词袋模型表示
词袋:一篇文档由该文档中出现的词的集合所表示
- 集合是无序的
- 英文大小写转换
- 符号化识别词语边界(U.S.A)
- 词语形态标准化——使用词根Stemming
- 删除后缀
- 基于某些特殊规则
- 可能结果不是词语
- 不相关的词,stemming结果可能相同
- 词性还原——变为语法原形Lemmatization
处理过程考虑不同的词性 - 停用词:不具有内容信息的词
- 大幅减少索引大小
- 减少索引时间
- 不能提高检索效果
大部分互联网搜索引擎不适用Stemming/Lemmatization,使用停用词表
- 文档集大,各种词形都能匹配上
- 不太考虑召回率
- Stemming结果不完美
优点: 简单有效
缺点:忽略了词之间的句法关系、篇章的结构信息
文档余弦相似度计算
需要保证两个向量q和d的长度均为n

二值表示:非1即0,没有考虑词频,假设所有词语同等重要
TF-IDF


倒排索引构建与优点
倒排索引
以关键词为核心,对文档进行索引。帮助快速找到文档中的关键词
可以看成链表数组
- 每个链表的表头包含关键词,
- 后续单元是包括这个关键词的文档编号,以及其他信息,如词频,该词的位置等
问题:查询中包含多个关键词时如何匹配
倒排索引优势
- 关键词个数比文档少,检索效率高
- 特别适合信息检索——查询词一般很少,通过几次查询就能查询到所有可能的文档
倒排索引数据库
- 关键词查询——B-Tree / Hash
- 文档列表组织——二叉搜索树
处理方法
- 索引压缩
- 动态索引
- 分布式索引
布尔检索模型及其优缺点
基于布尔代数:
-
布尔操作符: AND, OR, NOT
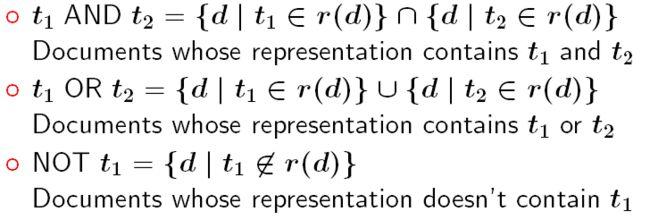 布尔操作符语义
布尔操作符语义
根据信息需求构造布尔查询:
President Bill Clinton = > Clinton AND (Bill OR President)
优点:
- 简单
- 对结果严格掌控
缺点:
- 一般用户难以构造布尔查询,耗时耗力
- 检索结果文档无法排序——只能是匹配/不匹配
- 根据布尔运算进行严格匹配,导致过多或过少的检索结果
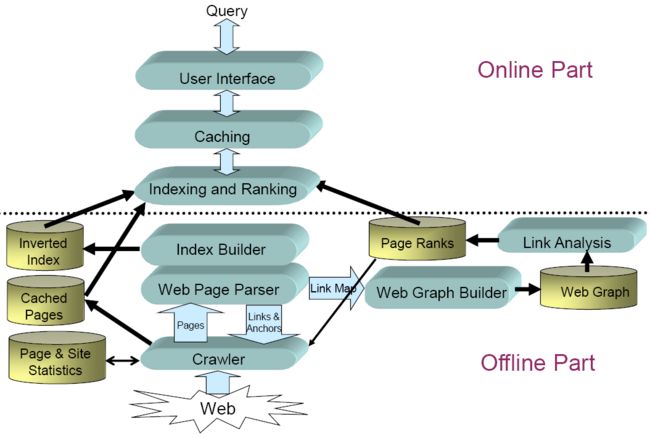
Web搜索架构
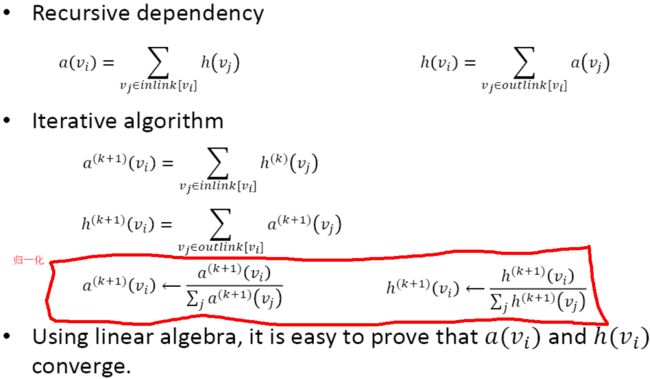
PageRank算法
随机游走模型(RW)
- 按页面的权威性和流行度排序
- 为图中的每个节点vi计算Pagerank值pi(vi)
- 可看做用户随机点击链接将会达到特定网页的可能性
页面的Pagerank值与父节点的Rank值成正比,与父节点的出度成反比
步骤:
- 得到邻接矩阵P
- 邻接矩阵归一化
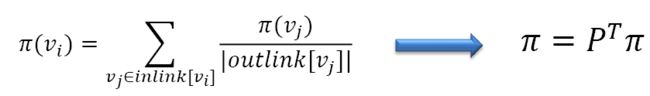
问题:
- 排序泄露:一个独立的网页没有outlink -->得到不合理的Rank值,影响收敛速度
- 排序沉入:多个节点形成闭环(loop),且没有outlink,不向外分发Rank --> 得到不合理Rank值,影响收敛速度
改进:RWwithRestart
随机游走过程中开始浏览一个新网页

HITS算法
对于图(子图)中的每一个节点vi,具有两个属性:
权威值authority——ai
一个页面被越多重要页面引用,则该页面权威值越大
枢纽值hub——hi
一个好的枢纽页面会链接到很多权威页面
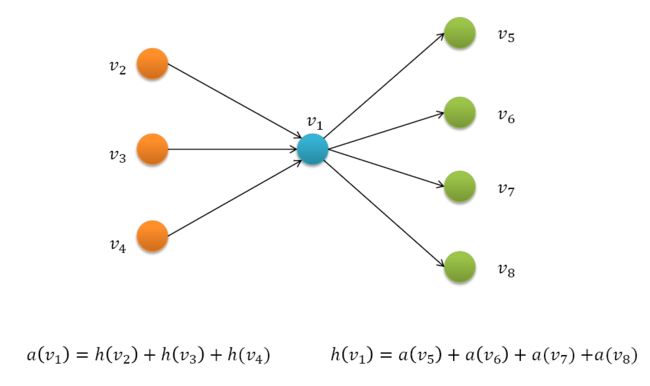

通过HITS计算得到的权威值枢纽值实际上就是邻接矩阵的奇异向量
信息检索评价指标MAP的计算
单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值。主集合的平均准确率(MAP)是每个主题的平均准确率的平均值。MAP 是反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前(rank 越高),MAP就可能越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。”

关联规则挖掘过程与Apriori算法;
关联规则:
反映一个事物与其它事物的相互依存性和关联性。如果两个事物存在关联性,那么其中一个事物就能由另一个事物预测到。
事物 = 事物id + 项的子集
关联规则(蕴含式)
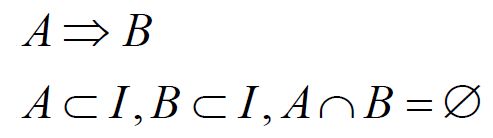
支持度sup(A,B)
置信度conf(A=>B) = P(B|A)
强关联规则:满足最小sup和最小conf的规则
关联规则挖掘:两个基本步骤
- 找出所有频繁项集——满足最小sup
- 找出所有强关联规则——由频繁项集生成,满足最小conf
挖掘关联规则的总体性能由第一步决定
Apriori
定理: 频繁项集的子集是频繁项集
中心思想: 由频繁k项集寻找频繁k+1项集
方法:
- 找到频繁1项集
- 扩展频繁k项集得到候选频繁k+1项集
- 删除不满足最小sup的候选项集
- 连接:k项集之间连接生成可能的候选
- 剪枝:使用Apriori性质,删除具有非频繁子集的候选项集
寻找关联规则
需要使用条件概率!!!P{2,3->4} = P{2,3,4}/P{2,3}
挑战
- 多次扫描事务数据库
- 巨大数量的候选项集
- 繁重的计算候选项集支持度工作
朴素贝叶斯分类算法
 Paste_Image.png
Paste_Image.png
K近邻分类算法
分类与回归的联系与区别
K均值聚类算法
凝聚式聚类算法
半监督聚类之COP K-means算法
自然语言处理领域的歧义现象
正向最大匹配分词与逆向最大匹配分词
无向图度数中心性、中介中心性与亲近中心性的计算(未规范化与规范化)
基于图排序(PageRank)的文档摘要方法

基于PMI的情感词汇获取方法及文本情感分类方法
步骤
只抽取包含形容词或副词的两个词构成的短语
短语phrase的语义倾向
• SO(phrase) = PMI(phrase, “excellent”) –
PMI(phrase, “poor”)
文档的语义倾向为所有短语语义倾向的平均值