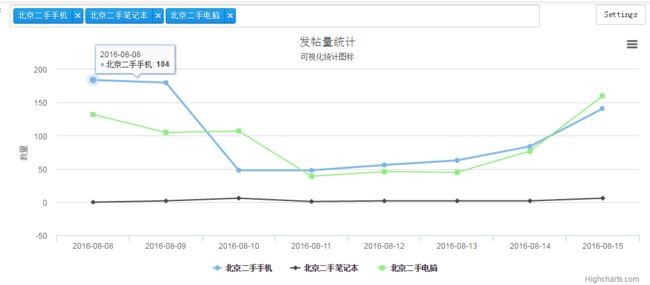
本次主要目的是将数据分析展示出来,分析的数据是['北京二手手机', '北京二手笔记本', '北京二手电脑']三项在连续七天内的发帖量。
成果:
代码:
这里有几个步骤
-
处理数据
1.自己的数据有些问题,首先这个cate类自己是['北京二手','北京二手手机','北京二手手机详情'],这样的话在以后find()的时候会有困难,所以就净化了数据,提取索引为1的替换掉整个list
# 将cate中的数据切片出去,原先的数据有3个,取第2个,来代替所有的
for i in item_info.find({}, {'cate': {'$slice': [2,1]}}):
cate = i['cate']
item_info.update_one({'_id':i['_id']}, {'$set': {'cate': cate}})
# 注意这个update更改数据库的操作
# 个人觉得这个'_id': i['_id']很巧妙地把所有的数据都选中了
2.日期有点问题,我的是[month-day],但是如果不是[year-month-day]格式,在之后用date函数的时候会多些处理,所以就通过更改数据库变成标配:
# 日期原先是[month, day]格式,现在转为[年,月,日]格式,便于之后的套路
for i in item_info.find({}, {'time': 1}):
time = '2016-'+ i['time']
item_info.update_one({'_id':i['_id']}, {'$set': {'time': time}})
期间发现少量数据没有日期,就删除掉了,如下:
for i in item_info.find({},{'time': 1}):
if len(i['time']) <= 1:
item_info.delete_one(i)
其实觉得这个操作有风险,后来想了想,其实无所谓啊,如果日期没有那就选不到啊,删除没什么用
-
构造生成器函数
1.日期输出的生成器
# 函数大概的意思就是输出str日期(计算机只知道它是字符串),经过转化输出日期(依旧是字符串)
# 但是不同的是,输入的str经过data一系列的处理,计算机知道这是日期了
# 对于之后的日期操作就方便多了
def get_all_dates(date1, date2):
the_date = date(int(date1.split('-')[0]), int(date1.split('-')[1]), int(date1.split('-')[2]))
end_date = date(int(date2.split('-')[0]), int(date2.split('-')[1]), int(date2.split('-')[2]))
days = timedelta(days=1)
while the_date <= end_date:
# strftime是格式化输出函数
yield (the_date.strftime('%Y-%m-%d'))
the_date = the_date + days
2.构造指定商品的生成器
def get_data_within(date1, date2, cates):
for cate in cates:
cate_day_posts = []
for date in get_all_dates(date1, date2):
a = list(item_info.find({'time': date, 'cate': cate}))
each_day_post = len(a)
# 统计所有cate类的特定日期下的发帖数量
cate_day_posts.append(each_day_post)
# 这里的data组装为了highcharts的使用
data = {
'name': cate,
'data': cate_day_posts,
'type': 'line'
}
yield data
3.输出数据
options = {
'chart': {'zoomType': 'xy'},
'title': {'text': '发帖量统计'},
'subtitle': {'text': '可视化统计图标'},
# 这里列表是坐标横轴的名称,就用生成器给个日期轴
'xAxis': {'categories': [i for i in get_all_dates('2016-08-08', '2016-08-15')]},
'yAxis': {'title': {'text': '数量'}}
}
series = [i for i in get_data_within('2016-08-08', '2016-08-15', ['北京二手手机','北京二手笔记本','北京二手电脑'])]
charts.plot(series, options=options, show='inline')
发现生成器真是个好东西!
新技能GET:
1.collection.find({}, {})
第一个{}中填写匹配的项目如{’name‘: 'long'},然后通过迭代就出现所有匹配的document,第二个{}是填写需要显示的项目,通过布尔值来告诉软件是显示还是不显示,0代表不显示,1代表显示,缺省默认是1,如:
item_info.find({'cate': '北京二手笔记本'},{'_id': 0, 'url': 0, 'state': 0, 'time': 0}),
这些操作不会对数据库造成影响。
2.from datetime import date
中,date(2016,2,3)会生成2016.2.3,这个是系统能识别的时间
3.切片使用
数据库item_info有个元素是'cate': ['0','1','2','3'],只是想显示'2'怎么办呢?
item_info.find({},{'cate': {$slice: [index1,index2]}})
这样,index1表示从哪个索引开始,index2表示从开始的地方选取几个,包括开始的元素。如选取'2',就是[2,1],如果选取'1','2',就是[1,2]
这种形式的切片是很多数据库用的,跟Python切片还不大一样
天坑:
本次没有,基本就是数据库格式的不对劲而引起的,以后注意就行
总结:
还是套路,
唯一要掌握并多多练习的东西就是:数据都有了,怎么去构造自己想要的信息?