最近在工作闲暇中也在追赶时代的潮流,于是就打起了机器学习的注意,通过网上查阅资料还有询问相关的从业人员,发现机器学习的成本还是蛮高的,对数理统计这方面的要求也蛮高,还好我同事是统计方面的留学高材生,给我推荐了李航博士的《统计学习方法》一书,说实话对于我这个高数曾经不及格得人来讲这本书还是很难啃的,好在平时遇到问题了还能问一下,于是就有了一个想法,想把自己看的东西总结一下,一方面是为了更好的交流学习,另一方面也是希望能给像我一样的数学功底不好又想紧跟时代潮流的程序员一个参考,如果接下来文中出现错误还请及时指正,言归正传,开写.
写在前面
AI目前最火热的就是神经网络,所以我也是准备从神经网络入手的,在入手之前我希望大家可以先看看阮神的关于神经网络的那篇博客,这样更有助于在脑海里有一个印象,在看书之前我是有先看了数据分析的一些东西,这里推荐大家无事的时候学一下python的语法,因为大多数人工智能相关的文献的代码也都是用python实现的,这里在强烈推荐下python的科学计算发型包Anaconda,我稍后会整理一篇关于Anaconda安装的教程,言归正传,我们先了解下感知机,你可以把感知机模型当做神经网络中的一个人工神经元,这里我们先举个例子以便于有助理解感知机.
假设你是否参加一个活动首三个因素影响:
男票/女票---是否愿意跟你同去 ( 同去则
公共交通是否方便到达 (方便则
然后你设置了阈值
我们把以上每种影响因素当做一个神经元,我们把这些神经元组合在一起构成了如下的一个神经网络:

第一层:做最简单的决策
第二层:根据第一层的决策做更加抽象与复杂的决策
第三层:基于第二层 做更加抽象复杂的决策
...
实际上我们可以通过学习算法确定下来以上的权值w和阙值threshold.这样就可以帮助我们来进行去不去参加活动的决策了.
这个例子来源于 http://neuralnetworksanddeeplearning.com/chap1.html
知乎链接: https://zhuanlan.zhihu.com/p/23101102
英文好的同学可以去读第一个链接的书,顺便安利下一个公众号哈工大SCIR,里面有这本书的连载翻译版本,另外在推荐一下一个哈工大的知乎作者链接: https://zhuanlan.zhihu.com/qinlibo-ml
感知机模型
感知机模型其实是一种线性分类模型,属于判别类型,主要是为了解决二分类问题的(现在更多的是用和感知机相似的支持向量机SVM方式解决,因为传统感知机可能会产生过拟合现象,对未知数据的判别会相对不准确,有兴趣的大家可以自行百度一下过拟合,这里不作为我们介绍的重点)
假设输入和输出空间的以下关系:
称为感知机,其中w代表权重,b叫做偏置(阙值),w*x表示内积,sign即符号函数:
由上面的符号函数我们也就易知,感知机主要是用来处理二分类问题的,我们再来看一个神经网络的图谱:

该神经网络被称为前置神经网络,我们是不是觉得这个网络和感知机有点相似?神经网络实际上就是将大量之前讲到的感知机进行组合,用不同的方法进行连接并作用在不同的激活函数上。我们简单介绍下前向神经网络,其具有以下属性:
1.一个输入层,一个输出层,一个或多个隐含层。上图所示的神经网络中有一个三神经元的输入层、一个四神经元的隐含层、一个二神经元的输出层。
2.每一个神经元都是一个上文提到的感知机。
3.输入层的神经元作为隐含层的输入,同时隐含层的神经元也是输出层神经元的输入。
4.每条建立在神经元之间的连接都有一个权重 w (与感知机中提到的权重类似)。
5.在 t 层的每个神经元通常与前一层( t – 1层 )中的每个神经元都有连接(但你可以通过将这条连接的权重设为0来断开这条连接)。
6.为了处理输入数据,将输入向量赋到输入层中。在上例中,这个网络可以计算一个3维输入向量(由于只有3个输入层神经元)。假如输入向量是 [7, 1, 2],你将第一个输入神经元输入7,中间的输入1,第三个输入2。这些值将被传播到隐含层,通过加权传递函数传给每一个隐含层神经元(这就是前向传播),隐含层神经元再计算输出(激活函数)。
7.输出层和隐含层一样进行计算,输出层的计算结果就是整个神经网络的输出。
感知机几何解释:
有如下线性方程:
该线性方程对应于特征空间的一个超平面S,其中w为S的法向量(二维坐标系为法线),b为截距,该超平面S将空间分为两个部分,我们分别称为正负类,因此该平面也被叫做分离超平面

所以我们可以知道感知机学习,即由训练数集
求得感知机模型,即求对应的w和b,通过得到的感知机模型,对于新的输入实例感知机模型就可以输出其对应的类别了
感知机学习策略:
我们先假设训练数据集是线性可分的,感知机通过学习之后确定下来的最终模型是一个可以将正负实力点完全正确区分的分离超平面,那么怎样找到这样一个超平面呢?这里就需要给感知机定义一个学习策略(学习算法),这里我们先引入损失函数(详细的含义大家可以百度搜索,这里我们不做赘述),我们从字面意思上也大概可以理解损失函数的意义,即当前这个超平面误分类点的总数,由上面可以,我们最终希望的结果是这个超平面完全区分正负类,即损失函数最小(0),即转化为对损失函数求极值的问题,我们都知道导数的含义就是指在这一点的极值(大家可以搜索导数的含义)......
但是,这样的一个损失函数(误分类点个数)并不一定是单数w,b的连续可导函数,不易处理,因为我们最终要用计算机语言去实现,所以损失函数的另一个选择定义为误分类点到当前超平面的距离的和,为此我们先写出空间任意一点到超平面S的距离:
我们现在改变一下距离公式的形式,有符号函数公式我们可知误分类点满足(因为y始终为1,-1)
对误分类点到超平面距离公式去绝对值得:
假设超平面误分类点的集合为M,所有误分类点的总距离就可以表示为如下:
这里我们可以不考虑w的L2范式,也就是1/||w||(我们之所以把损失函数化为误分点的距离就是以便于稍后利用随机梯度下降算法不断迭代更新w和b,其实本质感知机所要求得的并不是'距离'),所以我们可以给出损失函数定义为如下:
显然,没有误分类点时损失函数L为0,好了, 到这里我们总结下,我们知道了感知机的形式,知道了我们要通过训练数据确定下来感知机的w和b,这个模型确定下来以后我们就可以利用这个模型尝试去对未知数据做二分类问题了
感知机学习算法
我们最终目的是根据训练数据求出w和b,其中利用了梯度下降的方式不断修正w和b,所以这个学习算法大概过程是这样的:
1.先给定一个初始w和b
2.随意选取任意一点
3.检测这一点是否满足误分类点条件公式
4.如果不满足说明正确分类了,回到第二部
5.如果满足说明被误分类了,更新w和b,跟新完后再回到第二部
6.一直递归循环下去,知道某个w和b都没有误分类点为止
其实整个流程用代码实现的话不难,我们大概可以猜到需要一个判断,然后在写一个递归函数就搞定了,重点就在第5步,也就是该如何用更新w和b,更新方式如下:

其中η(0<=η<=1)代表步长,你可以理解为梯度下降过程中迈开的步子有多大(更形象的解释可以参考斯坦福大学吴恩尘的深度学习的公开课,第二课中有对梯度下降进行一个形象的解释),它在统计学中被称为学习率,接下来我们对η取1,然后采用随机梯度下降更新w和b,这里有人可能会问,问什么是随机梯度下降而不是全梯度下降,这个有兴趣的同学可以查阅资料自己证明一下随机梯度下降最后其实也是收敛的,但是在这里我们不做过多叙述,下面用实例给出更具体的执行步骤:
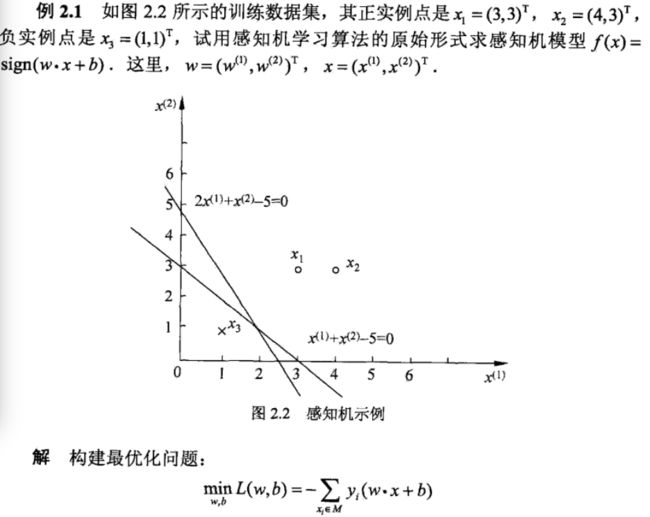

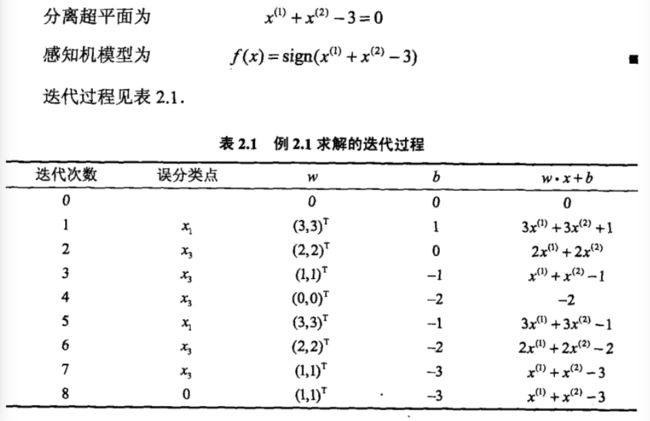
到此为止,我们应该大致了解了感知机的一些基础的知识,这有助于日后我们对支持向量机的理解,至于对该感知机学习算法的对偶形式和收敛性的证明有兴趣的可以去看李航博士的统计学习方法一书,网上也有很多相关资料,这里强烈建议看一下该算法对偶性相关的文章
写在最后
我们上边算法的取点顺序为1,3,3,3,1,3,3,如果在计算误分类点依次取1,3,3,3,2,3,3,3,1,3,3呢?我们这时得到的分离超平面就不同了,也就是说感知机学习算法最终确定下来的w和b是受初值或选取不同的误分类点影响的,如下图:
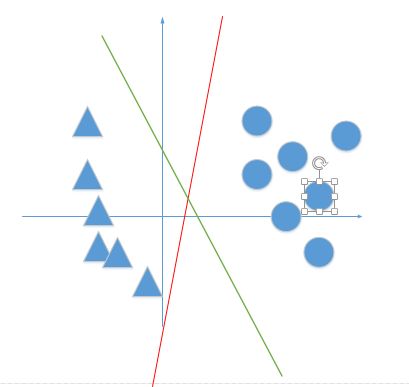
其实绿线和红线都是分离超平面,但是其实绿色的效果更好,这也就是为什么现在大多数项目都采用支持向量机的原因了...