上篇文章(语音通信中终端上的时延(latency)及减小方法)说从本篇开始会切入webRTC中的netEQ主题,netEQ是webRTC中音频技术方面的两大核心技术之一(另一核心技术是音频的前后处理,包括AEC、ANS、AGC等,俗称3A算法)。webRTC是Google收购GIPS重新包装后开源出来的,目前已是有巨大影响力的实时音视频通信解决方案。国内的互联网公司,要做实时音视频通信产品,绝大多数都是基于webRTC来做的,有的是直接用webRTC的解决方案,有的是用webRTC里的核心技术,比如3A算法。不仅互联网公司,其他类型公司(比如通信公司),也会把webRTC里的精华用到自己的产品中。我刚开始做voice engine时,webRTC还未开源,但那时就知道了GIPS是一家做实时语音通信的顶级公司。webRTC开源后,一开始没机会用,后来做OTT语音(APP语音)时用了webRTC里的3A算法。在做了Android手机平台上的音频开发后,用了webRTC上的netEQ,不过用的是较早的C语言版本,不是C++版本,并且只涉及了netEQ中的DSP模块(netEQ有两大模块,MCU(micro control unit, 微控制单元)和DSP(digital signal processing, 信号处理单元),MCU负责控制从网络收到的语音包在jitter buffer里的插入和提取,同时控制DSP模块用哪种算法处理解码后的PCM数据,DSP负责解码以及解码后的PCM信号处理,主要PCM信号处理算法有加速、减速、丢包补偿、融合等),MCU模块在CP (communication processor, 通讯处理器)上做,两个模块之间通过消息交互。DSP模块经过调试,基本上掌握了机制。MCU模块由于在CP上做,没有source code,我就从网上找来了我们用的版本相对应的webRTC的开源版本,经过了一段时间的理解后,也基本上搞清楚了机制。从本篇开始,我将花几篇讲netEQ(基于我用的早期C语言版本)。这里需要说明的是每个产品在使用webRTC上的代码时都会根据自己产品的特点做一定的修改,我做的产品也不例外。我在讲时一些细节不会涉及,主要讲机制。本篇先对netEQ做一个概述。
实时IP语音通信的软件架构框图通常如下图:
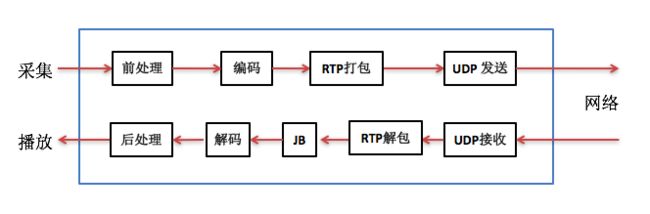
上图中发送方(或叫上行、TX)将从MIC采集到的语音数据先做前处理,然后编码得到码流,再用RTP打包通过UDP socket发送到网络中给对方。接收方(或叫下行、RX)通过UDP socket收语音包,解析RTP包后放入jitter buffer中,要播放时每隔一定时间从jitter buffer中取出包并解码得到PCM数据,做后处理后送给播放器播放出来。
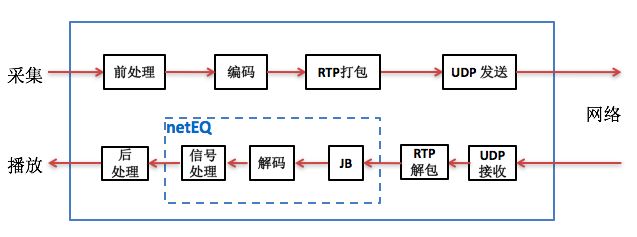
netEQ模块在接收侧,它是把jitter buffer和decoder综合起来并加入解码后的PCM信号处理形成,即netEQ = jitter buffer + decoder + PCM信号处理。这样上图中的软件架构框图就变成下图:
上文说过netEQ模块主要包括MCU和DSP两大单元。它的软件框图如下图:
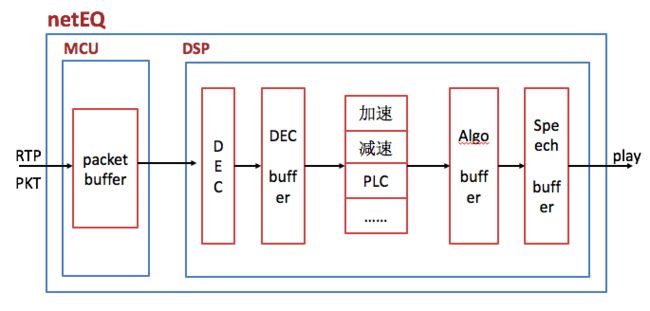
从上两图看出,jitter buffer(也就是packet buffer,后面就跟netEQ一致,表述成packet buffer,用于去除网络抖动)模块在MCU单元内,decoder和PCM信号处理模块在DSP单元内。MCU单元主要负责把从网络侧收到的语音包经过RTP解析后往packet buffer里插入(insert),以及从packet buffer 里提取(extract)语音包给DSP单元做解码、信号处理等,同时也算网络延时(optBufLevel)和抖动缓冲延时(buffLevelFilt),根据网络延时和抖动缓冲延时以及其他因素(上一帧的处理方式等)决定给DSP单元发什么信号处理命令。主要的信号处理命令有5种,一是正常播放,即不需要做信号处理。二是加速播放,用于通话延时较大的情况,通过加速算法使语音信息不丢而减少语音时长,从而减少延时。三是减速播放,用于语音断续情况,通过减速算法使语音信息不丢而增加语音时长,从而减少语音断续。四是丢包补偿,用于丢包情况,通过丢包补偿算法把丢掉的语音补偿回来。五是融合(merge),用于前一帧丢包而当前包正常收到的情况,由于前一包丢失用丢包补偿算法补回了语音,与当前包之间需要做融合处理来平滑上一补偿的包和当前正常收到的语音包。以上几种信号处理提高了在恶劣网络环境下的语音质量,增强了用户体验。可以说是在目前公开的处理语音的网络丢包、延时和抖动的方案中是最佳的了。
DSP单元主要负责解码和PCM信号处理。从packet buffer提取出来的码流解码成PCM数据放进decoded_buffer中,然后根据MCU给出的命令做信号处理,处理结果放在algorithm_buffer中,最后将algorithm_buffer中的数据放进speech_buffer待取走播放。Speech_buffer中数据分两块,一块是已播放过的数据(playedOut),另一块是未播放的数据(sampleLeft), curPosition就是这两种数据的分割点。另外还有一个变量endTimestamps用于记录最后一个样本的时间戳,并报告给MCU,让MCU根据endTimestamps和packet buffer里包的timestamp决定是否要能取出包以及是否要取出包。
这里先简要介绍一下netEQ的处理过程,后面文章中会详细讲。处理过程主要分两部分,一是把RTP语音包插入packet packet的过程,二是从packet buffer中提取语音包解码和PCM信号处理的过程。先看把RTP语音包插入packet packet的过程,主要有三步:
1,在收到第一个RTP语音包后初始化netEQ。
2,解析RTP语音包,将其插入到packet buffer中。在插入时根据收到包的顺序依次插入,到尾部后再从头上继续插入。这是一种简单的插入方法。
3,计算网络延时optBufLevel。
再看怎么提取语音包并解码和PCM信号处理,主要有六步:
1,将DSP模块的endTimeStamp赋给playedOutTS,和sampleLeft(语音缓冲区中未播放的样本数)一同传给MCU,告诉MCU当前DSP模块的播放状况。
2,看是否要从packet buffer里取出语音包,以及是否能取出语音包。取出包时用的是遍历整个packet buffer的方法,根据playedOutTS找到最小的大于等于playedOutTS的时间戳,记为availableTS,将其取出来。如果包丢了就取不到包。
3,算抖动缓冲延时buffLevelFilt。
4,根据网络延时抖动缓冲延时以及上一帧的处理方式等决定本次的MCU控制命令。
5,如果有从packet buffer里提取到包就解码,否则不解码。
6,根据MCU给的控制命令对解码后的以及语音缓冲区里的数据做信号处理。
在我个人看来,netEQ有两大核心技术点。一是计算当前网络延时和抖动缓冲延时的算法。要根据网络延时、抖动缓冲延时和其他因素决定信号处理命令,信号处理命令对了能提高音质,相反则会降低音质,所以说信号处理命令的决策非常关键。二是各种信号处理算法,主要有加速(accelerate)、减速(preemptive expand)、丢包补偿(PLC)、融合(merge)和背景噪声生成(BNG),这些都是非常专业的算法。