前言
我爬取了1000多条新闻,最后了解到学院近十年来的新闻所讲的大概内容是什么
好久没写爬虫了,最近学 新东西弄得头有点秃, 我寻思做点什么有意思的东西换换心情,于是瞄准了学校的新闻网。
免责声明:本文仅供学习交流,如出现任何法律问题本人概不负责!
0. 准备工作
环境:
- Windows 10
- Python 3.6.5
需要用到的库:
- requests - 用于网络请求
- jieba - 用于分词
- wordcould - 制作词云
- bs4 - 用于解析
- threading - 多线程
- queue - 保证线程的安全使用
以上库都可以用 pip 进行下载
1. 构造所有页面
首先打开新闻网进入到"学院要闻"这个版块,然后点击下一页看看 URL 是如何变化的。
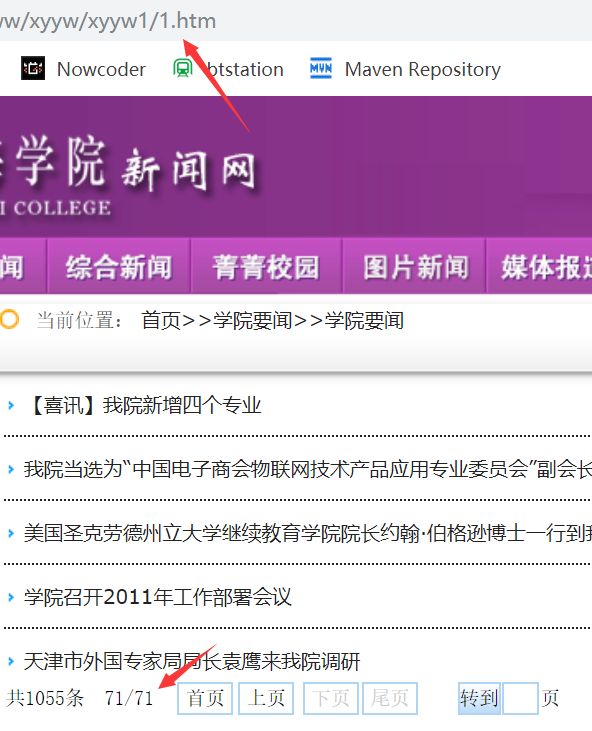
进入到最后一页,发现URL是 http://binhai.nankai.edu.cn/xww/xyyw/xyyw1/1.htm
进入到倒数第二页,URL变成 http://binhai.nankai.edu.cn/xww/xyyw/xyyw1/2.htm
那再看首页 http://binhai.nankai.edu.cn/xww/xyyw/xyyw1.htm
可以发现首页并不遵循这个规律,怎么办?将之独立出来进行爬取。
于是可以这样构造 URL
# 爬取1到70页,首页独立出来进行爬取
for x in range(1, 71):
url = 'http://binhai.nankai.edu.cn/xww/xyyw/xyyw1/%d.htm' % x
2. 获取所有新闻链接
构造好所有页面的 URL 之后,接下来就是要针对每个页面进行爬虫,获取我们所需要的数据。这里我们需要的是每个新闻的链接、
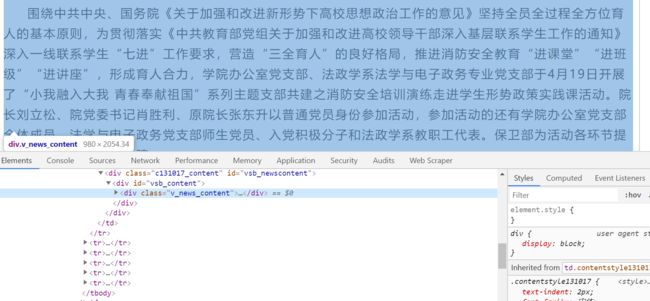
从图中可以看到,每个链接都是在标签为 a,属性为 class="c131013"中。我们只需要获取到每一个 a 标签就可以拿到想要的数据了。
这里使用 BeautifulSoup 来进行解析,从而获取数据。
然后将获得的链接存放到一个列表里,以便后续使用
def getAllNewsUrl(url):
"""
获取所有新闻链接
:param url: 构造的所有页面的 URL
:return:
"""
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}
res = requests.get(url=url, headers=headers)
res.encoding = 'utf-8'
bsObj = BeautifulSoup(res.text, 'lxml')
for a in bsObj.select('a.c131013'):
allNewsUrl.append("http://binhai.nankai.edu.cn/xww/" + a['href'].replace('../../', ''))
需要注意的是用 requests 去请求的时候返回的内容中汉子是乱码,所以需要制定一下编码才能正常显示。
3. 获取所有新闻的内容
获取到每条新闻的链接后,接下来就是对每条新闻的内容进行爬取,这里也是使用 BeautifulSoup,同样的需要制定编码。
def getNewsContent(self, url):
"""
获取所有新闻的内容
:param url: 所有新闻的链接
:return:
"""
try:
res = requests.get(url=url, headers=self.headers)
res.encoding = 'utf-8'
bsObj = BeautifulSoup(res.text, 'lxml')
news_content = bsObj.select('div .v_news_content')[0].get_text().replace('\n', '')
# self.content_queue.put(news_content) # 将获取的新闻内容 put 到 queue 里
except:
return None
4. 使用多线程加快爬取速度
4.1 关于多线程,这里摘取了廖雪峰老师官网的部分内容:
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
进程是由若干线程组成的,一个进程至少有一个线程。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:thread和threading,thread是低级模块,threading是高级模块,对thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行
4.2 什么是Queue:
摘自与Python之queue模块
queue模块实现了多生产者,多消费者的队列。当要求信息必须在多线程间安全交换,这个模块在线程编程时非常有用 。Queue模块实现了所有要求的锁机制。说了半天就是Queue模块主要是多线程,保证线程安全使用的。这个类实现了三种类型的queue,区别仅仅在于进去和取出的位置。在一个FIFO(First In,First Out)队列中,先加先取。在一个LIFO(Last In First Out)的队列中,最后加的先出来(操作起来跟stack一样)。priority队列,有序保存,优先级最低的先出来。内部实现是在抢占式线程加上临时锁。但是没有涉及如何去处理线程的重入。
4.3 爬虫的完整代码
# -*- coding: utf-8 -*-
# Author:@渡舛
# 2019年7月10日
import sys
import time
import datetime
import requests
import threading
from queue import Queue
from bs4 import BeautifulSoup
allUrl = [] # 用于存放页面的 url
allNewsUrl = [] # 用于存放所有新闻的 URL
class Producer(threading.Thread):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}
def __init__(self, url_queue, content_queue, *args, **kwargs):
"""
生产者
:param url_queue: 新闻链接队列
:param content_queue: 新闻内容队列
:param args:
:param kwargs:
"""
super(Producer, self).__init__(*args, **kwargs)
self.url_queue = url_queue
self.content_queue = content_queue
def run(self):
while True:
if self.url_queue.empty():
break
url = self.url_queue.get()
self.getNewsContent(url)
def getNewsContent(self, url):
"""
获取所有新闻的内容
:param url: 所有新闻的链接
:return:
"""
try:
res = requests.get(url=url, headers=self.headers)
res.encoding = 'utf-8'
bsObj = BeautifulSoup(res.text, 'lxml')
news_content = bsObj.select('div .v_news_content')[0].get_text().replace('\n', '')
self.content_queue.put(news_content) # 将获取的新闻内容 put 到 queue 里
except:
return None
class Consumer(threading.Thread):
def __init__(self, url_queue, content_queue, *args, **kwargs):
"""
消费者
:param url_queue: 新闻链接队列
:param content_queue: 新闻内容队列
:param args:
:param kwargs:
"""
super(Consumer, self).__init__(*args, **kwargs)
self.url_queue = url_queue
self.content_queue = content_queue
def run(self):
while True:
newsContent = self.content_queue.get()
f = open('News.txt', 'a+', encoding='utf-8')
f.write(newsContent)
if self.url_queue.empty() and self.content_queue.empty():
f.close()
break
def getAllNewsUrl(url):
"""
获取所有新闻链接
:param url: 构造的所有页面的 URL
:return:
"""
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}
try:
res = requests.get(url=url, headers=headers)
res.encoding = 'utf-8'
bsObj = BeautifulSoup(res.text, 'lxml')
for a in bsObj.select('a.c131013'):
url = 'http://binhai.nankai.edu.cn/xww/' + a['href'].replace('../../', '')
if url not in allNewsUrl:
allNewsUrl.append(url)
except:
return None
def startCrawler():
url_queue = Queue(2000) # 所有新闻链接的队列
content_queue = Queue(100000) # 所有新闻内容的队列
# 构造所有页面的 URL, 一共有70页
for x in range(1, 71):
url = 'http://binhai.nankai.edu.cn/xww/xyyw/xyyw1/%d.htm' % x
getAllNewsUrl(url)
print("Message - [" + str(datetime.datetime.now()) + "] 共有" + str(len(allNewsUrl)) + " 条新闻")
# 将所有新闻链接 put 到 queue 里
print("Message - [" + str(datetime.datetime.now()) + "] 正在将所有新闻链接放到队列里...")
for url in allNewsUrl:
url_queue.put(url)
# 构造 5 个生产者
print("Message - [" + str(datetime.datetime.now()) + "] 开始构造生产者...")
for x in range(5):
t = Producer(url_queue, content_queue)
t.start()
# 构造 5 个消费者
print("Message - [" + str(datetime.datetime.now()) + "] 开始构造消费者...")
for x in range(5):
t = Consumer(url_queue, content_queue)
t.start()
多线程爬虫可以参考:
https://docs.python.org/zh-cn/3.6/library/threading.html
https://www.runoob.com/python/python-multithreading.html
https://zhuanlan.zhihu.com/p/38398256
https://cuiqingcai.com/3325.html
5. 制作词云
5.1 制作词云的完整代码
# -*- coding: utf-8 -*-
# Author:@渡舛
# 2019年7月10日
import jieba
from wordcloud import WordCloud
class Wordcloud(object):
def __init__(self):
pass
def createWordCloud(self):
text = open("News.txt", encoding='utf-8').read()
# 分词
wordlist = jieba.cut(text, cut_all=True)
wl = " ".join(wordlist)
# 设置词云
wc = WordCloud(
# 设置背景颜色
background_color="white",
# 设置最大显示的词云数
max_words=2000,
# 这种字体都在电脑字体中,一般路径
font_path='C:\Windows\Fonts\simfang.ttf',
height=1200,
width=1600,
# 设置字体最大值
max_font_size=100,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=30,
)
wc.generate(wl) # 生成词云
wc.to_file('py_book.png') # 把词云保存下
5.2 注意事项
使用 pip install wordcould安装词云模块的时候可能会报错,然而报错的原因不尽相同,所以大家在安装的时候如果安装失败了请自行解决
5.3 词云展示
总结
之前说的将"学院要闻"首页的新闻单独拿出来进行爬虫,也不是可以,但是我要吃饭去了就不写了,这个对最后的结果影响不大。读者们可以自行尝试。
由于新闻网的新闻较多,共有1000多条,在爬取的时候可以选择使用多线程或者多进程来加快爬取的速度,但是需要注意的是,要合理爬取,不要对网站造成破坏,爬取速度过快也会导致你的 IP 被封掉。这时候就需要反反爬虫技术的知识了。
咱们学院的新闻网也是存在反爬虫的。
1,访问过快会封掉 IP
2, 不加请求头不能返回正确页面
3, 好像就这么多了