主要内容源自解读《Fluent Python》,理解如有错误敬请指正:-)
- dict对象的最原始的接口描述是 collections 模块中的 Mapping 和 MutableMapping 这两个虚拟类,如下所示:
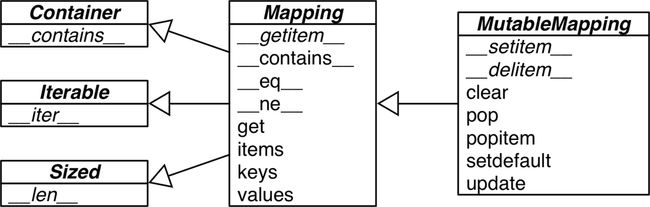
但是自定义的mapping类却大多继承 dict 或者 collections.UserDict 类来实现。不过通常可以使用
isinstance(mapObj, collections.Mapping) 而不是
isinstance(mapObj, dict) 这样的方式来更广义地判断一个对象是不是一个符合标准map接口的对象
- Python官方文档中对于一个对象是否可哈希(Hashable),定义为:
An object is hashable if it has a hash value which never changes during its lifetime (it needs a hash()
method), and can be compared to other objects (it needs an eq()
or cmp()
method). Hashable objects which compare equal must have the same hash value.
核心就是该对象必须要实现 __hash()__ 方法 和 __eq__() 方法,前者就是计算该对象的hash值,是内建函数 hash(obj) 的实际工作方法,可哈希的对象的哈希值必须是恒久不变的,并且__eq__()判断为相等的两个对象的哈希值也必须相同。
Python中内建的Hashable对象包括:str、bytes、数字类型、frozenset等immutable对象,所有的可变序列对象都不是可哈希的,对于tuple则仅当其中所有的元素都是Hashable对象时才是可哈希的。
用户自定义的对象通常是可哈希的,这是因为这些对象的 __hash__() 方法默认返回的是该对象的id(即id(obj)返回的值),而一个对象的id是唯一的
>>> hash((1,2,3,4))
485696759010151909
>>> hash((1,2,[3,4]))
Traceback (most recent call last):
File "", line 1, in
hash((1,2,[3,4]))
TypeError: unhashable type: 'list'
>>> hash((1,2,frozenset([3, 4])))
-4138728974339688815
>>> class MyObj:
pass
>>> hash(MyObj())
273870000
>>> hash(MyObj())
273869928
—— Python标准库中的所有mapping类型对象,都满足其所有的key必须为可哈希对象的条件,这样也才能够保证mapping对象中key的唯一性
- dict对象常用的几种定义方式如下:
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)]) # 元素类型为(key, value)的list、tuple等iterable对象都可以直接进行dict化
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
除此以外,还可以使用类似于 listcomps 的推导表示方法,基于元素类型为(key, value)的list、tuple等iterable对象,外层使用 大括号对{}来推导生成dict对象,即所谓的“dict comprehensions”
>>> areaCodeList = [
("Beijing", "010"), ("Guangzhou", "020"), ("Shanghai", "021"), ("Tianjin", "022"), ("Chongqing","023"),
("Shenyang", "024"), ("Nanjing", "025"), ("Wuhan", "027"), ("Chengdu", "028"), ("Xian", "029")]
>>> { code : city for city,code in areaCodeList}
{'025': 'Nanjing', '010': 'Beijing', '024': 'Shenyang', '027': 'Wuhan', '021': 'Shanghai', '020': 'Guangzhou',
'023': 'Chongqing', '022': 'Tianjin', '029': 'Xian', '028': 'Chengdu'}
>>> { code : city for city,code in areaCodeList if code.startswith("02")}
{'025': 'Nanjing', '024': 'Shenyang', '027': 'Wuhan', '021': 'Shanghai', '020': 'Guangzhou', '023': 'Chongqing',
'022': 'Tianjin', '029': 'Xian', '028': 'Chengdu'}
-
dict、defaultdict、OrderedDict三种常用的mapping对象的主要方法和比较如下所示:

所有的mapping类型对象都可以通过 update( ) 函数,传入新的mapping,或(key, value)作为元素的iterable对象,或者**kwargs参数进行内容的升级:
>>> dic1 = {"Beijing":"error"}; dic1
{'Beijing': 'error'}
>>> dic1.update(areaCodeList, Shenzhen="0755", Hangzhou="0571"); dic1
{'Beijing': '010', 'Shanghai': '021', 'Chengdu': '028', 'Tianjin': '022', 'Guangzhou': '020', 'Xian': '029', 'Nanjing': '025',
'Wuhan': '027', 'Hangzhou': '0571', 'Shenzhen': '0755', 'Shenyang': '024', 'Chongqing': '023'}
- mapping对象的 mapObj.setdefault(key, [default]) 是一个值得特别注意的方法,我们不要被它的名字所迷惑而以为它是一个纯粹设置mapping对象中元素默认值的方法,它首先是一个读取指定key的value的方法,将会返回mapObj中的一个key的value,只是这个value将根据传入的key是否在当前的mapObj中而有所不同,如果不存在key将会在mapObj中加入 key:default 的元素,并返回default;如果key存在,则直接返回当前key对应的value值,而不会去修改当前key的值为default。
>>> dic2 = {}
>>> dic2.setdefault("key1"); dic2
{'key1': None}
>>> dic2.setdefault("key2",[])
[]
>>> dic2
{'key2': [], 'key1': None}
>>> dic2.setdefault("key3","hello")
'hello'
>>> dic2
{'key3': 'hello', 'key2': [], 'key1': None}
>>> dic2.setdefault("key2")
[]
>>> dic2.setdefault("key3", "value3") # 这一步并不会将key3对应的value进行修改
'hello'
>>> dic2
{'key3': 'hello', 'key2': [], 'key1': None}
>>>
使用setdefault( )方法的优点主要是:
(1)、这个方法的调用不会出现因为key不存在而抛异常的情况,
(2)、对于需要先判断mapObj中是否包含某个key,然后再进行下一步操作的逻辑,使用这个方法将会使代码逻辑很简单,并且至少减少一次为了确认mapObj是否包含key而对整个mapObj对象key的遍历。
- mapping对象中对于 mapObj[key] 这个语法的支持本质上是调用 mapObj.__getitem__(key) 方法,但是当 __getitem__(key) 方法无法找到key的时候,mapObj对象的 __missing__(key) 方法就会被调用。
(1). 对于dict对象,__missing__(key) 默认会抛出 KeyError 异常;
(2). 对于 collections.defaultdict 对象,__missing__(key) 默认将会调用mapObj对象的default_factory属性,由default_factory来生成一个对象作为key的value——这一点功能类似于 setdefault( ) 方法
特别需要注意的一点是,__missing__( ) 方法的调用仅仅会由 mapObj[key] 这个语法来触发,而 mapObj.get(key, default) 这个方法的调用是不会触发__missing__方法的
>>> class MyDict(dict):
def __missing__(self, k):
return "MissingValue of %s" % str(k)
>>> my_dict = MyDict()
>>> my_dict["key1"]
'MissingValue of key1'
>>> my_dict
{}
>>> my_dict.get("key1") # get(k[, default]) 不会触发 __missing__( ) 方法被调用
>>> my_dict.get("key1", 3)
3
- collections.defaultdict 对象作用类似于 mapping 对象通用的 setdefault(key, default) 方法,可以避免因为key不存在而导致mapObj[key] 语法触发KeyError异常。二者的区别在于defaultdict对象是在初始化的时候指定default值产生的方式,而setdefault( ) 方法则是在被调用的时候来动态决定default值。
defaultdict对象初始化时需要传入default_factory参数,这个参数是一个能够被调用的属性,既可以是一个有返回值的函数,也可以是一个类(被调用时即调用该类的初始化方法来返回一个对象)
>>> import collections, time
>>> defdict1 = collections.defaultdict(list)
>>> defdict1
defaultdict(, {})
>>> defdict1['key1']
[]
>>> defdict1
defaultdict(, {'key1': []})
>>> def func():
return "CurMilli: %d" % int(time.time() * 1000)
>>> defdict2 = collections.defaultdict(func)
>>> defdict2['key2']
'CurMilli: 1474045511728'
>>> defdict2
defaultdict(, {'key2': 'CurMilli: 1474045511728'})
- 当构造一个dict的时候,其中的 key:value 对并不是按照插入dict对象时的顺序来的。例如:
>>> areaCodeList
[('Beijing', '010'), ('Guangzhou', '020'), ('Shanghai', '021'), ('Tianjin', '022'), ('Chongqing', '023'), ('Shenyang', '024'),
('Nanjing', '025'), ('Wuhan', '027'), ('Chengdu', '028'), ('Xian', '029')]
>>> areaDict = {code : city for city, code in areaCodeList}
>>> areaDict # 其中的item的顺序和areaCodeList中的顺序并不一致
{'025': 'Nanjing', '010': 'Beijing', '024': 'Shenyang', '027': 'Wuhan', '021': 'Shanghai', '020': 'Guangzhou',
'023': 'Chongqing', '022': 'Tianjin', '029': 'Xian', '028': 'Chengdu'}
如果需要保持这些 key:value 对插入的顺序,则需要使用 collections.OrderedDict 类:
>>> areaCodeList
[('Beijing', '010'), ('Guangzhou', '020'), ('Shanghai', '021'), ('Tianjin', '022'), ('Chongqing', '023'), ('Shenyang', '024'),
('Nanjing', '025'), ('Wuhan', '027'), ('Chengdu', '028'), ('Xian', '029')]
>>> sortedAreaDict = collections.OrderedDict([(code, city) for city, code in areaCodeList])
>>> sortedAreaDict
OrderedDict([('010', 'Beijing'), ('020', 'Guangzhou'), ('021', 'Shanghai'), ('022', 'Tianjin'),
('023', 'Chongqing'), ('024', 'Shenyang'), ('025', 'Nanjing'), ('027', 'Wuhan'), ('028', 'Chengdu'), ('029', 'Xian')])
>>> sortedAreaDict.popitem()
('029', 'Xian')
>>> sortedAreaDict.popitem(last=False)
('010', 'Beijing')
- collections.Counter 是一个很有意思的类,它是一个可用于统计Hashable对象数量的dict子类,其key就是待统计的Hashable对象,value就是这些对象的统计计数。Counter对象的 most_common(n) 方法可以很方便地统计出出现次数多的n个key
>>> import collections, random
>>> players =['Wilt Chamberlain', 'Michael Jordan', 'Kareem Abdul-Jabbar', 'Earvin Johnson', 'Kobe Bryant',
'LeBron James', 'Stephen Curry', 'Bill Russell')
>>> for i in range(100):
votesForVIP += [random.choice(players)] * random.randrange(10,20)
>>> len(votesForVIP)
1433
>>> counter = collections.Counter(votesForVIP)
>>> counter
Counter({'Kobe Bryant': 233, 'Kareem Abdul-Jabbar': 210, 'Bill Russell': 196, 'Stephen Curry': 183,
'Michael Jordan': 178, 'Earvin Johnson': 155, 'LeBron James': 139, 'Wilt Chamberlain': 139})
>>> counter.most_common(3)
[('Kobe Bryant', 233), ('Kareem Abdul-Jabbar', 210), ('Bill Russell', 196)]
-
用户自定义类dict的class的时候,通常不要直接以dict作为父类,这是因为在覆盖重写dict类的 get(k, default)、__setitem__( )、__contain__( )、__missing__( ) 等方法时,常常又会使用到 mapObj[k]、 k in mapObj、mapObj[k] 等语法形式,这样一不小心就会造成这些内部方法的无穷递归调用。因此更建议使用 collections.UserDict 类而非dict来作为自定义mapping的父类。
collections.UserDict 名字中包含"dict",但是它并不是dict的子类,而是 collections.MutableMapping 的子类,因此UserDict类也继承了 __getitem__( )、__contain__( )、__setitem__( )等方法。UserDict类与dict的关联是通过UserDict对象中包含一个dict类型的成员变量 data 来实现的,data就作为真正的dict数据内容的保存地。用户自定义类dict class覆盖重写这些方法的时候,并不会递归调用UserDict类中其他的方法,而是对UserDict.data 变量进行相关操作,从而大大减轻了用户自定义类时对于死循环递归的防范难度,如下示例:
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key): # 对self.data操作不会导致自身的 __contains__ 函数的递归调用
return str(key) in self.data
def __setitem__(self, key, item): # 对self.data操作不会导致自身的 __setitem__ 函数的递归调用
self.data[str(key)] = item
set 和 frozenset 中每一个元素都是唯一而不重复的,这样的唯一性正是通过每个元素对象的hash值唯一来保证的,因此:
(1)、set和frozenset中每一个元素对象必须是Hashable对象
(2)、set本身不是Hashable对象(因为set是mutable对象)
(3)、frozenset本身是immutable 对象,因此其本身也是Hashable对象set和frozenset的定义方式包括:
>>> # 直接通过iterable对象来构建
>>> s = set([1,2,3,4,5,5,4,3,2,1,6,7,8,9,0,9,8,7,6])
>>> s
set([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> # 对于所有元素都是直接常量值的set定义
>>> s = {1,2,3,4,5,6,5,4,3,2,1,0,9,8,7,6}
>>> s
set([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> # 但是定义空的set只能使用 set() 的方式,否则 {} 将会被当做是空的dict而非空的set
>>> empty_set = set(); type(empty_set)
>>> empty_dict = {}; type(empty_dict)
>>> # 使用 set comprehensions 推导方式,
>>> # 与dictcomps语法都是使用花括号{ },区别在于dictcomps使用 {key:value for ...} 形式而setcomps使用 {value for ... }形式
>>> from unicodedata import name
# 对于Python 2.7
>>> {unichr(i) for i in range(32,256) if 'SIGN' in name(unichr(i), "")}
set([u'#', u'\xa2', u'%', u'$', u'\xa7', u'\xb0', u'\xa9', u'+', u'\xf7', u'\xa3', u'\xac', u'\xb1', u'\xa4', u'\xb5', u'\xd7',
u'\xb6', u'\xa5', u'\xae', u'=', u'<', u'>'])
#对于Python 3
>>> {chr(i) for i in range(32,256) if 'SIGN' in name(chr(i), "")}
{'©', '<', '>', '¥', '¬', '§', '=', '#', '¢', '£', 'µ', '¶', '¤', '+', '®', '÷', '%', '°', '$', '×', '±'}
# fronzenset只有一种定义方式:
>>> fs = frozenset([1,3,5,7,9])
- set 在数学上对应着集合的概念,因此除了基本的加减运算之外,数学上的集合运算(and, or, xor, sub等)对于set对象也是完全支持的。
>>> set1 = {i for i in range(20)}; set1
set([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
>>> set2 = {i for i in range(10) if i%2==0}; set2
set([0, 8, 2, 4, 6])
>>> set3 = {i for i in range(10) if i%2!=0}; set3
set([1, 3, 9, 5, 7])
>>> set4 = {i for i in range(20) if i%2==0}; set4
set([0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
>>> set5 = {i for i in range(20) if i%2!=0}; set5
set([1, 3, 5, 7, 9, 11, 13, 15, 17, 19])
>>>
>>> set1 & set2
set([0, 8, 2, 4, 6])
>>> set1 ^ set2 # set1和set2中各自包含但是对方不包含的元素的集合
set([1, 3, 5, 7, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
>>> set2 | set3
set([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>>
>>> set1.intersection(set2, set4) # set1.intersection(set2, set4, ...) 相当于 set1 & set2 & set4 &...
set([0, 8, 2, 4, 6])
>>> set1.intersection(set2, set3)
set([])
>>> set2.union(set3)
set([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> set2.union(set3, set4) # set2.union(set3, set4, ...) 相当于 set2 | set3 | set4 | ...
set([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 14, 16, 18])
>>>
>>> set1 - set2
set([1, 3, 5, 7, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
>>> set2 - set1 # 因为set2是set1的子集,所以set2 - set1的结果为空
set([])
>>> set1.difference(set2, set3) # set1.difference(set2, set3, ...) 相当于 set1 - set2 - set3 - ...
set([10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
>>> set2.symmetric_difference(set1) # symmetric_difference( ) 函数就是亦或函数,等同于set2 ^ set1
set([1, 3, 5, 7, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
>>>
>>> set1.isdisjoint(set2) # isdisjoint( ) 函数等同于判断两个set的交集是否为空,即 len(set1 & set) == 0
False
>>> set2.isdisjoint(set3)
True