本文将使用 TensorFlow 实现深度卷积生成对抗网络(DCGAN),并用其训练生成一些小姐姐的图像。其中,训练图像来源为:用DCGAN生成女朋友,图像全部由小姐姐的头像组成,大概如下:

生成对抗网络是近几年深度学习中一个比较热门的研究方向,不断的提出了各种各样的变体,包括 GAN、DCGAN、InfoGAN、WGAN、CycleGAN 等。这篇文章在参考 GAN 和 DCGAN 这两篇论文,以及 TensorFlow GAN 部分源代码的基础上,简单的实现了 DCGAN,并做了相当多的实验,生成了一些比较逼真的图像。
其实,在 GitHub 上已经有 DCGAN 的很多项目,星星比较的多的是 DCGAN-tensorflow,但我粗略阅读了他的代码后,觉得可读性不太好,因此还是觉得应该自己从头实现一遍,加深对对抗网络的理解。深度卷积生成对抗网络的网络结构比较简单,很容易实现,真正困难的是调参,参数稍微调整不好,就很容易使训练奔溃,生成的图像完全是噪声图像。
一、DCGAN 网络的定义
根据生成对抗网络(GAN)的发明者 Goodfellow 的说法,生成对抗网络由生成器(generator)G 和判别器(discriminator)D 两部分组成,其中生成器像假币制造者,企图制造出以假乱真的钱币,而判别器则像验钞机,能识别出哪些是真币哪些是假币。这种造假、打假的矛盾就产生了对抗,当生成器和判别器的能力都充分强大时,对抗的结局是趋于平衡,即生成器生成的样本判别器已经无法区分真伪,判别任何一个样本为真的概率都是 0.5。这当然是理想情况,实际对抗时,很难达到这样的平衡,只能达到一种比较脆弱的、动态的平衡,即生成器能够生成一些足够逼真的样本,而判别器也已很难鉴别样本的真假,但只要参数的变化幅度稍微较大时,就可能打破这个平衡,使得生成器瞬间脆败,生成的样本噪声越来越大,而判别器则不断占上风,能够轻而易举的识别真假,从而使得识别损失快速下降到 0。但既然是对抗,生成器就有可能触底反弹,再次东山再起,重新掀起一阵造假风波,使得判别器又陷入难辨真伪的窘迫境地。一般来说,生成对抗网络的训练过程就是达到平衡、平衡被破坏的、又达到平衡、又被破坏的循环过程,因此它的损失曲线是一条像过山车似的波浪线。
一般我们接触得比较多的深度学习模型大致有两类,一类是判别模型,一类是生成模型。判别模型的训练数据带有标签,比如分类,给定了一个样本之后需要确定它的归属;而生成模型则是需要根据训练数据来生成样本,或者确定训练数据的分布。通常,生成模型的问题更难,因为分布的归一化系数,即配分函数,很难处理。
GAN 的作者创造性的将判别模型和生成模型结合在一起,极大的简化了生成模型的求解过程,不过,缺点是训练不稳定。以下,以生成具有某种特性的图像为例,比如以生成小姐姐的头像为例,来简单的阐述深度卷积生成对抗网络(DCGAN)的原理和实现过程。
假如我们现在有很多小姐姐的头像,我们的目标是要设计一个网络,让它可以生成很逼真的小姐姐的图像。一个很自然的问题是:网络的输入是什么?Goodfellow 的想法很简单,输入是一个随机分布(比如正态分布、均匀分布等)的样本,一般是从这个分布中随机采样一个固定长度的向量,比如长度为 100 或 64 等。对于我们生成小姐姐头像的目标,我们需要从这个一维向量构造出一个具有 3 个颜色通道的 3 维图像。这需要借助一种称为转置卷积(transpose convolution 或 deconvolution)的技术。回想一下卷积网络的整个结构:从一幅 3 个颜色通道的图像开始,经过卷积、池化等作用之后,得到一个一维的最终输出。这显然可以看成是从一个一维向量生成 3 维图像过程的逆过程,因此也把转置卷积称为反卷积或解卷积。如下图:
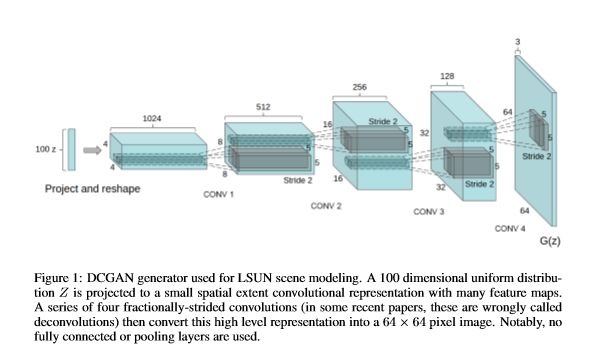
设随机采样的样本为 [x1, ..., xn](n=64 或 100 等),为了输入到一个(转置)卷积网络,将样本数据扩充为一个形状为 1 x 1 x 1 x n 的四维张量,经过第一个(转置)卷积层(卷积核大小 kernel_size = 4,步幅 stride = 2,填充方式 padding = 'VALID')之后,得到形状为 1 x 4 x 4 x 1024 的张量(跟卷积的运算相反,空间大小变大),再经过第二个(转置)卷积层(卷积核大小 kernel_size = 4,步幅 stride = 2,填充方式 padding = 'SAME')之后,形状变为 1 x 8 x 8 x 512,...,到第 6 个转置卷积层(卷积核大小 kernel_size = 4,步幅 stride = 2,填充方式 padding = 'SAME')之后,得到形状大小为 1 x 64 x 64 x 64 的张量,此时,为了得到一张 3 通道的图像,只需要再作用一个卷积层(卷积核大小 kernel_size = 1,步幅 stride = 1,特征映射个数 num_outputs = 3,填充方式 padding = 'SAME')即可,这样做了之后,输出张量的形状大小为 1 x 64 x 64 x 3,压缩第 0 个索引维度之后就得到一张分辨率为 64 x 64 的彩色图像。
以上即是生成器的网络结构。经过这个网络作用之后,可以把随机采样的一维向量转化成一张图像,不过不可忽略的是,这张图像也是随机的,因此可能全是噪声。为了让这些生成的图像具有小姐姐的人脸特征,需要加入一些监督信息来对生成器的参数进行训练。这部分的工作就由判别器来承担。判别器的网络结构基本上就是上述生成器的网络结构的逆结构(即几乎是上图从右往左看的结果),只不过最后的输出是一个长度为 2 的向量,即判别器是一个 2 分类器,用来识别一张图像是训练的真图像还是生成的假图像。因为判别器是深度网络,具有很强的拟合能力,因此很容易提取出训练数据的人脸特征,相当于提供了一种弱监督的信息(即提取的人脸特征)。接下来的关键问题是怎么充分的利用这种弱监督信息。
前面提到过,生产对抗网络的对抗过程是:生成器尽量生成逼真的假样本,使得判别器难辨真假,而判别器则尽量提升自己的判别能力,区分出生成器的假样本。因此,对生成器来说,生成的样本越接近训练数据越好。对于生成小姐姐图像的这个任务来说,生成器生成的样本具有越强的女性人脸特征越好。而女性人脸特征可以由判别器提供,因此得到的弱监督目标为:判别器作用于生成器生成的图像的结果,与判别器作用于真实训练图像的结果相似。换句话说,对生成器来说,它应该把自己生成的图像当成真实训练图像来看。而对判别器来说,则要把生成器生成的图像当做假图像来看,从而得到生成对抗网络的损失函数为:

更容易理解的方式是:
给定一个随机采样的向量 z,经过生成器作用之后生成一张图像 G(z),这张图像 G(z) 送给判别器 D 识别之后输出一个 2 分类概率 D(G(z)) = [p1, p2]。对于生成器 G 来说,它的目标是生成和真实训练样本 x 相差无几的图像,因此它要把所有生成的图像都看成是真实图像,因此生成器的损失是:
generator_loss = sigmoid_cross_entropy(logits=[p1, p2], labels=[1])
而对于判别器 D 来说,它希望识别能力越强越好,因此要认为这是一张假图像,从而得到判别器在生成图像上的损失:
discriminator_loss_on_generated = sigmoid_cross_entropy(logits=[p1, p2], labels=[0])
另一方面,为了利用真实图像的(弱监督)信息,判别器在所有真实训练样本 x 上的损失为:
discriminator_loss_on_real = sigmoid_cross_entropy(logits=[q1, q2], labels=[1])
其中 [q1, q2] = D(x) 是判别器作用于真实训练图像 x 后输出的识别概率。
到此,整个生成对抗网络的最重要的两部分(分别是:生成器、判别器的网络结构和它们对应的损失)内容就讲述完了。一般的,在实际实现时,上述的损失会进行一些平滑处理(见后面源代码,或论文 Improved Techniques for Training GANs),除此之外,在优化判别器时使用两部分损失之和:
discriminator_loss = discriminator_loss_on_generated + discriminator_loss_on_real
这样,我们总共得到了 4 个损失,其中用于反向传播优化网络参数的损失是:generator_loss 和 discriminator_loss。将以上思想用 TensorFlow 实现,即得到 DCGAN 的模型(命名为 model.py):
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 20:03:48 2018
@author: shirhe-lyh
"""
"""Implementation of DCGAN.
This work was first described in:
Unsupervised representation learning with deep convolutional generative
adversarial networks, Alec Radford et al., arXiv: 1511.06434v2
This module Based on:
TensorFlow models/research/slim/nets/dcgan.py
TensorFlow tensorflow/contrib/gan
"""
import math
import tensorflow as tf
slim = tf.contrib.slim
class DCGAN(object):
"""Implementation of DCGAN."""
def __init__(self,
is_training,
generator_depth=64,
discriminator_depth=64,
final_size=32,
num_outputs=3,
fused_batch_norm=False):
"""Constructor.
Args:
is_training: Whether the the network is for training or not.
generator_depth: Number of channels in last deconvolution layer of
the generator network.
discriminator_depth: Number of channels in first convolution layer
of the discirminator network.
final_size: The shape of the final output.
num_outputs: Nuber of output features. For images, this is the
number of channels.
fused_batch_norm: If 'True', use a faster, fused implementation
of batch normalization.
"""
self._is_training = is_training
self._generator_depth = generator_depth
self._discirminator_depth = discriminator_depth
self._final_size = final_size
self._num_outputs = num_outputs
self._fused_batch_norm = fused_batch_norm
def _validate_image_inputs(self, inputs):
"""Check the inputs whether is valid or not.
Copy from:
https://github.com/tensorflow/models/blob/master/research/
slim/nets/dcgan.py
Args:
inputs: A float32 tensor with shape [batch_size, height, width,
channels].
Raises:
ValueError: If the input image shape is not 4-dimensional, if the
spatial dimensions aren't defined at graph construction time,
if the spatial dimensions aren't square, or if the spatial
dimensions aren't a power of two.
"""
inputs.get_shape().assert_has_rank(4)
inputs.get_shape()[1:3].assert_is_fully_defined()
if inputs.get_shape()[1] != inputs.get_shape()[2]:
raise ValueError('Input tensor does not have equal width and '
'height: ', inputs.get_shape()[1:3])
width = inputs.get_shape().as_list()[2]
if math.log(width, 2) != int(math.log(width, 2)):
raise ValueError("Input tensor 'width' is not a power of 2: ",
width)
def discriminator(self,
inputs,
depth=64,
is_training=True,
reuse=None,
scope='Discriminator',
fused_batch_norm=False):
"""Discriminator network for DCGAN.
Construct discriminator network from inputs to the final endpoint.
Copy from:
https://github.com/tensorflow/models/blob/master/research/
slim/nets/dcgan.py
Args:
inputs: A float32 tensor with shape [batch_size, height, width,
channels].
depth: Number of channels in first convolution layer.
is_training: Whether the network is for training or not.
reuse: Whether or not the network variables should be reused.
'scope' must be given to be reused.
scope: Optional variable_scope. Default value is 'Discriminator'.
fused_batch_norm: If 'True', use a faster, fused implementation
of batch normalization.
Returns:
logits: The pre-softmax activations, a float32 tensor with shape
[batch_size, 1].
end_points: A dictionary from components of the network to their
activation.
Raises:
ValueError: If the input image shape is not 4-dimensional, if the
spatial dimensions aren't defined at graph construction time,
if the spatial dimensions aren't square, or if the spatial
dimensions aren't a power of two.
"""
normalizer_fn = slim.batch_norm
normalizer_fn_args = {
'is_training': is_training,
'zero_debias_moving_mean': True,
'fused': fused_batch_norm}
self._validate_image_inputs(inputs)
height = inputs.get_shape().as_list()[1]
end_points = {}
with tf.variable_scope(scope, values=[inputs], reuse=reuse) as scope:
with slim.arg_scope([normalizer_fn], **normalizer_fn_args):
with slim.arg_scope([slim.conv2d], stride=2, kernel_size=4,
activation_fn=tf.nn.leaky_relu):
net = inputs
for i in range(int(math.log(height, 2))):
scope = 'conv%i' % (i+1)
current_depth = depth * 2**i
normalizer_fn_ = None if i == 0 else normalizer_fn
net = slim.conv2d(net, num_outputs=current_depth,
normalizer_fn=normalizer_fn_,
scope=scope)
end_points[scope] = net
logits = slim.conv2d(net, 1, kernel_size=1, stride=1,
padding='VALID', normalizer_fn=None,
activation_fn=None)
logits = tf.reshape(logits, [-1, 1])
end_points['logits'] = logits
return logits, end_points
def generator(self,
inputs,
depth=64,
final_size=32,
num_outputs=3,
is_training=True,
reuse=None,
scope='Generator',
fused_batch_norm=False):
"""Generator network for DCGAN.
Construct generator network from inputs to the final endpoint.
Copy from:
https://github.com/tensorflow/models/blob/master/research/
slim/nets/dcgan.py
Args:
inputs: A float32 tensor with shape [batch_size, N] for any size N.
depth: Number of channels in last deconvolution layer.
final_size: The shape of the final output.
num_outputs: Nuber of output features. For images, this is the
number of channels.
is_training: Whether is training or not.
reuse: Whether or not the network has its variables should be
reused. 'scope' must be given to be reused.
scope: Optional variable_scope. Default value is 'Generator'.
fused_batch_norm: If 'True', use a faster, fused implementation
of batch normalization.
Returns:
logits: The pre-sortmax activations, a float32 tensor with shape
[batch_size, final_size, final_size, num_outputs].
end_points: A dictionary from components of the network to their
activation.
Raises:
ValueError: If 'inputs' is not 2-dimensional, or if 'final_size'
is not a power of 2 or is less than 8.
"""
normalizer_fn = slim.batch_norm
normalizer_fn_args = {
'is_training': is_training,
'zero_debias_moving_mean': True,
'fused': fused_batch_norm}
inputs.get_shape().assert_has_rank(2)
if math.log(final_size, 2) != int(math.log(final_size, 2)):
raise ValueError("'final_size' (%i) must be a power of 2."
% final_size)
if final_size < 8:
raise ValueError("'final_size' (%i) must be greater than 8."
% final_size)
end_points = {}
num_layers = int(math.log(final_size, 2)) - 1
with tf.variable_scope(scope, values=[inputs], reuse=reuse) as scope:
with slim.arg_scope([normalizer_fn], **normalizer_fn_args):
with slim.arg_scope([slim.conv2d_transpose],
normalizer_fn=normalizer_fn,
stride=2, kernel_size=4):
net = tf.expand_dims(tf.expand_dims(inputs, 1), 1)
# First upscaling is different because it takes the input
# vector.
current_depth = depth * 2 ** (num_layers - 1)
scope = 'deconv1'
net = slim.conv2d_transpose(net, current_depth, stride=1,
padding='VALID', scope=scope)
end_points[scope] = net
for i in range(2, num_layers):
scope = 'deconv%i' % i
current_depth = depth * 2 * (num_layers - i)
net = slim.conv2d_transpose(net, current_depth,
scope=scope)
end_points[scope] = net
# Last layer has different normalizer and activation.
scope = 'deconv%i' % num_layers
net = slim.conv2d_transpose(net, depth, normalizer_fn=None,
activation_fn=None, scope=scope)
end_points[scope] = net
# Convert to proper channels
scope = 'logits'
logits = slim.conv2d(
net,
num_outputs,
normalizer_fn=None,
activation_fn=tf.nn.tanh,
kernel_size=1,
stride=1,
padding='VALID',
scope=scope)
end_points[scope] = logits
logits.get_shape().assert_has_rank(4)
logits.get_shape().assert_is_compatible_with(
[None, final_size, final_size, num_outputs])
return logits, end_points
def dcgan_model(self,
real_data,
generator_inputs,
generator_scope='Generator',
discirminator_scope='Discriminator',
check_shapes=True):
"""Returns DCGAN model outputs and variables.
Modified from:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/
contrib/gan/python/train.py
Args:
real_data: A float32 tensor with shape [batch_size, height, width,
channels].
generator_inputs: A float32 tensor with shape [batch_size, N] for
any size N.
generator_scope: Optional genertor variable scope. Useful if you
want to reuse a subgraph that has already been created.
discriminator_scope: Optional discriminator variable scope. Useful
if you want to reuse a subgraph that has already been created.
check_shapes: If 'True', check that generator produces Tensors
that are the same shape as real data. Otherwise, skip this
check.
Returns:
A dictionary containing output tensors.
Raises:
ValueError: If the generator outputs a tensor that isn't the same
shape as 'real_data'.
"""
# Create models
with tf.variable_scope(generator_scope) as gen_scope:
generated_data, _ = self.generator(
generator_inputs, self._generator_depth, self._final_size,
self._num_outputs, self._is_training)
with tf.variable_scope(discirminator_scope) as dis_scope:
discriminator_gen_outputs, _ = self.discriminator(
generated_data, self._discirminator_depth, self._is_training)
with tf.variable_scope(dis_scope, reuse=True):
discriminator_real_outputs, _ = self.discriminator(
real_data, self._discirminator_depth, self._is_training)
if check_shapes:
if not generated_data.shape.is_compatible_with(real_data.shape):
raise ValueError('Generator output shape (%s) must be the '
'shape as real data (%s).'
% (generated_data.shape, real_data.shape))
# Get model-specific variables
generator_variables = slim.get_trainable_variables(gen_scope)
discriminator_variables = slim.get_trainable_variables(dis_scope)
return {'generated_data': generated_data,
'discriminator_gen_outputs': discriminator_gen_outputs,
'discriminator_real_outputs': discriminator_real_outputs,
'generator_variables': generator_variables,
'discriminator_variables': discriminator_variables}
def predict(self, generator_inputs):
"""Return the generated results by generator network.
Args:
generator_inputs: A float32 tensor with shape [batch_size, N] for
any size N.
Returns:
logits: The pre-sortmax activations, a float32 tensor with shape
[batch_size, final_size, final_size, num_outputs].
"""
logits, _ = self.generator(generator_inputs, self._generator_depth,
self._final_size, self._num_outputs,
is_training=False)
return logits
def discriminator_loss(self,
discriminator_real_outputs,
discriminator_gen_outputs,
label_smoothing=0.25):
"""Original minmax discriminator loss for GANs, with label smoothing.
Modified from:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/
contrib/gan/python/losses/python/losses_impl.py
Args:
discriminator_real_outputs: Discriminator output on real data.
discriminator_gen_outputs: Discriminator output on generated data.
Expected to be in the range of (-inf, inf).
label_smoothing: The amount of smoothing for positive labels. This
technique is taken from `Improved Techniques for Training GANs`
(https://arxiv.org/abs/1606.03498). `0.0` means no smoothing.
Returns:
loss_dict: A dictionary containing three scalar tensors.
"""
# -log((1 - label_smoothing) - sigmoid(D(x)))
losses_on_real = slim.losses.sigmoid_cross_entropy(
logits=discriminator_real_outputs,
multi_class_labels=tf.ones_like(discriminator_real_outputs),
label_smoothing=label_smoothing)
loss_on_real = tf.reduce_mean(losses_on_real)
# -log(- sigmoid(D(G(x))))
losses_on_generated = slim.losses.sigmoid_cross_entropy(
logits=discriminator_gen_outputs,
multi_class_labels=tf.zeros_like(discriminator_gen_outputs))
loss_on_generated = tf.reduce_mean(losses_on_generated)
loss = loss_on_real + loss_on_generated
return {'dis_loss': loss,
'dis_loss_on_real': loss_on_real,
'dis_loss_on_generated': loss_on_generated}
def generator_loss(self, discriminator_gen_outputs, label_smoothing=0.0):
"""Modified generator loss for DCGAN.
Modified from:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/
contrib/gan/python/losses/python/losses_impl.py
Args:
discriminator_gen_outputs: Discriminator output on generated data.
Expected to be in the range of (-inf, inf).
Returns:
loss: A scalar tensor.
"""
losses = slim.losses.sigmoid_cross_entropy(
logits=discriminator_gen_outputs,
multi_class_labels=tf.ones_like(discriminator_gen_outputs),
label_smoothing=label_smoothing)
loss = tf.reduce_mean(losses)
return loss
def loss(self, discriminator_real_outputs, discriminator_gen_outputs):
"""Computes the loss of DCGAN.
Args:
discriminator_real_outputs: Discriminator output on real data.
discriminator_gen_outputs: Discriminator output on generated data.
Expected to be in the range of (-inf, inf).
Returns:
A dictionary contraining 4 scalar tensors.
"""
dis_loss_dict = self.discriminator_loss(discriminator_real_outputs,
discriminator_gen_outputs)
gen_loss = self.generator_loss(discriminator_gen_outputs)
dis_loss_dict.update({'gen_loss': gen_loss})
return dis_loss_dict
二、训练并生成图像
深度卷积生成对抗网络 DCGAN 论文的作者总结了他们取得将生成对抗网络用于无监督、稳定的生成图像成功的一些技术:

上面的代码(model.py) 基本上忠实的采用了这些技术。一些细微的差别为:
- 从随机分布中采样出的向量长度为 64,而不是论文中的 100;
- 用于训练的真实图像的分辨率只能是 n x n,其中 n 必须是 2 的幂;
- 生成图像的分辨率也只能是 m x m,其中 m 必须是 2 的幂;
- 定义损失时,使用了平滑的技术 Improved Techniques for Training GANs。
这一节关注训练 DCGAN 的问题。首先,将训练文件(命名为 train.py)的代码列出如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun May 27 16:55:12 2018
@author: shirhe-lyh
"""
"""Train a DCGAN to generating fake images.
Example Usage:
---------------
python3 train.py \
--images_dir: Path to real images directory.
--images_pattern: The pattern of input images.
--generated_images_save_dir: Path to directory where to write gen images.
--logdir: Path to log directory.
--num_steps: Number of steps.
"""
import cv2
import glob
import numpy as np
import os
import tensorflow as tf
import model
flags = tf.flags
flags.DEFINE_string('images_dir', None, 'Path to real images directory.')
flags.DEFINE_string('images_pattern', '*.jpg', 'The pattern of input images.')
flags.DEFINE_string('generated_images_save_dir', None, 'Path to directory '
'where to write generated images.')
flags.DEFINE_string('logdir', './training', 'Path to log directory.')
flags.DEFINE_integer('num_steps', 20000, 'Number of steps.')
FLAGS = flags.FLAGS
def get_next_batch(batch_size=64):
"""Get a batch set of real images and random generated inputs."""
if not os.path.exists(FLAGS.images_dir):
raise ValueError('images_dir is not exist.')
images_path = os.path.join(FLAGS.images_dir, FLAGS.images_pattern)
image_files_list = glob.glob(images_path)
image_files_arr = np.array(image_files_list)
selected_indices = np.random.choice(len(image_files_list), batch_size)
selected_image_files = image_files_arr[selected_indices]
images = read_images(selected_image_files)
# generated_inputs = np.random.normal(size=[batch_size, 64])
generated_inputs = np.random.uniform(
low=-1, high=1.0, size=[batch_size, 64])
return images, generated_inputs
def read_images(image_files):
"""Read images by OpenCV."""
images = []
for image_path in image_files:
image = cv2.imread(image_path)
image = cv2.resize(image, (64, 64))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = (image - 127.5) / 127.5
images.append(image)
return np.array(images)
def write_images(generated_images, images_save_dir, num_step):
"""Write images to a given directory."""
#Scale images from [-1, 1] to [0, 255].
generated_images = ((generated_images + 1) * 127.5).astype(np.uint8)
for j, image in enumerate(generated_images):
image_name = 'generated_step{}_{}.jpg'.format(num_step+1, j+1)
image_path = os.path.join(FLAGS.generated_images_save_dir,
image_name)
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
cv2.imwrite(image_path, image)
def main(_):
# Define placeholder
real_data = tf.placeholder(
tf.float32, shape=[None, 64, 64, 3], name='real_data')
generated_inputs = tf.placeholder(
tf.float32, [None, 64], name='generated_inputs')
# Create DCGAN model
dcgan_model = model.DCGAN(is_training=True, final_size=64)
outputs_dict = dcgan_model.dcgan_model(real_data, generated_inputs)
generated_data = outputs_dict['generated_data']
generated_data_ = tf.identity(generated_data, name='generated_data')
discriminator_gen_outputs = outputs_dict['discriminator_gen_outputs']
discriminator_real_outputs = outputs_dict['discriminator_real_outputs']
generator_variables = outputs_dict['generator_variables']
discriminator_variables = outputs_dict['discriminator_variables']
loss_dict = dcgan_model.loss(discriminator_real_outputs,
discriminator_gen_outputs)
discriminator_loss = loss_dict['dis_loss']
discriminator_loss_on_real = loss_dict['dis_loss_on_real']
discriminator_loss_on_generated = loss_dict['dis_loss_on_generated']
generator_loss = loss_dict['gen_loss']
# Write loss values to logdir (tensorboard)
tf.summary.scalar('discriminator_loss', discriminator_loss)
tf.summary.scalar('discriminator_loss_on_real', discriminator_loss_on_real)
tf.summary.scalar('discriminator_loss_on_generated',
discriminator_loss_on_generated)
tf.summary.scalar('generator_loss', generator_loss)
merged_summary = tf.summary.merge_all(key=tf.GraphKeys.SUMMARIES)
# Create optimizer
discriminator_optimizer = tf.train.AdamOptimizer(learning_rate=0.0004, # 0.0005
beta1=0.5)
discriminator_train_step = discriminator_optimizer.minimize(
discriminator_loss, var_list=discriminator_variables)
generator_optimizer = tf.train.AdamOptimizer(learning_rate=0.0001,
beta1=0.5)
generator_train_step = generator_optimizer.minimize(
generator_loss, var_list=generator_variables)
saver = tf.train.Saver(var_list=tf.global_variables())
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# Write model graph to tensorboard
if not FLAGS.logdir:
raise ValueError('logdir is not specified.')
if not os.path.exists(FLAGS.logdir):
os.makedirs(FLAGS.logdir)
writer = tf.summary.FileWriter(FLAGS.logdir, sess.graph)
fixed_images, fixed_generated_inputs = get_next_batch()
for i in range(FLAGS.num_steps):
if (i+1) % 500 == 0:
batch_images = fixed_images
batch_generated_inputs = fixed_generated_inputs
else:
batch_images, batch_generated_inputs = get_next_batch()
train_dict = {real_data: batch_images,
generated_inputs: batch_generated_inputs}
# Update discriminator network
sess.run(discriminator_train_step, feed_dict=train_dict)
# Update generator network five times
sess.run(generator_train_step, feed_dict=train_dict)
sess.run(generator_train_step, feed_dict=train_dict)
sess.run(generator_train_step, feed_dict=train_dict)
sess.run(generator_train_step, feed_dict=train_dict)
sess.run(generator_train_step, feed_dict=train_dict)
summary, generated_images = sess.run(
[merged_summary, generated_data], feed_dict=train_dict)
# Write loss values to tensorboard
writer.add_summary(summary, i+1)
if (i+1) % 500 == 0:
# Save model
model_save_path = os.path.join(FLAGS.logdir, 'model.ckpt')
saver.save(sess, save_path=model_save_path, global_step=i+1)
# Save generated images
if not FLAGS.generated_images_save_dir:
FLAGS.generated_images_save_dir = './generated_images'
if not os.path.exists(FLAGS.generated_images_save_dir):
os.makedirs(FLAGS.generated_images_save_dir)
write_images(
generated_images, FLAGS.generated_images_save_dir, i)
writer.close()
if __name__ == '__main__':
tf.app.run()
这个文件定义了 4 个函数,从上到下分别是:用于随机采样一个批量训练数据的函数 get_next_batch,用于从本地文件夹读取训练图像的函数 read_images,用于将生成器生成的图像保存到某一文件夹的函数 write_images,以及训练整个深度卷积生成对抗网络的主函数 main。前 3 个内容少而简单,直接略过,我们只看 main 函数。主函数首先定义了两个占位符,用于作为数据入口。接下来,实例化一个类 DCGAN 的一个对象,然后作用于占位符上,得到模型输出和 4 个损失,紧随其后的 5 条语句 tf.summary 将损失写入到日志文件,其目的是可以使用 tensorboard 在浏览器中可视化的查看损失的变化情况。再然后是定义了两个优化器:discriminator_optimizer、generateor_optimizer,分别用于优化判别器和生成器的损失。最后,在定义了模型保存对象 saver 和将模型的 graph 写入到日志文件之后,来到了训练过程(for 循环):
- 随机从训练图像中选择一个批量的训练样本;
- 每优化 1 次判别器都要相继优化 5 次生成器;
- 每训练 500 步保存一次生成的图像和模型。
另外,为了能够看清模型生成的图像的演化过程,每训练 500 步都使用同样的输入数据。
关于生成对抗网络训练的方法,GAN 讲得比较清晰:

我们需要关注的一个重点是:判别器每训练 k 次,生成器训练 1 次。但按照我自己的理解(可能有误),应该是:生成器每训练 k 次,判别器训练 1 次。这是因为,在训练的早期,生成器生成的样本与训练的真实样本差别很大,判别器能够轻而易举的识别出来,因此损失 discriminator_loss_on_generated 会迅速的下降到 0,为了延缓这个损失的下降,以及为了让生成器得到充分的训练尽快生成质量较高的样本,选择连续优化生成器 k 次。
回到我们生成小姐姐头像的问题,经过多次实验,最终选择 k = 5,即每优化 5 次生成器才优化 1 次判别器。这样训练可以让损失 discriminator_loss_on_generated 以及损失 generator_loss 有一段相当长的对抗平衡过程,从而能够让生成器能够长时间的得到优化,进而生成质量较高的图像。
在项目的当前目录的终端执行:
python3 train.py --images_dir path/to/images/directory
此时会在当前目录下生成一个新的文件夹:training,这个文件夹用来保存训练过程中产生的数据,如模型各种参数等。然后,再运行 tensorboard:
tensorboard --logdir ./training
打开终端返回的浏览器链接,你可以在 SCALARS 页面下看到四条损失曲线,为了更深刻的理解生成对抗网络,建议你仔细的观察这些损失曲线的变化过程,并思考怎样调整参数,让网络生成更逼真的图像。
train.py 中 main 函数中的优化器的参数是我试验了很多次之后确定的,虽然还不是很让人满意的参数,但已经可以生成一些比较好的图像了,如训练 15500 次之后生成的图像为(所有生成的图像都保存在文件夹 generated_images):

可以看到,生成的图像整体质量已经比较好了。如果从中挑选出一些比较满意的图像的话,下面这些生成的小姐姐应该可以以假乱真了:

当然,清晰度还需要继续提高。
三、训练的一些细节
训练生成对抗网络时,需要调整的重点是:两个优化器的学习率和判别器每优化 1 次生成器优化的次数 k。为了学习率的确定更简单,可以使用自适应学习率的优化器 Adam,此时,一般的初始学习率为 0.0001,调整时,可以固定其中一个,而重点去调整另外一个。调整过程中,需要确保损失 discriminator_loss_on_generated 不会一直下降,对应的,即损失 generator_loss 不能一直上升,比较理想的情况是两者都稳定在某一数值附近波动。一般的,如果训练 500 次之后,文件夹 generated_images 里生成的图像都是糊的,说明当前学习率选得不好,要中断训练过程重新调整学习率;而如果此时文件夹里的图像已经依稀有人脸特征,说明可以继续往下训练。以下是我某次训练时的损失曲线(所有参数跟 train.py 中的一样):


根据上图,损失 discriminator_loss_on_generated 和 generator_loss 在 5000 次训练之前处于平衡状态,此时生成的图像越来越清晰。但 5500 次训练之后,损失 generator_loss 开始迅速增大,生成的图像全部变成噪声图像(见下图),此后,在训练 8000 次之后,generator_loss 损失又急剧降到低水平,此时生成的质量又开始变好。到 16000 次之后,随着损失 generator_loss 再次变大,生成的图像再次变糊。对照以上过程,整个训练过程中生成的对应图像如下(因 16000 次之后的图像全是糊的,故略去):

最后,需要说明的一点是,在选择生成器输入的随机分布时,如果使用正态分布(见函数 get_next_batch 被注释的一行):
generated_inputs = np.random.normal(size=[batch_size, 64])
则生成的图像中会有很多是相似的,如第 17500 次训练时生成的 64 张图像中:

第 12、14、21、26、27、39、46、49 张图像,及第 9、22、28、33、42、47、56、61 张图像都非常相似(说明标准正太分布生成的样本本身很相似,适用于条件生成对抗网络)。而采用均匀分布:
generated_inputs = np.random.uniform(low=-1, high=1.0, size=[batch_size, 64])
则可以极大的缓解这个问题,见图 3。