前言:
文章以Andrew Ng 的 deeplearning.ai 视频课程为主线,记录Programming Assignments 的实现过程。相对于斯坦福的CS231n课程,Andrew的视频课程更加简单易懂,适合深度学习的入门者系统学习!
本次作业主要练习的是最优化cost函数的方法,不同的优化方法可以加速学习的过程,可能给最后的识别准确率带来不同的影响。对于cost函数的优化首先有一个直观的感受:
1.1 Gradient Descent:
一个简单的优化方法叫做梯度下降的方法,在每次迭代中对所有样本执行梯度下降,因此也叫做batch gradient descent
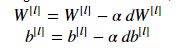
代码如下:
def update_parameters_with_gd(parameters, grads, learning_rate):
L = len(parameters) // 2
for l in range(L):
parameters["W" + str(l+1)] = parameters["W"+str(l+1)]-learning_rate*grads["dW"+str(l+1)]
parameters["b" + str(l+1)] = parameters["b"+str(l+1)]-learning_rate*grads["db"+str(l+1)]
return parameters
Stochastic Gradient Descent:针对于每一个样本,对每一个样本执行梯度下降算法

Mini-Batch Gradient descent 介于SGD和 GD,每次训练的样本数量


1.2 Mini-Batch Gradient descent:
我们首先需要构建Mini-Batch 去训练模型涉及到两个过程shuffle和partition,代码如下:
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
np.random.seed(seed)
m = X.shape[1]
mini_batches = []
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((1,m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size)
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[:,k*mini_batch_size:(k+1)*mini_batch_size]
mini_batch_Y = shuffled_Y[:,k*mini_batch_size:(k+1)*mini_batch_size]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[:, num_complete_minibatches*mini_batch_size:m]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches*mini_batch_size:m]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
1.3 Momentum
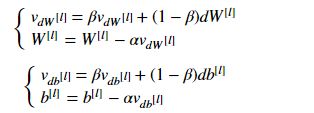
def initialize_velocity(parameters):
L = len(parameters) // 2
v = {}
for l in range(L):
v["dW" + str(l+1)] = np.zeros((parameters["W"+str(l+1)].shape[0],parameters["W"+str(l+1)].shape[1]))
v["db" + str(l+1)] = np.zeros((parameters["b"+str(l+1)].shape[0],parameters["b"+str(l+1)].shape[1]))
return v
def update_parameters_with_momentum(parameters, grads, v, beta, learning_rate):
L = len(parameters) // 2 # number of layers in the neural networks
for l in range(L):
v["dW" + str(l+1)] = beta*v["dW"+str(l+1)]+(1-beta)*grads["dW"+str(l+1)]
v["db" + str(l+1)] = beta*v["db"+str(l+1)]+(1-beta)*grads["db"+str(l+1)]
parameters["W" + str(l+1)] = parameters["W"+str(l+1)]-learning_rate*v["dW"+str(l+1)]
parameters["b" + str(l+1)] = parameters["b"+str(l+1)]-learning_rate*v["db"+str(l+1)]
return parameters, v
1.4 Adam
Adam是目前为止最为广泛应用的优化方式,整合了RMSProp和Momentum的优点,计算方式如下:

def initialize_adam(parameters) :
L = len(parameters) // 2
v = {}
s = {}
for l in range(L):
v["dW" + str(l+1)] = np.zeros((parameters["W"+str(l+1)].shape[0],parameters["W"+str(l+1)].shape[1]))
v["db" + str(l+1)] = np.zeros((parameters["b" + str(l + 1)].shape[0], parameters["b" + str(l + 1)].shape[1]))
s["dW" + str(l+1)] = np.zeros((parameters["W" + str(l + 1)].shape[0], parameters["W" + str(l + 1)].shape[1]))
s["db" + str(l+1)] = np.zeros((parameters["b" + str(l + 1)].shape[0], parameters["b" + str(l + 1)].shape[1]))
return v, s
def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01,
beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8):
L = len(parameters) // 2
s_corrected = {}
v_corrected = {}
for l in range(L):
v["dW" + str(l+1)] = beta1*v["dW"+str(l+1)]+(1-beta1)*grads["dW"+str(l+1)]
v["db" + str(l+1)] = beta1*v["db"+str(l+1)]+(1-beta1)*grads["db"+str(l+1)]
v_corrected["dW" + str(l+1)] = v["dW"+str(l+1)]/(1-beta1**t)
v_corrected["db" + str(l+1)] = v["db"+str(l+1)]/(1-beta1**t)
s["dW" + str(l+1)] = beta2*s["dW"+str(l+1)]+(1-beta2)*(grads["dW"+str(l+1)]*grads["dW"+str(l+1)])
s["db" + str(l+1)] = beta2*s["db"+str(l+1)]+(1-beta2)*(grads["db"+str(l+1)]*grads["db"+str(l+1)])
s_corrected["dW" + str(l+1)] = s["dW"+str(l+1)]/(1-beta2**t)
s_corrected["db" + str(l+1)] = s["db"+str(l+1)]/(1-beta2**t)
parameters["W" + str(l+1)] = parameters["W"+str(l+1)]-learning_rate*v_corrected["dW"+str(l+1)]/(np.sqrt(s_corrected["dW"+str(l+1)])+epsilon)
parameters["b" + str(l+1)] = parameters["b"+str(l+1)]-learning_rate*v_corrected["db"+str(l+1)]/(np.sqrt(s_corrected["db"+str(l+1)])+epsilon)
return parameters, v, s
1.5 Model
首先看一下数据集的样子:
train_X, train_Y = load_dataset()

def model(X, Y, layers_dims, optimizer, learning_rate = 0.0007, mini_batch_size = 64, beta = 0.9,
beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8, num_epochs = 10000, print_cost = True):
L = len(layers_dims)
costs = []
t = 0
seed = 10
parameters = initialize_parameters(layers_dims)
if optimizer == "gd":
pass
elif optimizer == "momentum":
v = initialize_velocity(parameters)
elif optimizer == "adam":
v, s = initialize_adam(parameters)
# Optimization loop
for i in range(num_epochs):
seed = seed + 1
minibatches = random_mini_batches(X, Y, mini_batch_size, seed)
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch
a3, caches = forward_propagation(minibatch_X, parameters)
cost = compute_cost(a3, minibatch_Y)
grads = backward_propagation(minibatch_X, minibatch_Y, caches)
if optimizer == "gd":
parameters = update_parameters_with_gd(parameters, grads, learning_rate)
elif optimizer == "momentum":
parameters, v = update_parameters_with_momentum(parameters, grads, v, beta, learning_rate)
elif optimizer == "adam":
t = t + 1
parameters, v, s = update_parameters_with_adam(parameters, grads, v, s,
t, learning_rate, beta1, beta2, epsilon)
if print_cost and i % 1000 == 0:
print ("Cost after epoch %i: %f" %(i, cost))
if print_cost and i % 100 == 0:
costs.append(cost)
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('epochs (per 100)')
plt.title("Learning rate = " + str(learning_rate))
plt.show()
return parameters
我们看一下 Mini-batch Gradient descent的训练效果:
layers_dims = [train_X.shape[0], 5, 2, 1]
parameters = model(train_X, train_Y, layers_dims, optimizer = "gd")
predictions = predict(train_X, train_Y, parameters)
plt.title("Model with Gradient Descent optimization")
axes = plt.gca()
axes.set_xlim([-1.5,2.5])
axes.set_ylim([-1,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
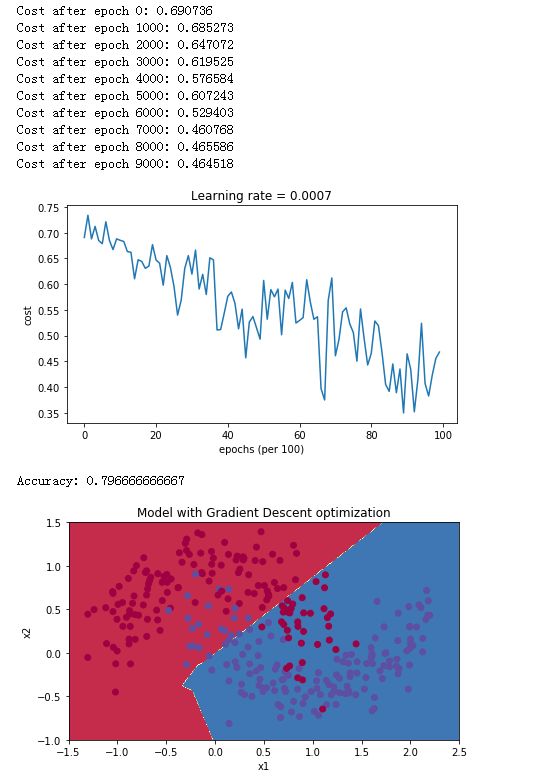
可以发现准确率只有将近80%
下面我们看一下momentum的训练效果:
layers_dims = [train_X.shape[0], 5, 2, 1]
parameters = model(train_X, train_Y, layers_dims, beta = 0.9, optimizer = "momentum")
predictions = predict(train_X, train_Y, parameters)
plt.title("Model with Momentum optimization")
axes = plt.gca()
axes.set_xlim([-1.5,2.5])
axes.set_ylim([-1,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
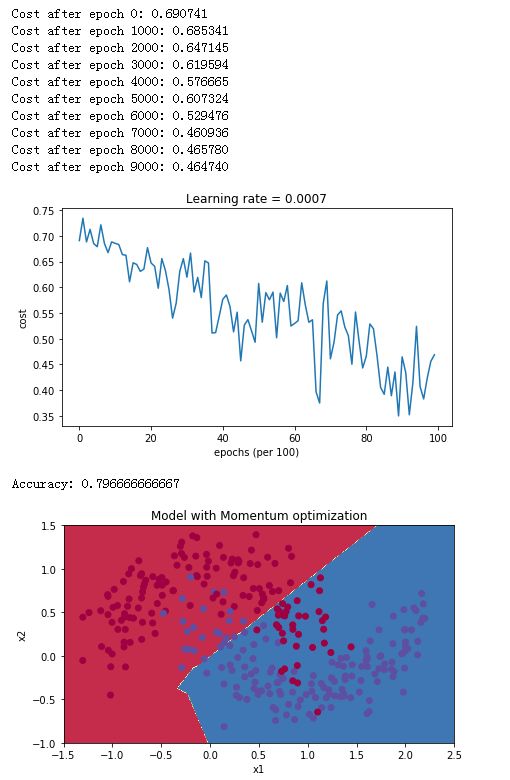
准确率基本上和Mini-batch Gradient Descent差不多
最后我们看一下Adam的训练效果:
layers_dims = [train_X.shape[0], 5, 2, 1]
parameters = model(train_X, train_Y, layers_dims, optimizer = "adam")
predictions = predict(train_X, train_Y, parameters)
plt.title("Model with Adam optimization")
axes = plt.gca()
axes.set_xlim([-1.5,2.5])
axes.set_ylim([-1,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
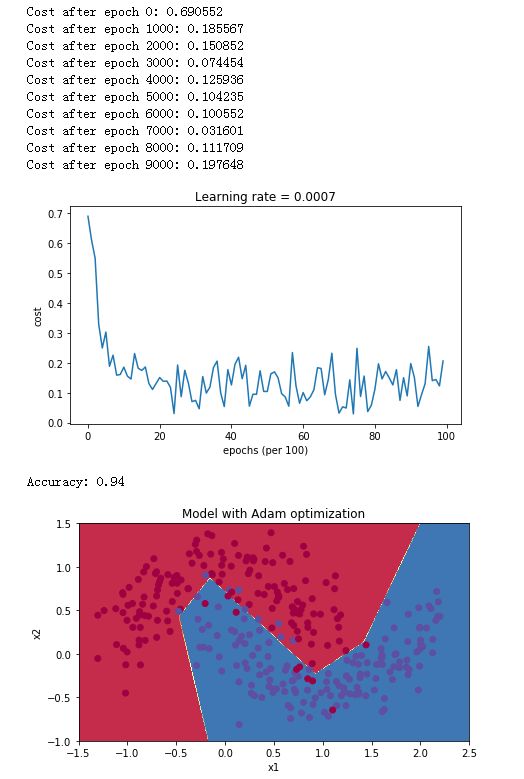
我们看到准确率达到94%
综上所述,我们发现Momentum通常是有效果的,但是在较小的学习率和简单的数据集上,效果不是很明显,Adam通常来说效果要由于其他两种方法,但是在更多迭代次数的情况下,通常3种优化方法都会得到一个好的结果,Adam只是收敛的更快。
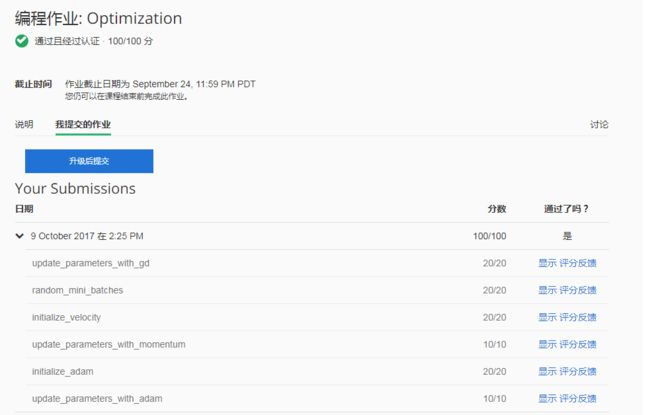
最后附上我作业的得分,表示我程序没有问题,如果觉得我的文章对您有用,请随意打赏,我将持续更新Deeplearning.ai的作业!