近年来,深度学习在计算机视觉领域已经占据主导地位,不论是在图像识别还是超分辨重现上,深度学习已成为图片研究的重要技术;现在深度学习技术已进入图片压缩领域。以图鸭最新研发的图片压缩——Tiny Network Graphics(TNG)为例,其通过深度学习卷积网络(CNN)的编码方式,可以在保持图片的质量下,尽可能降低图片的大小,使用户在带宽受限的网络情况下,仍然可以看到高清的图像;同时帮助图片类企业节约大量的带宽成本,具有较强的商业应用前景。
本文将和大家分享如何使用深度学习技术设计图像压缩算法。
说到图像压缩算法,目前市面上影响力比较大的图片压缩技术是WebP和BPG。
WebP:谷歌在2010年推出的一款可以同时提供有损压缩和无损压缩的图片文件格式,其以VP8编码为内核,在2011年11月开始可以支持无损和透明色功能。目前facebook、Ebay等网站都已采用此图片格式。
BPG:是知名程序员、ffmpeg 和QEMU等项目作者Fabrice Bellard推出的图像格式,它以HEVC编码为内核,在相同体积下,BPG文件大小只有JPEG的一半。另外BPG还支持8位和16位通道等等。尽管BPG有很好的压缩效果,但是HEVC的专利费很高,所以目前的市场使用比较少。
就压缩效果来说,BPG更高于WebP,但是BPG采用的HEVC内核所带来的专利费,导致其无法在市场进行大范围使用。采用了深度学习算法的TNG与 JPEG 相比,压缩率提升了 122%;与 WebP 相比,压缩率提高了 30%。而且相比 BPG/HEIF 等图片格式,TNG 采用了 CNN 技术可以避免高昂的专利费用,更利于商业化应用。
如何用深度学习技术设计图片压缩算法
通过深度学习技术设计压缩算法的目的之一是设计一个比目前商用图片压缩更优的压缩算法,同时借助于深度学习技术还可以设计更简洁的端到端算法。
在图片、视频压缩领域,主要用到的深度学习技术就是卷积神经网络(CNN)。如图1所显示,像搭积木一样,一个卷积神经网络由卷积、池化、非线性函数、归一化层等模块组成。最终的输出根据应用而定,如在人脸识别领域,我们可以用它来提取一串数字(专业术语称为特征)来表示一幅人脸图片,然后通过比较特征的异同进行人脸识别。
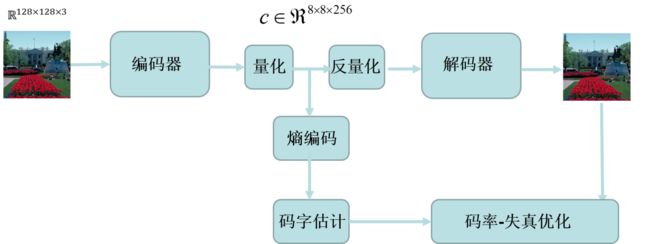
用深度学习设计的图片压缩完整框架包括CNN编码器、量化、反量化、CNN解码器、熵编码、码字估计、码率-失真优化等几个模块。编码器的作用是将图片转换为压缩特征,解码器就是从压缩特征恢复出原始图片。其中编码器和解码器,可以用卷积、池化、非线性等模块进行设计和搭建。
如何评判压缩算法
在深入技术细节前,我们先来了解一下如何评判压缩算法。评判一个压缩算法好坏的重要指标有三个:PSNR(Peak Signal to Noise Ratio)、BPP(bit per pixel)和MS-SSIM(multi-scaleSSIM index)。我们知道,任何数据在计算机内都是以比特形式存储,所需比特数越多则占据的存储空间越大。PSNR用来评估解码后图像恢复质量,BPP用于表示图像中每个像素所占据的比特数,MS-SSIM值用来衡量图片的主观质量,简单来说在同等的Rate/BPP下PSNR更高,恢复质量越好,MSSIM更高,主观感受越好。
举个例子,假设长宽为768*512的图片大小为1M,利用深度学习技术对它编码,通过编码网络后产生包括96*64*192个数据单元的压缩特征数据,如果表示每个数据单元平均需要消耗1个比特,则编码整张图需要96*64*192个比特。经过压缩后,编码每个像素需要的比特数为(96*64*192)/(768*512)=3,所以BPP值为3bit/pixel,压缩比为24:3=8:1。这意味着一张1M的图,通过压缩后只需要消耗0.125M的空间,换句话说,之前只能放1张照片的空间,现在可以放8张。
如何用深度学习做压缩
谈到如何用深度学习做压缩,还是用刚才那个例子。将一张大小768*512的三通道图片送入编码网络,进行前向处理后,会得到占据96*64*192个数据单元的压缩特征。有计算机基础的读者可能会想到,这个数据单元中可放一个浮点数、整形数、或者是二进制数。那到底应该放入什么类型的数据?从图像恢复角度和神经网络原理来讲,如果压缩特征数据都是浮点数,恢复图像质量是最高的。但一个浮点数占据32个比特位,按之前讲的比特数计算公式为(96*64*192*32)/(768*512)=96,压缩后反而每个像素占据比特从24变到96,非但没有压缩,反而增加了,这是一个糟糕的结果,很显然浮点数不是好的选择。
所以为了设计靠谱的算法,我们使用一种称为量化的技术,它的目的是将浮点数转换为整数或二进制数,最简单的操作是去掉浮点数后面的小数,浮点数变成整数后只占据8比特,则表示每个像素要占据24个比特位。与之对应,在解码端,可以使用反量化技术将变换后的特征数据恢复成浮点数,如给整数加上一个随机小数,这样可以一定程度上降低量化对神经网络精度的影响,从而提高恢复图像的质量。
即使压缩特征中每个数据占据1个比特位,可是 8:1的压缩比在我们看来并不是一个很理想的结果。那如何进一步优化算法?再看下BPP的计算公式。假设每个压缩特征数据单元占据1个比特,则公式可写成:(96*64*192*1)/(768*512)=3,计算结果是3 bit/pixel,从压缩的目的来看,BPP越小越好。在这个公式中,分母由图像决定,可以调整的部分在分子,分子中96、64、192这三个数字与网络结构相关。很显然,当我们设计出更优的网络结构,这三个数字就会变小。
那1与哪些模块相关?1表示每个压缩特征数据单元平均占据1个比特位,量化会影响这个数字,但它不是唯一的影响因素,它还与码率控制和熵编码有关。码率控制的目的是在保证图像恢复质量的前提下,让压缩特征数据单元中的数据分布尽可能集中、出现数值范围尽可能小,这样我们就可以通过熵编码技术来进一步降低1这个数值,图像压缩率会进一步提升。
用深度学习做视频压缩,可以看作是在深度学习图片压缩基础上的扩展,可结合视频序列帧间的光流等时空信息,在单张压缩的基础上,进一步降低码率。
深度学习图片压缩的优势
图鸭科技通过深度学习技术研发的图片压缩TNG在内部的测试上已经超过webp与BPG,下图是在kodak24标准数据集上测评结果,分别是PSNR值与MS-SSIM值。
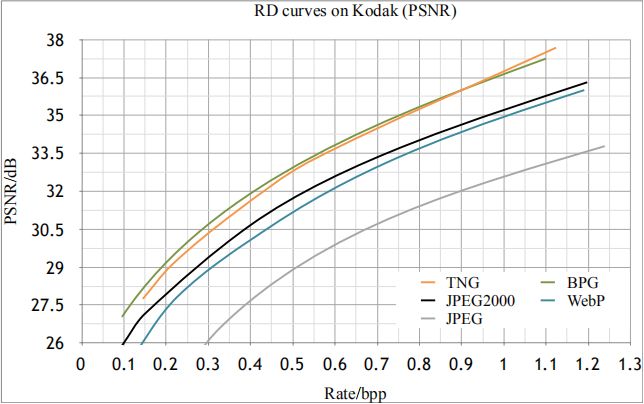
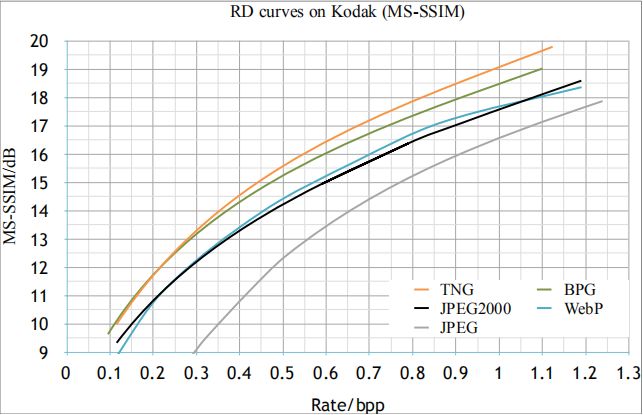
熟悉图像压缩的朋友可以直接通过PSNR和MS-SSIM值看出:TNG的PSNR值与MS-SSIM值明显高于WebP、jpeg2000和jpeg;且TNG在高码字的情况下PSNR值高于BPG,且其MS-SSIM值基本一致高于BPG。
在低码字情况下TNG与WebP压缩效果对比


相比TNG,WebP尽管保留了更多的细节,但是其失真更多,不利于后期恢复。而TNG采用了保边滤波的方法,让其失真更少,整体图像效果优于WebP。
在高码字情况下TNG与BPG对比


上面两幅图是高码字的情况,在实际的测试中,BPG会出现上图所示的颜色失真情况;而反观TNG其基本不会出现这类的失真状况。
这是因为BPG在编码压缩时尽管图片时,其YUV通道是分开进行编解码,产生了一些色差。
而TNG在编码时考虑到了整体图片的情况,采用了同一编码,也就避免了上述的情况。
在低码字的情况下TNG与BPG的对比


在低码字的情况下,BPG压缩图片中出现了伪轮廓和块效应等问题,整个图片的连续性比较差;而TNG的图片连续性和物体的轮廓保持的更好。
总结
总体而言,借助于深度学习设计图像压缩算法是一项非常具有前景但也非常具有挑战性的技术。目前,其已经在人脸识别等领域证明了它的强大能力,未来图像压缩领域的深度学习技术介入可以使大家在全面高清屏的时代有更优质的视觉体验,同时在游戏、空间图像传感等领域,深度学习图像压缩算法的应用也将带来更高分辨率,更小存储空间,更少带宽成本。
附上TNG的测试链接TNG测试