协程
协程,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
协程的好处:
- 无需线程上下文切换的开销
- 无需原子操作锁定及同步的开销
- 方便切换控制流,简化编程模型
- 高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
Greenlet
1 from greenlet import greenlet 2 3 def test1(): 4 print(1) 5 gr2.switch() 6 print(4) 7 gr2.switch() 8 def test2(): 9 print(2) 10 gr3.switch() 11 print(5) 12 gr3.switch() 13 def test3(): 14 print(3) 15 gr1.switch() 16 print(6) 17 gr1 = greenlet(test1) 18 gr2 = greenlet(test2) 19 gr3 = greenlet(test3) 20 gr1.switch() 21 22
Gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
1 import gevent 2 3 def test1(): 4 print(1) 5 gevent.sleep(2) 6 print(4) 7 def test2(): 8 print(2) 9 gevent.sleep(1) 10 print(5) 11 def test3(): 12 print(3) 13 gevent.sleep(0) 14 print(6) 15 gevent.joinall([ 16 gevent.spawn(test1), 17 gevent.spawn(test2), 18 gevent.spawn(test3), 19 ])
同步与异步的性能区别
1 import gevent 2 3 def task(pid): 4 """ 5 Some non-deterministic task 6 """ 7 gevent.sleep(0.5) 8 print('Task %s done' % pid) 9 10 def synchronous(): 11 for i in range(1,10): 12 task(i) 13 14 def asynchronous(): 15 threads = [gevent.spawn(task, i) for i in range(10)] 16 gevent.joinall(threads) 17 18 print('Synchronous:') 19 synchronous() 20 21 print('Asynchronous:') 22 asynchronous()
上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
遇到IO阻塞时会自动切换任务
1 from gevent import monkey; monkey.patch_all() 2 import gevent 3 from urllib.request import urlopen 4 5 def f(url): 6 print('GET: %s' % url) 7 resp = urlopen(url) 8 data = resp.read() 9 print('%d bytes received from %s.' % (len(data), url)) 10 11 gevent.joinall([ 12 gevent.spawn(f, 'https://www.python.org/'), 13 gevent.spawn(f, 'https://www.yahoo.com/'), 14 gevent.spawn(f, 'https://github.com/'), 15 ])
通过gevent实现单线程下的多socket并发
server side
1 import sys 2 import socket 3 import time 4 import gevent 5 6 from gevent import socket,monkey 7 monkey.patch_all() 8 9 10 def server(port): 11 s = socket.socket() 12 s.bind(('0.0.0.0', port)) 13 s.listen(500) 14 while True: 15 cli, addr = s.accept() 16 gevent.spawn(handle_request, cli) 17 18 19 20 def handle_request(conn): 21 try: 22 while True: 23 data = conn.recv(1024) 24 print("recv:", data) 25 conn.send(data) 26 if not data: 27 conn.shutdown(socket.SHUT_WR) 28 29 except Exception as ex: 30 print(ex) 31 finally: 32 conn.close() 33 if __name__ == '__main__': 34 server(8001)
client side
1 import socket 2 3 HOST = 'localhost' # The remote host 4 PORT = 8001 # The same port as used by the server 5 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) 6 s.connect((HOST, PORT)) 7 while True: 8 msg = bytes(input(">>:"),encoding="utf8") 9 s.sendall(msg) 10 data = s.recv(1024) 11 #print(data) 12 13 print('Received', repr(data)) 14 s.close()
论事件驱动与异步IO
看图说话讲事件驱动模型
在UI编程中,常常要对鼠标点击进行相应,首先如何获得鼠标点击呢?
方式一:创建一个线程,该线程一直循环检测是否有鼠标点击,那么这个方式有以下几个缺点:
1. CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
2. 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
3. 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
方式二:就是事件驱动模型
目前大部分的UI编程都是事件驱动模型,如很多UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
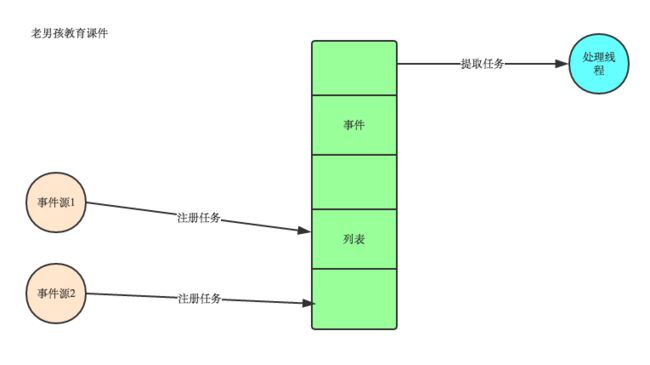
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外两种常见的编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务,而且…
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)而且…
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。