搞懂基本排序算法
上篇文章写了关于 Java 内部类的基本知识,感兴趣的朋友可以去看一下:搞懂 JAVA 内部类;本文写的内容是最近学习的算法相关知识中的基本排序算法,排序算法也算是面试中的常客了,实际上也是算法中最基本的知识。由于 Android 开发中用到的地方并不多,所以也很容易遗忘,但是为了进阶高级工程师巩固基本算法和数据结构也是必修课程之一。
基本排序算法按难易程度来说可以分为:冒泡排序,选择排序,插入排序,归并排序,选择排序。本文也将从这五种排序算法来讲解各自的中心思想,和 Java 实现方式。
冒泡排序
冒泡排序恐怕是我们计算机专业课程上以第一个接触到的排序算法,也算是一种入门级的排序算法。
冒泡排序虽然简单但是对于 n 数量级很大的时候,其实是很低效率的。所以实际生产中很少使用这种排序算法。下面我们看下这种算法的具体实现思路:
冒泡排序算法原理:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
一次比较过程如图所示(图片 Google 来的侵删)
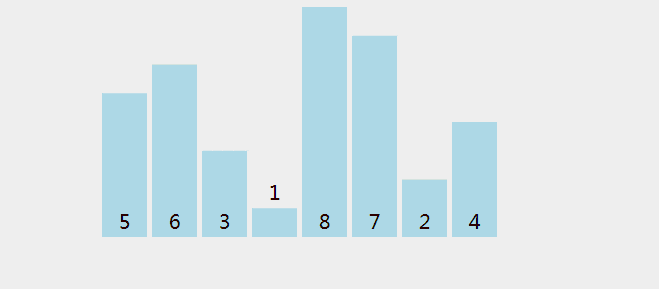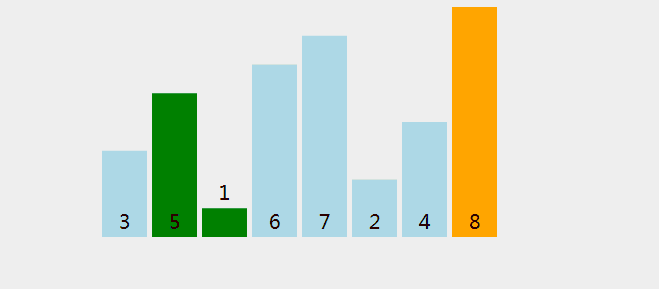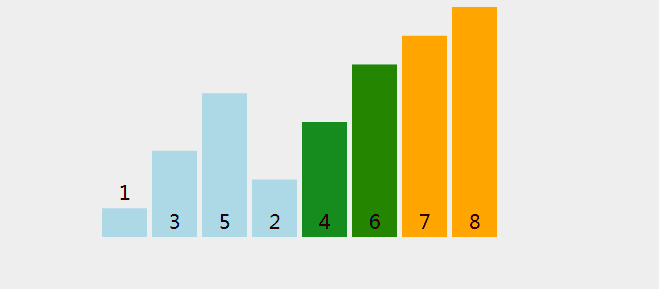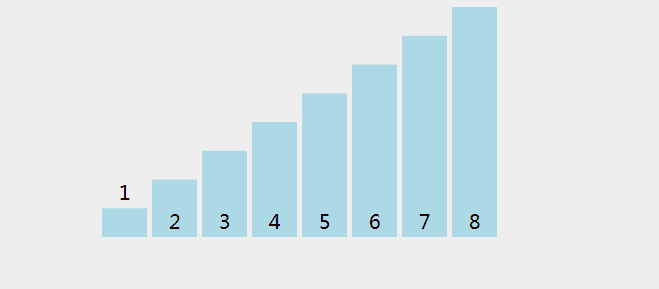
冒泡排序 Java 代码实现:
/**
* @param arr 待排序数组
* @param n 数组长度
*/
private static void BubbleSort(int[] arr, int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = 1; j < n - i - 1; j++) {
if (arr[j - 1] > arr[j]) {
//交换两个元素
int temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
}
}
}
}
冒泡排序时间空间复杂度及算法稳定性分析
对于长度为 n 的数组,冒泡排序需要经过 n(n-1)/2 次比较,最坏的情况下,即数组本身是倒序的情况下,需要经过 n(n-1)/2 次交换,所以其
冒泡排序的算法时间平均复杂度为O(n²)。空间复杂度为 O(1)。
可以想象一下:如果两个相邻的元素相等是不会进行交换操作的,也就是两个相等元素的先后顺序是不会改变的。如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个元素相邻起来,最终也不会交换它俩的位置,所以相同元素经过排序后顺序并没有改变。
所以冒泡排序是一种稳定排序算法。所以冒泡排序是稳定排序。这也正是算法稳定性的定义:
排序算法的稳定性:通俗地讲就是能保证排序前两个相等的数据其在序列中的先后位置顺序与排序后它们两个先后位置顺序相同。
冒泡排序总结:
- 冒泡排序的算法时间平均复杂度为O(n²)。
- 空间复杂度为 O(1)。
- 冒泡排序为稳定排序。
选择排序
选择排序是另一种简单的排序算法。选择排序之所以叫选择排序就是在一次遍历过程中找到最小元素的角标位置,然后把它放到数组的首端。我们排序过程都是在寻找剩余数组中的最小元素,所以就叫做选择排序。
选择排序的思想
选择排序的思想也很简单:
- 从待排序序列中,找到关键字最小的元素;起始假定第一个元素为最小
- 如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
- 从余下的 N - 1 个元素中,找出关键字最小的元素,重复1,2步,直到排序结束。
示意图:

选择排序 Java 代码实现:
public static void sort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n; i++) {
int minIndex = i;
// for 循环 i 之后所有的数字 找到剩余数组中最小值得索引
for (int j = i + 1; j < n; j++) {
if (arr[j]< arr[minIndex]) {
minIndex = j;
}
}
swap(arr, i, minIndex);
}
}
/**
* 角标的形式 交换元素
*/
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
选择排序时间空间复杂度及算法稳定性分析
上述 java 代码可以看出我们除了交换元素并未开辟额外的空间,所以额外的空间复杂度为O(1)。
对于时间复杂度而言,选择排序序冒泡排序一样都需要遍历 n(n-1)/2 次,但是相对于冒泡排序来说每次遍历只需要交换一次元素,这对于计算机执行来说有一定的优化。但是选择排序也是名副其实的慢性子,即使是有序数组,也需要进行 n(n-1)/2 次比较,所以其时间复杂度为O(n²)。
即便无论如何也要进行n(n-1)/2 次比较,选择排序仍是不稳定的排序算法,我们举一个例子如:序列5 8 5 2 9, 我们知道第一趟选择第1个元素5会与2进行交换,那么原序列中两个5的相对先后顺序也就被破坏了。
选择排序总结:
- 选择排序的算法时间平均复杂度为O(n²)。
- 选择排序空间复杂度为 O(1)。
- 选择排序为不稳定排序。
插入排序
对于插入排序,大部分资料都是使用扑克牌整理作为例子来引入的,我们打牌都是一张一张摸牌的,没摸到一张牌就会跟手里所有的牌比较来选择合适的位置插入这张牌,这也就是直接插入排序的中心思想,我们先来看下动图:
[图片上传失败...(image-9dcd7b-1519835757103)]
相信大家看完动图以后大概知道了插入排序的实现思路了。那么我们就来说下插入排序的思想。
插入排序的思想
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤 2~5
插入排序的 Java 实现:
下面先看下最基本的实现:
public static void sort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n; i++) {
//内层循环比较 i 与前边所有元素值,如果 j 索引所指的值小于 j- 1 则交换两者的位置
for(int j = i; j > 0 && arr[j-1] > arr[j]; j--){
swap(arr,j-1,j);
}
}
}
在上述算法实现中我们每次寻找 i 应该处在数组中哪个为位置的时候,都是以交换当前元素与上一个元素为代价的,我们知道交换操作是要比赋值操作要费时的,因为每次交换都需要经过三次赋值操作,我们想一下我们玩扑克的时候没有拿起一张牌一个个向前挪知道放到其该放的位置的吧,都是拿出这张牌,找到位置就插进去(突然邪恶),实际上我们是将这个位置以后的牌一次向后挪了一个位置,那么用Java 代码是否能实现呢?答案肯定是可以的:
public static void sort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n; i++) {
//拎出来当前未排序的这样牌
int e = arr[i];
//寻找其该放的位置
for(int j = i; j > 0 && arr[j-1] > arr[j]; j--){
arr[j]= arr[j-1];
}
//循环结束后 arr[j] >= arr[j-1] 那么 j 角标就是e 应该在的位置。
arr[j] = e;
}
}
插入排序的时间复杂度和空间复杂度分析
对于插入的时间复杂度和空间复杂度,通过代码就可以看出跟选择和冒泡来说没什么区别同属于 O(n²) 级别的时间复杂度算法 ,只是遍历方式有原来的 n n-1 n-2 ... 1,变成了 1 2 3 ... n 了。最终得到时间复杂度都是 n(n-1)/2。
对于稳定性来说,插入排序和冒泡一样,并不会改变原有的元素之间的顺序,如果遇见一个与插入元素相等的,那么把待插入的元素放在相等元素的后面。所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序仍是排好序后的顺序,所以插入排序是稳定的。
对于插入排序这里说一个非常重要的一点就是:由于这个算法可以提前终止内层比较( arr[j-1] > arr[j])所以这个排序算法很有用!因此对于一些 NlogN 级别的算法,后边的归并和快速都属于这个级别的,算法来说对于 n 小于一定级别的时候(Array.sort 中使用的是47)都可以用插入算法来优化,另外对于近乎有序的数组来说这个提前终止的方式就显得更加又有优势了。
插入排序总结:
- 插入排序的算法时间平均复杂度为O(n²)。
- 插入排序空间复杂度为 O(1)。
- 插入排序为稳定排序。
- 插入排序对于近乎有序的数组来说效率更高,插入排序可用来优化高级排序算法
归并排序
接下来我们看一个 NlogN 级别的排序算法,归并算法。 归并算法正如其名字一样采用归并的方法进行排序:
我们总是可以将一个数组一分为二,然后二分为四直到,每一组只有两个元素,这可以理解为个递归的过程,然后将两个元素进行排序,之后再将两个元素为一组进行排序。直到所有的元素都排序完成。同样我们来看下边这个动图。
归并算法的思想
归并算法其实可以分为递归法和迭代法(自低向上归并),两种实现对于最小集合的归并操作思想是一样的区别在于如何划分数组,我们先介绍下算法最基本的操作:
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针到达序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
假设我们现在在对一个数组的 arr[l...r] 部分进行归并,按照上述归并思想我们可将数组分为两部分 假设为 arr[l...mid] 和 arr[mid+1...r]两部分,注意这两部分可能长度并不相同,因为基数个数的数组划分的时候总是能得到一个 长度为1 和长度为2 的部分进行归并.
那么我们按照上述思路进行代码编写:
归并排序的 Java 实现:
/**
* arr[l,mid] 和 arr[mid+1,r] 两部分进行归并
*/
private static void merge(int[] arr, int l, int mid, int r) {
// 复制等待归并数组 用来进行比较操作,最将原来的 arr 每个角标赋值为正确的元素
int[] aux = new int[r - l + 1];
for (int i = l; i <= r; i++) {
aux[i - l] = arr[i];
}
int i = l;
int j = mid + 1;
for (int k = l; k <= r; k++) {
if (i > mid) {
//说明左边部分已经全都放进数组了
arr[k] = aux[j - l];
j++;
} else if (j > r) {
//说明左边部分已经全都放进数组了
arr[k] = aux[i - l];
i++;
} else if (aux[i - l] < aux[j - l]) {
//当左半个数组的元素值小于右边数组元素值得时候 赋值为左边的元素值
arr[k] = aux[i - l];
i++;
} else {
//当左半个数组的元素值大于等于右边数组元素值得时候 赋值为左边的元素值 这样也保证了排序的稳定性
arr[k] = aux[j - l];
j++;
}
}
}
相信大家配合刚才的动图和上述算法实现已经理解了归并算法了,如果感到迷糊的话可以试着拿个一个数组在纸上演算一下归并的过程,相信大家一定可以理解。上述只是实现了算法核心部分,那么我们应该怎么对整个数组来进行排序呢?上边也提到了有两种方法,一种是递归划分法,一种是迭代遍历法(自低向上)那么我们先来开来看递归实现:
/**
*
* @param arr 待排序数组
* @param l 其实元素角标 0
* @param r 最后一个元素角标 n -1
*/
private static void mergeSort(int[] arr, int l, int r) {
if (l >= r) {
return;
}
//开始归并排序 向下取整
int mid = (l + r) / 2;
//递归划分数组
mergeSort(arr, l, mid);
mergeSort(arr, mid + 1, r);
//检查是否上一步归并完的数组是否有序,如果有序则直接进行下一次归并
if (arr[mid] <= arr[mid + 1]) {
return;
}
//将两边的元素归并排序
merge(arr, l, mid, r);
}
如果对递归过程不理解可以配合下边这个图来理解(图片来自网上,侵删):

当然我们merge先对左半部分进行的也就是先进行到Level3的左边最底层 8 | 6 ,然后归并完成后进行右边递归到底 最终是 8 6 2 3 | 1 5 7 4 进行归并。
对于迭代实现归并其实和递归实现有所不同,迭代的时候我们是将数组分为 一个一个的元素,然后每两个归并一次,第二次我们将数组每两个分一组,两个两个的归并,知道分组大小等于待归并数组长度为止,即先局部排序,逐步扩大到全局排序
/**
* 自低向上的归并排序
*
* @param n 为数组长度
* @param arr 数组
*/
private static void mergeSortBU(Integer[] arr, int n) {
//外层遍历从归并区间长度为1 开始 每次递增一倍的空间 1 2 4 8 sz 需要遍历到数组长度那么大
//sz = 1 : [0] [1]...
//sz = 2 : [0,1] [2.3] ...
//sz = 4 : [0..3] [4...7] ...
for (int sz = 1; sz <= n; sz += sz) {
//内层遍历要比较 arr[i,i+sz-1] arr[i+sz,i+sz+sz-1] 两个区间的大小 也就是每次对 sz - 1 大小的数组空间进行归并
// 注意每次 i 递增 两个 sz 的长度 ,因为每次 merge 的时候已经归并了两个 sz 长度 部分的数组
for (int i = 0; i + sz < n; i += sz + sz) {
merge(arr, i, i + sz - 1, Math.min(i + sz + sz - 1, n - 1));
}
}
}
比如我们看第一次是 sz = 1 个长度的归并即 i = 0 i = 1 的元素归并 下次归并应该为 i= 2 i = 3 一次类推 所以内层循环 i 每次应该递增 两个 sz 那么大 为了避免角标越界且保证归并的右半部分存在 所以 i + sz < n ,又考虑到数组长度为奇数的情况,所以右半边的右边为 Math.min(i + sz + sz - 1, n - 1);可以参考下边的图片:

归并排序的时间复杂度和空间复杂度分析
其实对于归并排序的时间复杂对有一个递归公式来推断出时间复杂度,但简单来讲假设数组长度为 N ,那么我们就有 logN 次划分区间,而最终会划分为常数 级别的归并,将所有层的归并时间加起来得到了一个 NlogN,想要了解归并排序时间复杂度讲解的同学可以左转 归并排序及其时间复杂度分析,这里不再过多讲解。
对于空间复杂度,我们通过算法实现可以看出我们归并过程申请了 长度为 N 的临时数组,来进行归并所以空间复杂度为 O(n);
又由于我们在排序过程中对于 aux[i - l] = aux[j - l] 并没有进行位置交换直接取得靠前的元素先赋值,所以算法是稳定的。
** 归并排序总结:**
- 归并排序的算法时间平均复杂度为O(nlog(n))。
- 归并排序空间复杂度为 O(n)。
- 归并排序为稳定排序。
- 对于
快速排序
快速排序为应用最多的排序算法,因为快速二字而闻名。快速排序和归并排序一样,采用的都是分治思想。分治法的基本思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。我们只需关注最小问题该如何求解,和如何去递归既可以得到正确的算法实现。快速排序可以分为:单路快速排序,双路快速排序,三路快速排序,他们区别在于选取几个指针来对数组进行遍历下面我们依次来讲解。
单路快速算法的思想:
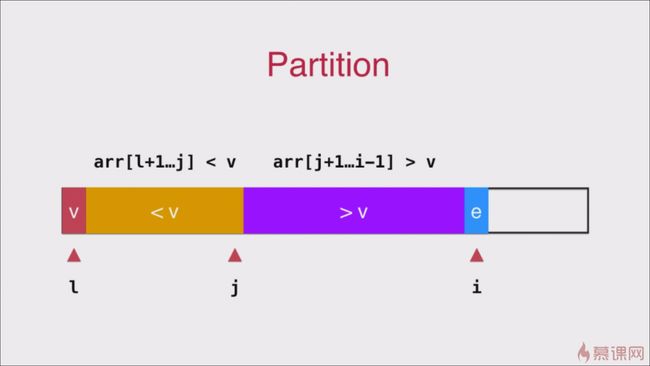
首先我们选取数组中的一个数,将其放在合适的位置,这个位置左边的数全部小于该数值,这个位置右边的数全部大于该数值 。
假设数组为
arr[l...r]假设指定数值为数组第一个元素int v = arr[l],假设 j 标记为比 v 小的最后一个元素, 即arr[j+1] > v。当前考察的元素为 i 则有arr[l + 1 ... j] < v , arr[j+1,i) >= v如上图所示。假设正在考察的元素值为 e ,
e >= v的时候我们只需交将不动,直接 i++ 去考察下一个元素,当
e < v由上述假设我们需要将 e 放在arr[j] 和 arr[i]交换一下位置即可。最后一个元素考察完成以后,我们再讲
arr[l]和arr[j]调换一下位置就可以了。上述遍历完成以后
arr[l + 1 ... j] < v , arr[j+1,i) >= v就满足了,接下来我们只需要递归的去考察 arr[l + 1 ... j] 和 arr[j+1,r] 即可。
单路快速排序的 Java 实现:
private static void quickSort(int[] arr, int l, int r) {
if (l >= r) {
return;
}
// p 为 第一次 排序完成后 v 应该在的位置,即分治的划分点
int p = partition(arr, l, r);
quickSort(arr, l, p - 1);
quickSort(arr, p + 1, r);
}
private static int partition(Integer[] arr, int l, int r) {
// 为了提高效率,减少造成快速排序的递归树不均匀的概率,
// 对于一个数组,每次随机选择的数为当前 partition 操作中最小最大元素的可能性为 1/n
int randomNum = (int) (Math.random() * (r - l + 1) + l);
swap(arr, l, randomNum);
int v = arr[l];
int j = l;
for (int i = l + 1; i <= r; i++) {
if (arr[i] < v) {
swap(arr, j + 1, i);
j++;
}
}
swap(arr, l, j);
return j;
}
private static void swap( int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
对于上述算法中为什么选取了当前排序数组中随机一个元素进行比较,假设我们在考察的数组已经为已经排序好的数组,那么我们递归树就会向右侧延伸 N 的深度,这种情况使我们不想要看到的,如果我们每次 partition 都随机从数组中取一个数,那么这个数是当前排序数组中最小元素可能性为 1/n 那么每次都取到最小的数的可能性就很低了。
双路快速排序算法思想:
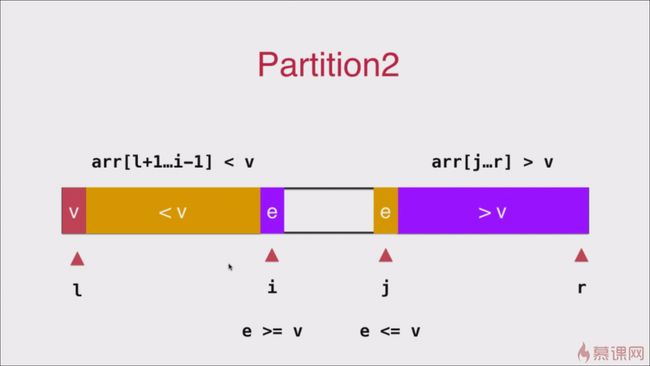
跟单路一样,双路快速排序,同样选择数组的第一个元素当做标志位(经过随机选择后的)
双路快速排序要求有两个指针,指针 i j 分别指向 l+1 和 r 的位置然后两者同时向数组中间遍历 在遍历过程中要保证
arr[l+1 ... i) <= v, arr(j....r] >= v因此我们可以初始化 i = l+1 以保证左侧区间初始为空,j = r 保证右侧空间为空遍历过程中要 i <= r 且 arr[i] <= v 的时候 i ++ 就可以了 当 arr[i] > v 时表示遇到了 i 的值大于 v 数值 此刻能等待 j 角标的值,从右向左遍历数组 当 arr[i] < v 表示遇到了 j 的值小于 v 的元素,它不该在这个位置呆着,
得到了 i j 的角标后 先要判断是否到了循环结束的时候了,即 i 是否已经 大于 j 了。
否则 应该讲 i 位置的元素和 j 位置的元素交换位置,然后 i++ j-- 继续循环
遍历结束的条件是 i>j 此时 arr[j]为最后一个小于 v 的元素 arr[i] 为第一个大于 v 的元素 因此 j 这个位置 就应该是 v 所应该在数组中的位置 因此遍历结束后需要交换 arr[l] 与 arr[j]
双路快速排序的 Java 实现:
private static void quickSort(int[] arr, int l, int r) {
if (l >= r) {
return;
}
// 这里 p 为 小于 v 的最后一个元素,=v 的第一个元素
int p = partition(arr, l, r);
quickSort(arr, l, p - 1);
quickSort(arr, p + 1, r);
}
private static int partition(int[] arr, int l, int r) {
// 为了提高效率,减少造成快速排序的递归树不均匀的概率,
// 对于一个数组,每次随机选择的数为当前 partition 操作中最小最大元素的可能性降低
int randomNum = (int) (Math.random() * (r - l + 1) + l);
swap(arr, l, randomNum);
int v = arr[l];
int i = l + 1;
int j = r;
while (true) {
while (i <= r && arr[i] <= v) i++;
while (j >= l + 1 && arr[j] >= v) j--;
if (i > j) break;
swap(arr, i, j);
i++;
j--;
}
//j 最后角标停留在 i > j 即为 比 v 小的最后一个一元素位置
swap(arr, l, j);
return j;
}
双路快速排序为最经常使用的快速排序实现,java 中对基本数据类型的排序 Arrays.sort() Collections.sort() 内部原理就是通过这种快速排序实现.
三路快速排序
上述两种算法我们发现对于与标志位相同的值得处理总是,做了多余的交换处理,如果我们能够将数组分为> = <三部分的话效率可能会有所提高。
如下图所示:
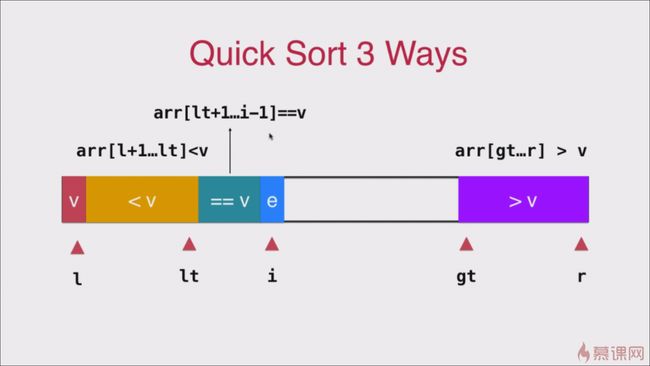
我们将数组划分为
arr[l+1...lt]三部分 其中 lt 指向 < v 的最后一个元素前一个元素,gt 指向>v的第一个元素的前一个元素,i 为当前考察元素v 定义初始值得时候依旧可以保证这初始的时候这三部分都为空
int lt = l; int gt = r; int i = l + 1;当
e > v的时候我们需要将arr[i] 与 arr[gt-1]交换位置,并将> v的部分扩大一个元素 即gt--但是此时 i 指针并不需要操作,因为换过过来的数还没有被考察。当
e = v的时候 i ++ 继续考察下一个当
e < v的时候我们需要将arr[i] 与 arr[lt+1]交换位置当循环结束的时候 lt 位于小于 v 的最后一个元素位置所以最后我们需要将arr[l] 与 arr[lt] 交换一下位置。如下图2所示

三路快速排序 Java 代码实现:
private static void quickSort3(int[] num, int length) {
quickSort(num, 0, length - 1);
}
private static void quickSort(int[] arr, int l, int r) {
if (l >= r) {
return;
}
// 为了提高效率,减少造成快速排序的递归树不均匀的概率,
// 对于一个数组,每次随机选择的数为当前 partition 操作中最小最大元素的可能性 降低 1/n!
int randomNum = (int) (Math.random() * (r - l + 1) + l);
swap(arr, l, randomNum);
int v = arr[l];
// 三路快速排序即把数组划分为大于 小于 等于 三部分
//arr[l+1...lt] v 三部分
// 定义初始值得时候依旧可以保证这初始的时候这三部分都为空
int lt = l;
int gt = r;
int i = l + 1;
while (i < gt) {
if (arr[i] < v) {
swap(arr, i, lt + 1);
i++;
lt++;
} else if (arr[i] == v) {
i++;
} else {
swap(arr, i, gt - 1);
gt--;
//i++ 注意这里 i 不需要加1 因为这次交换后 i 的值仍不等于 v 可能小于 v 也可能等于 v 所以交换完成后 i 的角标不变
}
}
//循环结束的后 lt 所处的位置为 我们可以看到三路快速排序没有了递归的过程通过一次循环既可以完成排序。
快速排序时间复杂度空间复杂度
由于我们最常使用的是双路快排因此我们以此来分析:我们为了方便分析我们假定元素不是随机选取的而是取得数组第一个元素,在选取的标准元素和 partition 得到位置交换的时候,很有可能把前面的元素的稳定性打乱,
比如序列为 5 3 3 4 3 8 9 10 11
现在基准元素5和3(第5个元素,下标从1开始计)交换就会把元素3的稳定性打乱。所以快速排序是一个不稳定的排序算法,不稳定发生在基准元素和a[partition]交换的时刻。
对于快速排序的时间度取决于其递归的深度,如果递归深度又决定于每次关键值得取值所以在最好的情况下每次都取到数组中间值,那么此时算法时间复杂度最优为 O(nlogn)。当然最坏情况就是之前我们分析的有序数组,那么每次都需要进行 n 次比较则 时间复杂度为 O(n²),但是在平均情况 时间复杂度为 O(nlogn),同样若想看详细的推到这里推荐一个链接 快速排序最好,最坏,平均复杂度分析
快速排序的空间复杂度主要取决于表示为选择的时候的临时空间,所以跟时间复杂度挂钩,所以平均的空间复杂度也是 O(nlogn)。
总结
本文总结了常见的排序算法的实现,通过研究这些算法的思想,也有助于算法题的解题思路。对于这几种算法都是需要我们熟练掌握的,但是 Android 工作平时不会接触太多的数据处理,因此我们需要刻意的去经常复习,本文的图片大部分来自于网上,如果有问题的话可以私信我删掉。如果文章所说的内容有技术问题也欢迎联系我。
地址
CSDN
Github 地址
参考链接:
几种常见排序算法
常用排序算法稳定性、时间复杂度分析(转,有改动)
慕课网波波老师的数据结构课程