上一篇->爬虫练习之数据清洗——基于Pandas
本次以51Job上在东莞地区爬取的以Java为关键词的招聘数据
包括salary company time job_name address字段
目的
本次数据整理的小目标是将薪资数据拿出来单独处理为统一的格式, 以便后续的数据统计分析和可视化操作
思路
先来看看数据有多丑
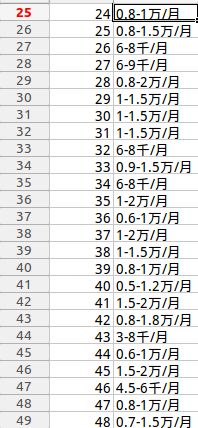
薪资原始数据示例
薪资原始数据示例
可以看到除了常规的几千/月, 还有几万/月, 以及几万/年
不过, 没看到XX以上的数据. 但是, 你还是要考虑到啊

根据数据格式, 可以把薪资拆成两行, 以 - 作为分割点, 然后对数据分情况整理, 根据拆分后数据位置得到底薪和薪资上限
代码
- 获取底薪
这里需要分三种情况(实际是四种, 不过XX千/年这种数据并没有出现)
XX千/月, XX万/月, XX万/年
思路是
判断: XX千/月, XX万/月, XX万/年
找到'-'位置
万/月和万/年需要进行转化
得到底薪
如果遇到没有上限的数据, 另外写个判断即可
函数代码如下
# coding=utf-8
def cut_word(word):
if(word.find('万') == -1):
# XX千/月
postion = word.find('-')
bottomSalary = word[postion-1]
else:
if(word.find('年') == -1):
# XX万/月
postion = word.find('-')
bottomSalary = word[postion-1] + '0.0'
else:
# XX万/年
postion = word.find('-')
bottomSalary = word[postion-1]
bottomSalary = str(int(bottomSalary) / 1.2)
return bottomSalary
- 获取薪资上限
获取薪资上限的思路与获取底薪的思路一致, 稍改代码即可
这里有一个中文坑, 在utf-8的编码环境下, 一个中文占3个字节, 所以像'万/年'这些, 要减去7才能得到正确结果, 而不是减去3
这里把两个方法合并于一个函数, 通过变量来获得上下限
考虑到还有0.X这种数字, 使用类似```bottomSalary = word[:(postion)] + '0.0'``这样的代码会出现以下情况
 错误示范
错误示范
函数代码如下
def cut_word(word, method):
if method == 'bottom':
if(word.find('万') == -1):
# XX千/月
postion = word.find('-')
bottomSalary = str(float(word[:(postion)]))
else:
if(word.find('年') == -1):
# XX万/月
postion = word.find('-')
bottomSalary = str(float(word[:(postion)]) * 10)
else:
# XX万/年
postion = word.find('-')
bottomSalary = word[:(postion)]
bottomSalary = str(int(bottomSalary) / 1.2)
return bottomSalary
if method == 'top':
length = len(word)
if(word.find('万') == -1):
# XX千/月
postion = word.find('-')
topSalary = str(float(word[(postion+1):(length-7)]))
else:
if(word.find('年') == -1):
# XX万/月
postion = word.find('-')
topSalary = str(float(word[(postion+1):(length-7)]) * 10)
else:
# XX万/年
postion = word.find('-')
topSalary = word[(postion+1):(length-7)]
topSalary = str(int(topSalary) / 1.2)
return topSalary
函数写完验证下结果
这里用到pandas模块的apply方法, 对某一行数据应用自定义函数
# 添加底薪列
df_clean['bottomSalary'] = df_clean.salary.apply(cut_word, method='bottom')
df_clean['topSalary'] = df_clean.salary.apply(cut_word, method='top')
# 选择salary, bottomSalary, topSalary列
df_clean[['salary', 'bottomSalary', 'topSalary']]
选择与薪水有关的列显示, 可以看到结果符合预期(后两列的单位是K)
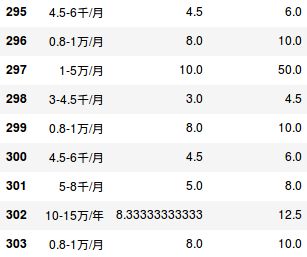
- 计算平均薪资
df_clean['bottomSalary'] = df_clean['bottomSalary'].astype('float')
df_clean['topSalary'] = df_clean['topSalary'].astype('float')
df_clean['avgSalary'] = df_clean.apply(lambda x : (x.bottomSalary + x.topSalary) / 2, axis = 1)
参考文献
知乎——用pandas进行数据分析实战
https://zhuanlan.zhihu.com/p/27784143