
文/Bruce.Liu1
文章大纲
- 备份概念
1.1. 备份目的
1.2. 备份方式
1.3. 备份类型
1.4. 备份对象
1.5. 备份策略- mysqldump
2.1. mysqldump原理
2.2. 相关参数
2.3. 最佳实践- Xtrabackup
3.1. Xtrabackup原理
3.2. 文件介绍
3.3. 相关参数
3.4. 最佳实践- mydumper
4.1. mydumper原理
4.2. 相关参数
4.3. 最佳实践
1.备份概念
为什么要备份?我们试着想一想, 在生产环境中什么最重要?如果我们服务器的硬件坏了可以维修或者换新, 软件问题可以修复或重新安装, 但是如果数据没了呢?这可能是最恐怖的事情了吧,我感觉在生产环境中应该没有什么比数据跟更为重要. 那么我们该如何保证数据不丢失、或者丢失后可以快速恢复呢?只要看完这篇, 大家应该就能对数据备份和恢复能有一定的了解。
当年的911事件致使多少个金融公司遭受巨额损失,据初步估计,损失在100亿美元以上。办公室设在世贸大楼上的公司就更加倒霉,他们的业务几近瘫痪,大量数据丢失,其中著名的公司有美洲银行、朝日银行、德国银行、国际信托银行、肯珀保险公司、马什保险公司、帝国人寿保险公司、盖伊·卡彭特保险公司、坎特·菲兹杰拉德投资公司、摩根斯坦利金融公司、美国商品期货交易所。其中,摩根斯坦利损失最惨,因为它在世贸中心总共租用了29.8万平米的办公用地,公司很多职员连办公地点都没有。
更多的故障案例:
1. GitLab.com丢失6个小时数据,操作员将被迫看“10小时的彩虹猫”,以示惩罚!
2. 携程内部数据严重丢失问题
3. 谷歌数据中心遭雷劈 部分数据永久丢失
4. 9.11事件造成的建筑数据等财产直接损失达340亿美元
1.1.备份目的
在生产环境中我们数据库可能会遭遇各种各样的不测从而导致数据丢失,数据备份就是针对以下几种情况:
- 硬件故障
- 软件故障
- 自然灾害
- 黑客攻击
- 误操作 (占比最大)
总结:针对以上各种灾难性的场景发生,一个良好的备份,能恢复至故障前一秒正常的运行状态。
1.2.备份方式
备份方式
冷备(cold backup):需要关mysql服务,读写请求均不允许状态下进行;
1.即:停止数据库、将整个数据文件、日志文件、配置文件等拷贝至一个镜像。热备(hot backup):备份的同时,业务不受影响。
1.逻辑备份
a) mysqldump:官方自带的逻辑备份工具
b) mydumper:开源的多线程逻辑备份工具
2.物理备份
a) Enterprise Backup:官方企业级备份工具(收费产品)
b) Xtrabackup tools:业界中最著名的开源备份工具,由Percona公司研发。
引擎支持是否备份方式
| 引擎 | 热备 | 冷备 |
|---|---|---|
| MyISAM | × | √ |
| InnoDB | √ | √ |
| TokuDB | √ | √ |
备份工具是否支持引擎
- 逻辑的备份工具一般来说都支持各种引擎(逻辑的导出和底层的Engine没啥关系!!)
- 物理备份工具就有很大的局限性,著名的Xtrabackup也只是支持MyISAM、innodb引擎
1.3.备份类型
完全备份:
full backup,备份全部数据集。增量备份:
incremental backup,上次完全备份或增量备份以来改变了的数据,不能单独使用,要借助完全备份,备份的频率取决于数据的更新频率。差异备份:
differential backup,上次完全备份以来改变了的数据。
1.4. 备份对象
一般情况下, 我们需要备份的数据分为以下几种
- 全量数据
- 二进制日志, InnoDB事务日志
- 代码(存储过程、存储函数、触发器、事件调度器)
- 服务器配置文件
1.5.备份策略
在订制一个备份策略之前,首先我们先要向架构或业务部门了解清楚,我们的业务模型/场景类型/安全优先级/以及对数据恢复的时间要求等因素, 在我遇到的很多中小型公司/甚至连一些互联网金融机构等对于数据安全级别很高的场景中,对数据库备份策略也是一无所知,他们常见的做法几乎都是由信息部门数据库负责人或信息部技术意淫出来的。没有人会彻彻底底的观察场景/业务/以及安全级别等因素。
下面我们举常见的几种业务场景进行分析:
SNS社交网络服务类场景(Social Network Site)(国内常见的SNS如:微博/人人网/豆瓣/论坛)
a) 高并发
b) 高可靠性99.999%
c) 低数据一致性
d) 数据恢复时间要求高传统行业类业务场景(电力/物流/零售/服务/餐饮)
a) 普遍低并发
b) 高可靠性99.999%
c) 高数据一致性
d) 数据恢复时间一般传统金融类场景(银行/证券/股票)
a) 普遍低并发
b) 高可靠性99.999%
c) 高数据一致性
d) 数据恢复时间一般互联网金融/支付类场景(微信/支付宝/P2P/电子商务)
a) 并发一般
b) 高可靠性99.999%
c) 高数据一致性
d) 数据恢复时间高
以上任何一类业务场景中,对于可靠性都期望是99.999%,如果不知道什么是5个9,请自己默默的打开链接扫扫盲。但他们对于数据一致性要求却有着重大的不同。那有的同学会说了,可靠性和数据一致性可不可以兼顾呢?我相信大家都知道鱼和熊掌不可兼得的道理吧!
2.mysqldump
MySQL Client管理工具也叫:独立的管理实用程序,程序本身不依赖于其他程序模块。能够独立运行。这是MySQL的特性。
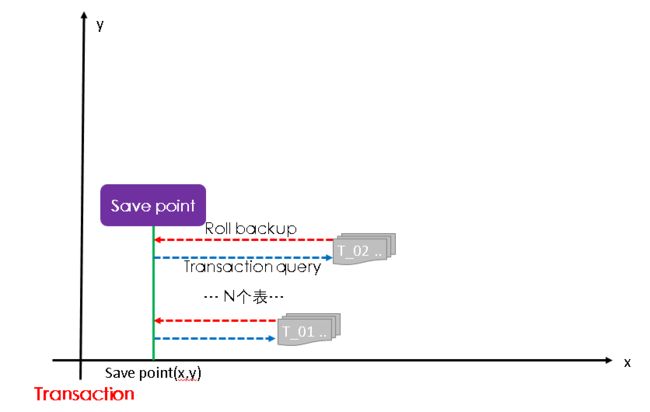
2.1.mysqldump原理
1.连接MySQL数据库,设置基本session级环境变量
2.开启快照级事务(加锁)并获取当前的GTID
3.释放锁资源
4.create savepoint
5.获取表结构信息/设置字符集/备份数据
6.roll back savepoint
7.重复步骤5~6直至备份完成
savepoint原理
2.2.相关参数
--all-databases , -A 导出全部数据库。
--all-tablespaces , -Y 导出全部表空间。
--no-tablespaces , -y 不导出任何表空间信息。
--add-drop-database 每个数据库创建之前添加drop数据库语句。
--add-drop-table 每个数据表创建之前添加drop数据表语句。(默认为打开状态)
--add-locks 在每个表导出之前增加LOCK TABLES并且之后UNLOCK TABLE。(默认为打开状态)
--allow-keywords 允许创建是关键词的列名字。这由表名前缀于每个列名做到。
--apply-slave-statements 在'CHANGE MASTER'前添加'STOP SLAVE',并且在导出的最后添加'START SLAVE'。
--character-sets-dir 字符集文件的目录
--comments 附加注释信息。默认为打开,可以用--skip-comments取消
--compatible 导出的数据将和其它数据库或旧版本的MySQL 相兼容。值可以为mysql323、mysql40、PG、oracle、mssql等,用逗号将它们隔开。它并不保证能完全兼容,而是尽量兼容。
--compact 导出更少的输出信息(用于调试)。去掉注释和头尾等结构。可以使用选项:--skip-add-drop-table --skip-add-locks --skip-comments --skip-disable-keys
--complete-insert, -c 使用完整的insert语句(包含列名称)。这么做能提高插入效率,但是可能会受到max_allowed_packet参数的影响而导致插入失败。
--compress, -C 在客户端和服务器之间启用压缩传递所有信息
--create-options, -a 在CREATE TABLE语句中包括所有MySQL特性选项。(默认为打开状态)
--databases, -B 导出几个数据库。参数后面所有名字参量都被看作数据库名。
--debug 输出debug信息,用于调试。默认值为:d:t:o,/tmp/mysqldump.trace
--debug-check 检查内存和打开文件使用说明并退出。
--debug-info 输出调试信息并退出
--default-character-set 设置默认字符集,默认值为utf8
--delayed-insert 采用延时插入方式(INSERT DELAYED)导出数据
--delete-master-logs master 备份后删除日志. 这个参数将自动激活--master-data。
--disable-keys 对于每个表,用/*!40000 ALTER TABLE tbl_name DISABLE KEYS */;和/*!40000 ALTER TABLE tbl_name ENABLE KEYS */;语句引用INSERT语句。该选项只适合MyISAM表,默认为打开状态。
--dump-slave 该选项将导致主的binlog位置和文件名追加到导出数据的文件中。设置为1时,将会以CHANGE MASTER命令输出到数据文件;设置为2时,在命令前增加说明信息。该选项将会打开--lock-all-tables,除非--single-transaction被指定。该选项会自动关闭--lock-tables选项。默认值为0。
--events, -E 导出事件。
--extended-insert, -e 使用具有多个VALUES列的INSERT语法。这样使导出文件更小,并加速导入时的速度。默认为打开状态,使用--skip-extended-insert取消选项。
--fields-terminated-by 导出文件中忽略给定字段。与--tab选项一起使用,不能用于--databases和--all-databases选项
--fields-enclosed-by 输出文件中的各个字段用给定字符包裹。与--tab选项一起使用,不能用于--databases和--all-databases选项
--fields-optionally-enclosed-by 输出文件中的各个字段用给定字符选择性包裹。与--tab选项一起使用,不能用于--databases和--all-databases选项
--fields-escaped-by 输出文件中的各个字段忽略给定字符。与--tab选项一起使用,不能用于--databases和--all-databases选项
--flush-logs 开始导出之前刷新日志。
--flush-privileges 在导出mysql数据库之后,发出一条FLUSH PRIVILEGES 语句。为了正确恢复,该选项应该用于导出mysql数据库和依赖mysql数据库数据的任何时候。
--force ,-f 在导出过程中忽略出现的SQL错误。
--help 显示帮助信息并退出。
--hex-blob 使用十六进制格式导出二进制字符串字段。如果有二进制数据就必须使用该选项。影响到的字段类型有BINARY、VARBINARY、BLOB。
--host, -h 需要导出的主机信息
--ignore-table 不导出指定表。指定忽略多个表时,需要重复多次,每次一个表。每个表必须同时指定数据库和表名。例如:--ignore-table=database.table1 --ignore-table=database.table2 ……
--include-master-host-port 在--dump-slave产生的'CHANGE MASTER TO..'语句中增加'MASTER_HOST=,MASTER_PORT='
--insert-ignore 在插入行时使用INSERT IGNORE语句.
--lines-terminated-by 输出文件的每行用给定字符串划分。与--tab选项一起使用,不能用于--databases和--all-databases选项。
--lock-all-tables, -x 提交请求锁定所有数据库中的所有表,以保证数据的一致性。这是一个全局读锁,并且自动关闭--single-transaction 和--lock-tables 选项。
--lock-tables, -l 开始导出前,锁定所有表。用READ LOCAL锁定表以允许MyISAM表并行插入。
--log-error 附加警告和错误信息到给定文件
--master-data 该选项将binlog的位置和文件名追加到输出文件中。如果为1,将会输出CHANGE MASTER 命令;如果为2,输出的CHANGE MASTER命令前添加注释信息。该选项将打开--lock-all-tables 选项,除非--single-transaction也被指定(在这种情况下,全局读锁在开始导出时获得很短的时间;其他内容参考下面的--single-transaction选项)。该选项自动关闭--lock-tables选项。
--max_allowed_packet 服务器发送和接受的最大包长度。
--net_buffer_length TCP/IP和socket连接的缓存大小。
--no-autocommit 使用autocommit/commit 语句包裹表。
--no-create-db, -n 只导出数据,而不添加CREATE DATABASE 语句。
--no-create-info, -t 只导出数据,而不添加CREATE TABLE 语句。
--no-data, -d 不导出任何数据,只导出数据库表结构。
--no-set-names, -N 等同于--skip-set-charset
--opt 等同于--add-drop-table, --add-locks, --create-options, --quick, --extended-insert, --lock-tables, --set-charset, --disable-keys 该选项默认开启, 可以用--skip-opt禁用.
--order-by-primary 如果存在主键,或者第一个唯一键,对每个表的记录进行排序。
--password, -p 连接数据库密码
--pipe(windows系统可用) 使用命名管道连接mysql
--port, -P 连接数据库端口号
--protocol 使用的连接协议,包括:tcp, socket, pipe, memory.
--quick, -q 不缓冲查询,直接导出到标准输出。默认为打开状态,使用--skip-quick取消该选项。
--quote-names,-Q 使用(`)引起表和列名。默认为打开状态,使用--skip-quote-names取消该选项。
--replace 使用REPLACE INTO 取代INSERT INTO.
--result-file, -r 直接输出到指定文件中。该选项应该用在使用回车换行对(\\r\\n)换行的系统上(例如:DOS,Windows)。该选项确保只有一行被使用。
--routines, -R 导出存储过程以及自定义函数。
--set-charset 添加'SET NAMES default_character_set'到输出文件。默认为打开状态,使用--skip-set-charset关闭选项。
--single-transaction 该选项在导出数据之前提交一个BEGIN SQL语句,BEGIN 不会阻塞任何应用程序且能保证导出时数据库的一致性状态。它只适用于多版本存储引擎,仅InnoDB。本选项和--lock-tables 选项是互斥的,因为LOCK TABLES 会使任何挂起的事务隐含提交。要想导出大表的话,应结合使用--quick 选项。
--dump-date 将导出时间添加到输出文件中。默认为打开状态,使用--skip-dump-date关闭选项。
--skip-opt 禁用–opt选项.
--socket,-S 指定连接mysql的socket文件位置,默认路径/tmp/mysql.sock
--tab,-T 为每个表在给定路径创建tab分割的文本文件。注意:仅仅用于mysqldump和mysqld服务器运行在相同机器上。
--tables ,定需要导出的表名,需要配合--databases (-B)参数一起使用
--triggers 导出触发器。该选项默认启用,用--skip-triggers禁用它。
--tz-utc 在导出顶部设置时区TIME_ZONE='+00:00' ,以保证在不同时区导出的TIMESTAMP 数据或者数据被移动其他时区时的正确性。
--user, -u 指定连接的用户名。
--verbose, --v 输出多种平台信息。
--version, -V 输出mysqldump版本信息并退出
--where, -w 只转储给定的WHERE条件选择的记录。请注意如果条件包含命令解释符专用空格或字符,一定要将条件引用起来。
--xml, -X 导出XML格式.
--plugin_dir 客户端插件的目录,用于兼容不同的插件版本。
--default_auth 客户端插件默认使用权限。
more info... ...
2.3.最佳实践
导出表结构
mysqldump --no-data --trigger=false mysql > mysql_01.sql
导出存储过程
mysqldump -f -Rtdn --trigger=false mysql > mysql_02.sql
导出触发器
mysqldump -f -tdn --trigger mysql > mysql_03.sql
导出事件
mysqldump -f -Etdn --trigger=false mysql > mysql_04.sql
导出数据
mysqldump -f --single-transaction --trigger=false -t mysql > mysql_05.sql
基于条件导出
mysqldump -t --single-transaction --where='cname="'jreey'"' tydb tab01 > /tmp/tab01.sql
导出某张表
mysqldump -S /data1/db3316/my3316.sock -pxxxxx --default-character-set=utf8 --single-transaction --set-gtid-purged=off --databases intelligent_os --tables beacon_base_pos > /tmp/beacon_base_pos.sql
实例一:数据库逻辑导出于恢复
备份一个数据库
mysqldump -S /data1/db3307/my3307.sock --default-character-set=utf8 --master-data=2 --no-create-db --single-transaction --set-gtid-purged=off -q --extended-insert --databases zabbix > /data1/mysqlbackup/m3307-20170306-dump.sql
恢复
mysql -S /data1/db3307/my3307.sock -e "create database zabbix"
mysql -S /data1/db3307/my3307.sock < /data1/mysqlbackup/m3307-20170306-dump.sql
补充:导出导入平面文件”
select * INTO OUTFILE '/tmp/errorlog.txt' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' from error_log;
load data infile '/tmp/errorlog.txt' into table test.error_log FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n';
3.Xtrabackup
xtrabackup是Percona公司CTO Vadim参与开发的一款基于InnoDB的在线热备工具,具有开源,免费,支持在线热备,备份恢复速度快,占用磁盘空间小等特点,并且支持不同情况下的多种备份形式。(该产品的出现解决了业界内MySQL社区版本中物理备份的空白)xtrabackup的官方下载地址为http://www.percona.com/software/percona-xtrabackup。
Xtrabackup是由percona提供的mysql数据库备份工具,据官方介绍,这也是世界上惟一一款开源的能够对innodb和xtradb数据库进行热备的工具。特点:
- 备份过程快速、可靠;
- 备份过程不会打断正在执行的事务;
- 能够基于压缩等功能节约磁盘空间和流量;
- 自动实现备份检验;
- 还原速度快;
xtrabackup包含两个主要的工具,即xtrabackup和innobackupex:
- xtrabackup只能备份innodb和xtradb两种引擎的表,而不能备份myisam引擎的表;
- innobackupex是一个封装了xtrabackup的Perl脚本,支持同时备份innodb和myisam,但在对myisam备份时需要加一个全局的读锁。还有就是myisam不支持增量备份。
3.1.Xtrabackup原理
3.1.1.全备份|恢复原理
- 备份原理

1.备份开始前开启一个后台检测进程,实时检测mysql redo的变化写入到xtrabackup_logfile文件
2.拷贝innodb engine涉及的ibd ibdata1数据文件(拷贝的单位是page,而不是文件)
3.数据库级只读锁(FLUSH TABLES WITH READ LOCK)
4.拷贝除innodb enging之外的数据文件(多数指MyIASM的表)
5.获取当前数据库binary log position
6.释放数据库级只读锁(释放全局级锁)
7.等待redo变化写入xtrabackup_logfile并关闭Xtrbackup进程
建议: xtrabackup工具最好只备份innodb engine的表,因为这样,就会节省掉步骤四的物理copy时间,从而大大减少,数据库锁的时间.
- 恢复原理

1.Xtrabackup内嵌的innodb实例,回放xtrabackup_log日志至备份集
2.将提交的事务信息变更应用到innodb数据/表空间,同时回滚未提交的事务(这一过程类似innodb的实例恢复)。
3.根据配置文件(my.cnf)恢复数据文件、日志文件到指定路径
3.1.2.增量备份|恢复原理
- 备份原理
"增量"备份的过程主要是通过拷贝innodb中有变更的"页"(这些变更的数据页指的是"页"的LSN大于xtrabackup_checkpoints中给定的LSN)。增量备份是基于全备的,第一次增备的数据必须要基于上一次的全备,之后的每次增备都是基于上一次的增备,最终达到一致性的增备。
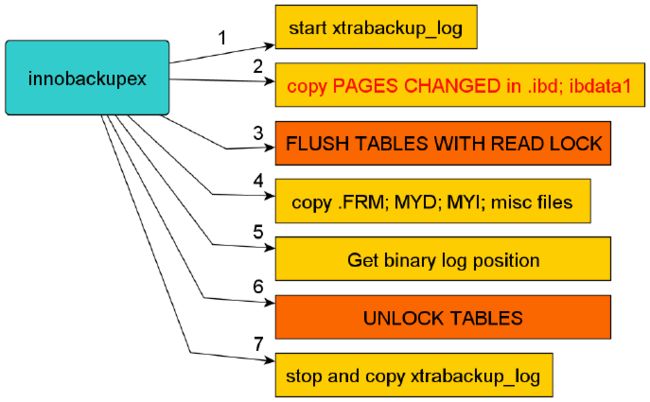
1.备份开始前开启一个后台检测进程,实时检测mysql redo的变化写入到xtrabackup_logfile文件
2.拷贝上次全备份以后LSN变化的数据
3.数据库级只读锁(FLUSH TABLES WITH READ LOCK)
4.拷贝除innodb enging之外的数据文件(多数指MyIASM的表)
5.获取当前数据库binary log position
6.释放数据库级只读锁(释放全局级锁)
7.等待redo变化写入xtrabackup_logfile并关闭Xtrbackup进程
注意:innobackupex增量备份过程中的"增量"处理,其实主要是相对innodb而言,对myisam和其他存储引擎而言,它仍然是全拷贝(全备份)
- 恢复原理


1.全备份以只"重做"的方式回放xtrabackup_log日志至备份集(为后面增量数据的合并做基础)
2.依次合并增量备份至完整备份集(此时的merge可以commit、rollback)
3.Xtrabackup内嵌的innodb实例,回放xtrabackup_log日志至备份集
4.将提交的事务信息变更应用到innodb数据/表空间,同时回滚未提交的事务(这一过程类似innodb的实例恢复)。
5.根据配置文件(my.cnf)恢复数据文件、日志文件到指定路径
和全备恢复类似,也需要两步,一是数据文件的恢复,如图1,这里的数据来源由3部分组成:全备份,增量备份和xtrabackup log。图2是对未提交事务的回滚
- 如何选择备份集

3.2.文件介绍
backup-my.cnf
备份集的配置选项文件xtrabackup_binlog_info
当前正在使用的二进制日志文件及至备份的位置。xtrabackup_binlog_pos_innodb
包含二进制日志文件及用于InnoDB或XtraDB表的二进制日志文件的当前positionxtrabackup_checkpoints
备份类型(如完全或增量)、备份状态(如是否已经为prepared状态)和LSN(日志序列号)范围信息;xtrabackup_info
备份集概要xtrabackup_logfile
备份过程中记录redo变化的日志文件
3.3.相关参数
--defaults-file=# 该选项传递给xtrabackup子进程,从指定文件读取缺省选项
--apply-log 从备份恢复
--redo-only 选项用于准备全库备份和合并处最有一个备份外的所有增量备份。该选项强制跳过rollback阶段,只进行redo。这是有必要使用的,如果备份后,要使用增量改变的。
--copy-back 从备份目录拷贝数据和索引文件到datadir目录
--move-back 移动之前的所有备份从一个备份目录到他们的原始位置
--incremental 建立一个增量备份,传递给xtrabackup的子进程。该参数可以和参数--incremental-lsn or --incremental-basedir配合使用。
--incremental-basedir=DIRECTORY 指定一个包换全库备份的目录作为增量备份的基础数据库。
--incremental-dir=DIRECTORY 指定增量备份与全库备份合并去建立一个新的全备份的目录。
--remote-host=HOSTNAME 备份到远程主机上,使用ssh
--stream=[tar|cpio(notimplemented)] 指定备份标准输出格式
--tmpdir=DIRECTORY 默认与tmpdir相同。使用—remote-host或—stream参数后,传输日志文件将存放在临时目录下
--use-memory=MB 传递给xtrabackup子进程。恢复使用内存大小
--parallel=NUMBER-OF-THREADS 选项传递给xtrabackup子进程,指定数据传输线程总数。默认为1
--compress[=LEVEL] 选项传递给xtrabackup子进程。压缩级别在0-9.1快速压缩,9最佳压缩,0不压缩。默认为1.
--compress-threads[=NUMBER] 压缩时的并行线程总数,一般来说要和--parallel保持一致
--throttle=iOS 选项传递给xtrabackup子进程,限制IO线程数量
--sleep=MS 选项传递给xtrabackup子进程。每拷贝1MB数据暂停多少MS时间
--include=REGEXP 选项传递给xtrabackup子进程。使用正则进行匹配
--databases=LIST 指定备份数据库
--tables-file=FILE 指定需要备份的表
--uncompress 选项传递给xtrabackup子进程。对压缩过的InnoDB数据文件不进行压缩
--export 仅使用于prepare选项。选项传递给xtrabackup子进程。
--slave-info 备份复制从服务端,主从信息记录在ibbackup_slave_info文件中
--no-timestamp 不在备份根目录下创建以当前时间戳为名称的新的备份目录
--ibbackup=IBBACKUP-BINARYibbackup 二进制路径
--no-lock 禁止表级锁。全部是InnoDB引擎表和不关系二进制日志位置下使用
--scpopt=SCP-OPTIONS 指定scp参数
3.4.最佳实践
xtrabackup官方网站:https://www.percona.com/
xtrabackup下载站点:https://www.percona.com/downloads/XtraBackup/LATEST/
3.4.1.完全备份恢复
- 备份数据库
innobackupex --defaults-file=/etc/mysql/my10059.cnf -S /var/wd/db10059/my10059.sock -p 123 --use-memory=256M --no-timestamp /data1/mysqlbackup/xtra_full_135156_10059
- 恢复数据库
innobackupex --defaults-file=/data1/mysqlbackup/xtra_full_135156_10059/backup-my.cnf --apply-log /data1/mysqlbackup/xtra_full_135156_10059
innobackupex --defaults-file=/etc/mysql/my10059.cnf --move-back /data1/mysqlbackup/xtra_full_135156_10059
chown -R mysql:mysql /var/wd/db10059/
3.4.2.增量备份恢复
- 备份数据库
- 全备份
innobackupex --defaults-file=/etc/my.cnf -u root -S /data1/db3306/my3306.sock -p123 --no-timestamp /data1/xtra_full_168160_3306
- 增量备份
innobackupex --defaults-file=/etc/my.cnf -S /data1/db3306/my3306.sock -p 123 --no-timestamp --incremental /data1/xtra_incr_168160_3306 --incremental-basedir=/data1/xtra_full_168160_3306
- 恢复数据库
- 全备份只"重做"回放xtrabackup log
innobackupex --apply-log --redo-only /data1/xtra_full_168160_3306
- merge增量备份集(如果有多个,顺序merge)
innobackupex --apply-log --redo-only xtra_full_168160_3306 --incremental-dir=xtra_incr_168160_3306
- 完整的回放xtrabackup log
innobackupex --defaults-file=/data1/xtra_full_168160_3306/backup-my.cnf --apply-log /data1/xtra_incr_168160_3306
innobackupex --defaults-file=/etc/my.cnf --move-back xtra_full_168160_3306
- 通过binlog恢复误删除数据
mysqlbinlog --start-position=423234035 16703402-bin.000561 | mysql -S /data1/db3402/my3402.sock -pxxx
mysqlbinlog 16703402-bin.000562 16703402-bin.000563 16703402-bin.000564 16703402-bin.000565 16703402-bin.000566 | mysql -S /data1/db3402/my3402.sock -pxxx
mysqlbinlog 16703402-bin.000567 16703402-bin.000568 16703402-bin.000569 16703402-bin.000570 16703402-bin.000571 16703402-bin.000572 | mysql -S /data1/db3402/my3402.sock -pxxx
mysqlbinlog 16703402-bin.000573 16703402-bin.000574 16703402-bin.000575 16703402-bin.000576 16703402-bin.000577 | mysql -S /data1/db3402/my3402.sock -pxxx
mysqlbinlog --stop-position=657188280 16703402-bin.000578 | mysql -S /data1/db3402/my3402.sock -pxxxx
3.4.3.备份新特性
- "流"方式压缩备份
Xtrabackup对备份的数据文件支持“流”功能,即可以将备份的数据通过STDOUT传输给tar程序进行归档,而不是默认的直接保存至某备份目录中。要使用此功能,仅需要使用--stream选项即可。
innobackupex --defaults-file=/etc/mysql/my10059.cnf -p 123 --use-memory=256M --no-timestamp --stream=tar /data1/mysqlbackup/xtra_full_gzip135156_10059 | gzip > /data1/mysqlbackup/xtra_full_gzip135156_10059.tar.gz
- "innodb page"方式压缩备份
innobackupex --defaults-file=/etc/mysql/my10059.cnf -S /var/wd/db10059/my10059.sock -p 123 --compress --use-memory=256M --no-timestamp /data1/mysqlbackup/xtra_full_135156_10059
- 部分备份
innobackupex --defaults-file=/etc/mysql/my10059.cnf -S /var/wd/db10059/my10059.sock -p 123 --databases='sys performance_schema mysql custom_db' --use-memory=256M --no-timestamp /data1/mysqlbackup/xtra_full_135156_10059
- 并行备份
innobackupex --defaults-file=/etc/mysql/my10059.cnf -S /var/wd/db10059/my10059.sock -p 123 --parallel=6 --use-memory=256M --no-timestamp /data1/mysqlbackup/xtra_full_135156_10059
4.mydumper
mydumper(&myloader)是用于对MySQL数据库进行多线程备份和恢复的开源 (GNU GPLv3)工具。开发人员主要来自MySQL、Facebook和SkySQL公司,目前由Percona公司开发和维护,是 Percona Remote DBA 项目的重要组成部分,包含在Percona XtraDB Cluster中。mydumper的第一版0.1发布于2010.3.26,最新版本0.9.1发布于2015.11.06。
Mydumper主要特性:
- 开源 (GNU GPLv3)
- 轻量级C语言写的
- 快速的文件压缩
- 支持导出binlog
- 执行速度比mysqldump快10倍
- 多线程恢复(适用于0.2.1以上版本)
- 事务性和非事务性表一致的快照(适用于0.2.2以上版本)
- 以守护进程的工作方式,定时快照和连续二进制日志(适用于0.5.0以上版本)
4.1.mydumper原理
mydumper作为一个实用工具,能够良好支持多线程工作,可以并行的多线程的从表中读入数据并同时写到不同的文件里,这使得它在处理速度方面快于传统的mysqldump N倍。
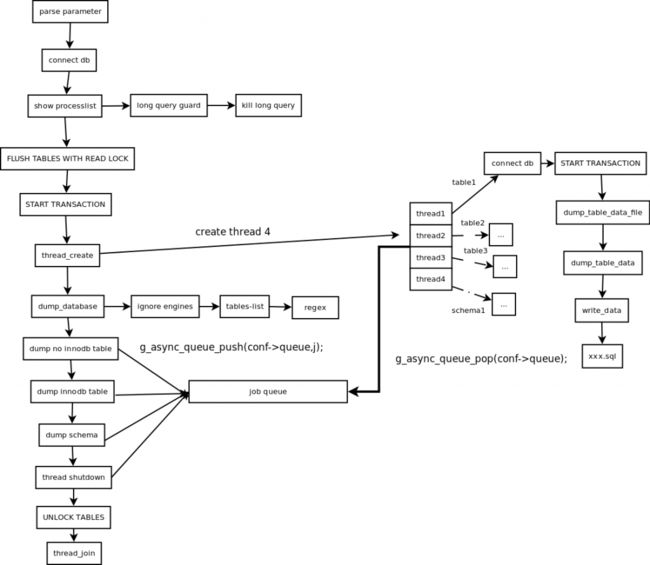
原理分析
mydumper的工作过程:
- 主线程对备份实例加读锁,阻塞写操作以建立一致性数据备份快照(FLUSH TABLES WITH READ LOCK)
- 读取当前时间点的二进制日志文件名和日志写入的位置并记录在metadata文件中,以供即使点恢复使用
- 创建工作线程,初始化备份任务队列,并向队列中推送数据库元数据(schema)、非InnoDB表和InnoDB表的备份任务;
- 工作线程负责将备份任务队列中的任务按顺序取出并完成备份(dump线程数可以指定,默认是4)
- 分别建立与备份实例连接,将session的事务级别设置为repeatable-read,用于实现可重复读;
- 在主线程仍持有全局读锁时开启事务进行快照读,这样保证了读到的一致性数据与主线程相同,实现了备份数据的一致性;
- 按序从备份任务队列中取出备份任务,工作线程先进行MyISAM等非InnoDB表备份
- 非事物引擎备份完后,主线程释放全局只读锁(UNLOCK TABLES)
- 完成InnoDB表备份,事务结束,关闭链接
表数据拆分方式如下所述:
- mydumper优先选择主键索引的第一列作为chunk划分字段
- 若不存在主键索引,则选择第一个唯一索引作为划分依据
- 若还不存在,则选择区分度(Cardinality)最高的任意索引。
- 如果还是无法满足,则只能进行表级的并行备份
范围拆分方式:
- 在确定了chunk划分字段后,先获取该字段的最大和最小值
- 再通过执行“explain select field from db.table”来估计该表的记录数
- 最后根据所设的每个任务(文件)记录数来将该表划分为多个chunk。
备份所生成的文件
目录中包含一个metadata文件:
- 记录了备份数据库在备份时间点的二进制日志文件名,日志的写入位置
- 如果是在从库进行备份,还会记录备份时同步至主库的二进制日志文件及写入位置
每个表有两个备份文件:
- database.table-schema.sql 表结构文件
- database.table.sql 表数据文件
- 如果对表文件分片,将生成多个备份数据文件,可以指定行数或指定大小分片
注意:mydumper导出时不写binlog,复制环境中需要注意。
4.2.相关参数
- mydumper参数介绍:
-B, --database 需要备份的库
-T, --tables-list 需要备份的表,用,分隔
-o, --outputdir 输出目录
-s, --statement-size Attempted size of INSERT statement in bytes, default 1000000
-r, --rows 试图分裂成很多行块表
-c, --compress 压缩输出文件
-e, --build-empty-files 即使表没有数据,还是产生一个空文件
-x, --regex 支持正则表达式
-i, --ignore-engines 忽略的存储引擎,用,分隔
-m, --no-schemas 不导出表结构
-k, --no-locks 不执行临时共享读锁 警告:这将导致不一致的备份
-l, --long-query-guard 长查询,默认60s
--kill-long-queries kill掉长时间执行的查询(instead of aborting)
-D, --daemon 启用守护进程模式
-I, --snapshot-interval dump快照间隔时间,默认60s,需要在daemon模式下
-L, --logfile 日志文件
-h, --host
-u, --user
-p, --password
-P, --port
-S, --socket
-t, --threads 使用的线程数,默认4
-C, --compress-protocol 在mysql连接上使用压缩
-V, --version
-v, --verbose 更多输出, 0 = silent, 1 = errors, 2 = warnings, 3 = info, default 2
- myloader参数介绍:
-d, --directory 导入备份目录
-q, --queries-per-transaction 每次执行的查询数量, 默认1000
-o, --overwrite-tables 如果表存在删除表
-B, --database 需要还原的库
-e, --enable-binlog 启用二进制恢复数据
-h, --host
-u, --user
-p, --password
-P, --port
-S, --socket
-t, --threads 使用的线程数量,默认4
-C, --compress-protocol 连接上使用压缩
-V, --version
-v, --verbose 更多输出, 0 = silent, 1 = errors, 2 = warnings, 3 = info, default 2
4.3.最佳实践
- 安装mydumper
软件下载:https://launchpad.net/mydumper/0.9/0.9.1/+download/mydumper-0.9.1.tar.gz
yum install gcc gcc-c++ make cmake glib2-devel zlib-devel pcre-devel openssl-devel mysql-devel
cd mydumper-0.9.1
cmake .
make
cp -p mydumper /usr/local/bin
cp -p myloader /usr/local/bin
ldd mydumper
- 备份数据库
mydumper -S /data1/db3307/my3307.sock -u root --tz-utc --threads 32 -o /data1/mysqlbackup/full_3307_mydumper
- 恢复数据库
myloader -S /data1/db3307/my3307.sock -u root --threads 32 -o -d /data1/mysqlbackup/full_3307_mydumper
- 常见错误
** (mydumper:142452): WARNING **: Broken table detected, please review: wanda.view_s06_ffan_mem_reg_cnt_minute
** (mydumper:142452): WARNING **: Broken table detected, please review: wanda.view_s06_ffan_wifi_mobile_to_plaza_uniq_real_time
** (mydumper:142452): CRITICAL **: Could not read data from imc.MSG_BLACK_BATCH: Table definition has changed, please retry transaction
** (mydumper:142452): CRITICAL **: Error dumping table (scm_db.gerritapp_plan_jenkins) data: Table 'scm_db.gerritapp_plan_jenkins' doesn't exist
** (mydumper:142452): CRITICAL **: Error dumping schemas (wanda.view_s06_ffan_mem_reg_cnt_hour): SELECT command denied to user ''@'%' for column 'plaza_id' in table 's06_ffan_mem_reg_real_time'
** (mydumper:142452): CRITICAL **: Error dumping schemas (wanda.view_s06_ffan_mem_reg_info_uniq_real_time): SELECT command denied to user ''@'%' for column 'mobile' in table 's06_ffan_mem_reg_info_real_time'
** (myloader:1408769): CRITICAL **: Error restoring invoice.INVOICE_STOREINFO from file invoice.INVOICE_STOREINFO-schema.sql: Invalid default value for 'PAUSE_TIME'
** (myloader:1408769): CRITICAL **: Error restoring invoice.INVOICE_TASK from file invoice.INVOICE_TASK-schema.sql: Invalid default value for 'INVOICE_START_TIME'
** (myloader:1408769): CRITICAL **: Error restoring pubsub.logs from file pubsub.logs-schema.sql: Invalid default value for 'operatorTime'
出现问题的View
CREATE ALGORITHM=UNDEFINED DEFINER=`mycat`@`10.%` SQL SECURITY DEFINER VIEW `view_s06_ffan_mem_reg_cnt_hour` AS select `mycat`.`s06_ffan_mem_reg_real_time`.`plaza_id` AS `plaza_id`,date_format(`mycat`.`s06_ffan_mem_reg_real_time`.`create_time`,'%Y-%m-%d %H') AS `reg_time`,count(1) AS `total`,count((case when (`mycat`.`s06_ffan_mem_reg_real_time`.`channel` = 'app') then 1 end)) AS `app`,count((case when (`mycat`.`s06_ffan_mem_reg_real_time`.`channel` = 'web') then 1 end)) AS `web`,count((case when (`mycat`.`s06_ffan_mem_reg_real_time`.`channel` = 'html5') then 1 end)) AS `html5`,count((case when (`mycat`.`s06_ffan_mem_reg_real_time`.`channel` = 'wifi') then 1 end)) AS `wifi`,count((case when (`mycat`.`s06_ffan_mem_reg_real_time`.`channel` = 'card') then 1 end)) AS `card`,count((case when (`mycat`.`s06_ffan_mem_reg_real_time`.`channel` = 'sms') then 1 end)) AS `sms`,count((case when (`mycat`.`s06_ffan_mem_reg_real_time`.`channel` = 'thrid') then 1 end)) AS `thrid`,count((case when (`mycat`.`s06_ffan_mem_reg_real_time`.`channel` = 'offline') then 1 end)) AS `offline` from `s06_ffan_mem_reg_real_time` where (`mycat`.`s06_ffan_mem_reg_real_time`.`create_time` >= '2015-12-08') group by `mycat`.`s06_ffan_mem_reg_real_time`.`plaza_id`,`reg_time`;
- 案例分享
1.8T数据库服务器,32核,希捷pci-E SSD卡
导出时间25分钟(意不意外、惊不惊喜、刺不刺激)
导入时间5小时15分钟
扫描下方二维码关注本人微信号!欢迎大家交流学习!
