第四部分-推荐系统-模型训练
- 本模块基于第3节 数据加工得到的训练集和测试集数据 做模型训练,最后得到一系列的模型,进而做 预测。
训练多个模型,取其中最好,即取RMSE(均方根误差)值最小的模型
说明几点
1.ALS 算法不需要自己实现,Spark MLlib 已经实现好了,可以自己 跟源码学习
花时间钻研,动手写,写代码 翻译论文 写博客 多下功夫
- 最新http://spark.apache.org/docs/latest/ml-guide.html
- spark1.6.3
spark.mllib contains the original API built on top of RDDs.
spark.ml provides higher-level API built on top of DataFrames for constructing ML pipelines.
==》 我们采用spark.mllib ,也就是基于RDD之上来构建
学习:http://spark.apache.org/docs/1.6.3/mllib-collaborative-filtering.html#collaborative-filtering
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel
import org.apache.spark.mllib.recommendation.Rating
// Load and parse the data
val data = sc.textFile("data/mllib/als/test.data")
val ratings = data.map(_.split(',') match { case Array(user, item, rate) =>
Rating(user.toInt, item.toInt, rate.toDouble)
})
// Build the recommendation model using ALS
val rank = 10
val numIterations = 10
val model = ALS.train(ratings, rank, numIterations, 0.01)
// Evaluate the model on rating data
val usersProducts = ratings.map { case Rating(user, product, rate) =>
(user, product)
}
val predictions =
model.predict(usersProducts).map { case Rating(user, product, rate) =>
((user, product), rate)
}
val ratesAndPreds = ratings.map { case Rating(user, product, rate) =>
((user, product), rate)
}.join(predictions)
val MSE = ratesAndPreds.map { case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean()
println("Mean Squared Error = " + MSE)
// Save and load model
model.save(sc, "target/tmp/myCollaborativeFilter")
val sameModel = MatrixFactorizationModel.load(sc, "target/tmp/myCollaborativeFilter")看官方是怎么写代码的,参照着写
## 开始项目Coding
步骤一: 继续在前面的项目中,新建ml包,再新建ModelTraining
package com.csylh.recommend.ml
import org.apache.spark.mllib.recommendation.{ALS, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* Description:
* 训练多个模型,取其中最好,即取RMSE(均方根误差)值最小的模型
*
* @Author: 留歌36
* @Date: 2019-07-17 16:56
*/
object ModelTraining {
def main(args: Array[String]): Unit = {
// 面向SparkSession编程
val spark = SparkSession.builder()
.enableHiveSupport() //开启访问Hive数据, 要将hive-site.xml等文件放入Spark的conf路径
.getOrCreate()
val sc = spark.sparkContext
// 在生产环境中一定要注意设置spark.sql.shuffle.partitions,默认是200,及需要配置分区的数量
val shuffleMinPartitions = "8"
spark.sqlContext.setConf("spark.sql.shuffle.partitions",shuffleMinPartitions)
// 训练集,总数据集的70%
val trainingData = spark.sql("select * from trainingData")
// 测试集,总数据集的30%
val testData = spark.sql("select * from testData")
//--------------------------
// 训练集,转为Rating格式
val ratingRDD = trainingData.rdd.map(x => Rating(x.getInt(0), x.getInt(1), x.getDouble(2)))
// 用于计算模型的RMSE Rating(userid, movieid, rating) ==>转为tuple (userid, movieid)
val training2 :RDD[(Int,Int)] = ratingRDD.map{ case Rating(userid, movieid, rating) => (userid, movieid)}
// 测试集,转为Rating格式
val testRDD = testData.rdd.map(x => Rating(x.getInt(0), x.getInt(1), x.getDouble(2)))
val test2 :RDD[((Int,Int),Double)]= testRDD.map {case Rating(userid, movieid, rating) => ((userid, movieid), rating)}
//--------------------------
// 特征向量的个数
val rank = 1
// 正则因子
// val lambda = List(0.001, 0.005, 0.01, 0.015)
val lambda = List(0.001, 0.005, 0.01)
// 迭代次数
val iteration = List(10, 15, 18)
var bestRMSE = Double.MaxValue
var bestIteration = 0
var bestLambda = 0.0
// persist可以根据情况设置其缓存级别
ratingRDD.persist() // 持久化放入内存,迭代中使用到的RDD都可以持久化
training2.persist()
test2.persist()
for (l <- lambda; i <- iteration) {
// 循环收敛这个模型
//lambda 用于表示过拟合的这样一个参数,值越大,越不容易过拟合,但精确度就低
val model = ALS.train(ratingRDD, rank, i, l)
//---------这里是预测-----------------
val predict = model.predict(training2).map {
// 根据 (userid, movieid) 预测出相对应的rating
case Rating(userid, movieid, rating) => ((userid, movieid), rating)
}
//-------这里是实际的predictAndFact-------------------
// 根据(userid, movieid)为key,将提供的rating与预测的rating进行比较
val predictAndFact = predict.join(test2)
// 计算RMSE(均方根误差)
val MSE = predictAndFact.map {
case ((user, product), (r1, r2)) =>
val err = r1 - r2
err * err
}.mean() // 求平均
val RMSE = math.sqrt(MSE) // 求平方根
// RMSE越小,代表模型越精确
if (RMSE < bestRMSE) {
// 将模型存储下来
model.save(sc, s"/tmp/BestModel/$RMSE")
bestRMSE = RMSE
bestIteration = i
bestLambda = l
}
println(s"Best model is located in /tmp/BestModel/$RMSE")
println(s"Best RMSE is $bestRMSE")
println(s"Best Iteration is $bestIteration")
println(s"Best Lambda is $bestLambda")
}
}
}
步骤二:将创建的项目进行打包上传到服务器
mvn clean package -Dmaven.test.skip=true
步骤三:编写shell 执行脚本
[root@hadoop001 ml]# vim model.sh
export HADOOP_CONF_DIR=/root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
$SPARK_HOME/bin/spark-submit \
--class com.csylh.recommend.ml.ModelTraining \
--master spark://hadoop001:7077 \
--name ModelTraining \
--driver-memory 10g \
--executor-memory 5g \
/root/data/ml/movie-recommend-1.0.jar
步骤四:执行 sh model.sh 即可
sh model.sh之前:
[root@hadoop001 ~]# hadoop fs -ls /tmp
19/10/20 20:53:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 10 items
drwx------ - root supergroup 0 2019-04-01 16:27 /tmp/hadoop-yarn
drwx-wx-wx - root supergroup 0 2019-04-02 09:33 /tmp/hive
drwxr-xr-x - root supergroup 0 2019-10-20 19:42 /tmp/links
drwxr-xr-x - root supergroup 0 2019-10-20 19:42 /tmp/movies
drwxr-xr-x - root supergroup 0 2019-10-20 19:43 /tmp/ratings
drwxr-xr-x - root supergroup 0 2019-10-20 19:43 /tmp/tags
drwxr-xr-x - root supergroup 0 2019-10-20 20:19 /tmp/testData
drwxr-xr-x - root supergroup 0 2019-10-20 20:19 /tmp/trainingData
drwxr-xr-x - root supergroup 0 2019-10-20 20:18 /tmp/trainingDataAsc
drwxr-xr-x - root supergroup 0 2019-10-20 20:19 /tmp/trainingDataDesc
[root@hadoop001 ~]#sh model.sh之后:
这里运行很长时间,而且很有可能出现OOM。耐心等待~~

这些点都是要关注的,再就是shuffle 很重要
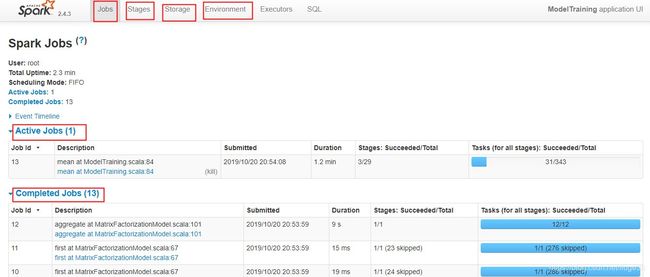
等待中。。。
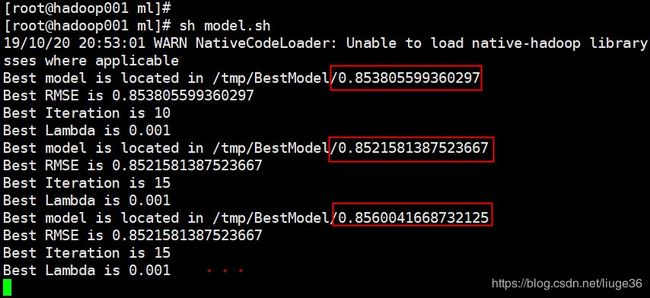
[root@hadoop001 ~]# hadoop fs -ls /tmp/BestModel
19/10/20 21:26:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
drwxr-xr-x - root supergroup 0 2019-10-20 21:00 /tmp/BestModel/0.8521581387523667
drwxr-xr-x - root supergroup 0 2019-10-20 20:56 /tmp/BestModel/0.853805599360297
[root@hadoop001 ~]#这里得到model /tmp/BestModel/0.8521581387523667 ,感觉不是很好。资源要是多一点的话,可以把迭代次数调大一点,估计模型可以更好。这里为了演示整个流程,模型差点就差点吧。思路搞懂就好。
有任何问题,欢迎留言一起交流~~
更多文章:基于Spark的电影推荐系统:https://blog.csdn.net/liuge36/column/info/29285