.
总结并强调这个新模型的本质:
这种以前额皮质(PFC)的机制来建模的metal
rl
leaning,主要利用了PFC中发现的功能,它会吸收奖励和动作的历史序列,把这个序列encode为某种任务结构的内部表示。所以1,这个模型可以用于训练基于相同结构的多种任务上。所以2,训练完成后,你输入一个新的序列,这个模型能通过这个序列得到对应任务的内部结构表示,从而知道目前到底是哪个任务,从而给出针对这个任务该有的policy.
下面这个是代码链接:
https://github.com/mtrazzi/two-step-task
PS:请大概看过论文再看解读,如果有想法和疑问欢迎交流,我的微信号:Leslie27ch