层级时间轮
3.4.4 定时器Timer
那么Kafka的Timer定时器是如何存储DelayedOperation,又是如何在有任务超时的时候能准确地轮询出来。在Java中有多种方案可以做到任务的延迟执行,比如java.util.Timer和TimerTask的调度,或者DelayedQueue和实现Delayed接口的线程。但这些对于Kafka这种动辄成千上万个请求的分布式系统而言都过于重量级,所以Kafka的Timer专门设计了TimingWheel这个数据结构来存储大量的处理请求,不过它的底层还是基于DelayedQueue实现的。
被放到延迟队列的每个元素必须实现Delayed接口,本来可以直接将DelayedOperation放入队列中(任务失效的时候是一个一个弹出),不过因为DelayedOperation数量级太大了,可以将多个DelayedOperation组成一个TimerTaskList链表(在同一个列表中的所有任务的失效时间都很相近,但不一定都相等),以TimerTaskList作为队列的元素,所以失效时间会被设置到TimerTaskList上,当失效的时候,整个列表中的所有任务都会一起失效。
1. 定时任务链表和条目
2. TimingWheel时间轮
Purgatory将任务添加到Timer定时器,并且会在Reaper线程中调用advanceClock不断地移动内部的时钟,使得超时的任务可以被取出来执行。任务加入到TimingWheel中需要首先被包装成TimerTaskEntry,然后TimingWheel会根据TimerTaskEntry的失效时间加入到某个TimerTaskList中(TimingWheel的某个bucket)。当TimerTaskList因为超时被轮询出来并不一定代表里面所有的TimerTaskEntry一定就超时,所以对于没有超时的TimerTaskEntry需要重新加入到TimingWheel新的TimerTaskList中,对于超时的TimerTaskEntry则立即执行任务。不过timingWheel.add添加任务时并不需要先判断有没有超时然后再做决定,而是不管三七二十一,先尝试加入TimerTaskEntry,如果添加成功,那很好;如果没有添加成功,说明这个任务要么已经被取消了,要么超时了。
添加不成功有两种情况,1)被其他线程完成后任务会被取消,这样保证了只有最先完成的那个线程只会调用一次完成的方法,其他线程就不再需要执行这个任务了。2)任务超时了,但还没有被其他线程完成即还没有被取消,当前线程就应该立即执行任务。
class Timer(taskExecutor:ExecutorService, tickMs:Long=1,wheelSize:Int=20,
startMs: Long = System.currentTimeMillis) {
val delayQueue = new DelayQueue[TimerTaskList]() //延迟队列,按照失效时间排序
val taskCounter = new AtomicInteger(0) //内存级别的原子共享变量,所有时间轮同一个计数器
val timingWheel=new TimingWheel(tickMs,wheelSize,startMs,taskCounter,delayQueue)
def add(timerTask: TimerTask) = { //1.DelayedOperation是一个TimerTask
addTimerTaskEntry(new TimerTaskEntry(timerTask)) //2.被包装成定时任务条目
}
val reinsert=(entry:TimerTaskEntry) => addTimerTaskEntry(entry)//高阶函数
//add和reinsert都会将TimerTaskEntry加入到时间轮,后者使用已有的TimerTaskEntry
def addTimerTaskEntry(timerTaskEntry: TimerTaskEntry) {
val addSuccess = timingWheel.add(timerTaskEntry) //3.添加到时间轮中
if (!addSuccess) { //添加不成功,要么被取消,要么超时了
if (!timerTaskEntry.cancelled) //还没有被取消,那就是超时了
taskExecutor.submit(timerTaskEntry.timerTask) //执行条目里的定时任务
}
}
def advanceClock(timeoutMs: Long): Boolean = { //timeout是轮询的最长等待时间
var bucket=delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS)//没有到超时不会被轮询出
if (bucket != null) { //从延迟队列轮询出存储的TimerTaskList
while (bucket != null) { //一次可能会轮询出多个元素,当并不一定是延迟队列所有元素
timingWheel.advanceClock(bucket.getExpiration())
bucket.flush(reinsert) //重新插入,函数的entry参数只有真正调用flush方法才能知道
bucket=delayQueue.poll() //立即再轮询一次(不等待),直到poll出来没有东西了才停止
}
}
}
}
Timer使用TimingWheel时间轮来管理延迟的等待超时的请求,TimingWheel时间轮是一个存储定时任务的数据结构:tickMs表示指针每隔1ms tick一次,wheelSize=20表示走完一圈要tick 20次,所以走完一圈总共要花费201ms=20ms,如果tickMs=1000ms,wheelSize=60,就和时钟里秒针的滴答完全一样了。taskCounter表示请求数量,如果请求完成则计数器的值会减少,delayQueue是延迟队列用来存储定时任务。可以把Timer看做是*定时器线程即模拟秒针每秒钟走一次这个动作,而TimingWheel则负责在秒针tick一次之后将超时的任务完成掉。图3-73举例现实世界的时钟和闹钟(指定时间点)/计时器(多长时间后),假设设置了一个计时器任务要在30秒后离开电脑休息一下,当启动计时器时,时间一秒钟一秒钟地流逝,要执行的任务也渐渐临近,剩余的时间越来越少,当计时器停止时,时间已经走了30秒了,之前设置的任务就应该被执行。TimingWheel的工作原理和计时器是类似的,它允许在不同时刻加入不同计时器,而且对同一个时间点,也允许多个计时器同时触发执行,比如有多个任务都要在30秒后同时执行。

图3-73 现实世界的时钟/计时器示例
private[timer] class TimingWheel(tickMs:Long,wheelSize:Int,startMs:Long,
taskCounter: AtomicInteger, queue: DelayQueue[TimerTaskList]) {
val interval = tickMs * wheelSize
val buckets = Array.tabulate[TimerTaskList](wheelSize) {
_ => new TimerTaskList(taskCounter) } //每个List共享taskCount计数器
var currentTime = startMs - (startMs % tickMs)
@volatile var overflowWheel: TimingWheel = null
def addOverflowWheel(): Unit = {
if (overflowWheel == null) { //创建父级别的时间轮
overflowWheel = new TimingWheel(
tickMs = interval, //低级别的整个范围作为父级别一个tick
wheelSize = wheelSize, /cket的数量不变
startMs = currentTime, //当前时间通过advanceClock会更新
taskCounter = taskCounter, queue //全局唯一的计数器和延迟队列
)
}
}
def add(timerTaskEntry: TimerTaskEntry): Boolean = {
val expiration = timerTaskEntry.expirationMs
if (timerTaskEntry.cancelled) { //被其他线程取消了(执行任务时会取消)
false
} else if (expiration < currentTime + tickMs) { //已经超时了
false
} else if (expiration < currentTime + interval) {
val virtualId = expiration / tickMs
val bucket = buckets((virtualId % wheelSize.toLong).toInt)
bucket.add(timerTaskEntry) //把任务根据失效时间点放到对应的bucket中
//设置bucket的失效时间点,然后把bucket加入队列中
if (bucket.setExpiration(virtualId * tickMs)) queue.offer(bucket)
true
} else {
if (overflowWheel == null) addOverflowWheel()
overflowWheel.add(timerTaskEntry)
}
}
def advanceClock(timeMs: Long): Unit = {
if (timeMs >= currentTime + tickMs) {
currentTime = timeMs - (timeMs % tickMs)
if (overflowWheel != null)
overflowWheel.advanceClock(currentTime)
}
}
}
举例外部的Purgatory添加任务到定时器中,然后通过Reaper线程的advanceClock移动时钟的调用顺序,假设当前时间currentTime是0s,时间轮的tickMs=1000ms=1s,时间轮大小=8,整个时间轮的范围interval=1s*8=8s,Reaper线程循环时轮询一次队列最长timeoutMs=200ms,添加的四个任务的超时时间分别是[A=0s,B=1s,C=1s,D=3s]。添加任务时,任务A=0s
在800ms时间点调用轮询时,timeoutMs=200ms,这时候可以终于把bucket1轮询出来(因为800ms时间点+200ms时间间隔=1000ms=1s,而刚好队列中存在延迟时间=1s的bucket),这个bucket1中有两个任务B/C,它们的失效时间都是1s,而且bucket级别的expiration=1s(加入任务时同时确定bucket的失效时间),首先通过advanceClock更新currentTime=1s。
bucket.flush会尝试将任务B/C重新加入队列中,由于此时currentTime已经被更新为1s,B/C的超时时间=1s

图3-74 Timer和TimingWheel的调用示例(没有二级时间轮)
失效时间和bucket选择
任务的失效时间是一个确定的时间点,所以不管当前时间是什么,即使失效时间相同的两个任务在不同时间点加入队列,它们也会被放入同一个bucket中。当然根据任务的失效时间选择不同的bucket还跟tickMs以及时间轮的大小有关,时间轮的expiration范围expiration=[currentTime+tickMs,currentTime+interval)。图3-75中示例了在相同时间轮大小下三种不同的tickMs,当tickMs=1时,每个bucket中任务的失效时间只有一个值,当tickMs=2时有两种可能,当tickMs=8时就有8种可能,比如失效时间在120-127范围内的任务都会被分配到bucket7中。即使是相同失效时间如果tickMs不同也会被放入不同的bucket,比如任务失效时间=103在tickMs=1时分配到bucket7,在tickMs=2时分配到bucket3。

图3-75 相同时间轮,不同tickMs
由tickMs和时间轮的大小决定了这个时间轮所有任务失效时间的一个范围,如果超过这个范围,则不允许加入,图3-76中当前时间等于100时,时间轮的范围=[101..107],当前时间等于101时,范围=[102..108]以此类推。当前时间所在的bucket实际上是没有任务的,因为任务的失效时间如果和当前时间相等说明任务已经失效了,不应该放入队列中。

图3-76 时钟tick影响了时间轮的取值范围
任务的失效时间和当前时间相等指的是完全相等,比如tickMs=1s,时间轮大小=60,当前时间等于12:00:00,某个任务的超时时间是12:01:00。时钟tick时每隔一秒走动一次:[12:00:01,..12:00:59,12:01:00],在12:01:00这一刻任务就超时了,不是12:01:00到下一次tick=12:01:01的一半12:01:00.500,也不是过了12:01:00后的下一次tick=12:01:01才超时,当刚刚好进入12:01:00.000时任务就超时了!比如你定了一个12:01:00的任务运行,你当然希望在那个时间点分毫不差地精准地执行任务,多一秒少一秒都不行!
层级时间轮
只有一个时间轮虽然在时间移动时可以重用旧的bucket来保存失效时间更往后的任务,但是由于时间轮所允许的范围就那么大,超过这个范围的失效时间就无法很好地存储了。还是以tickMs=1s,时间轮大小=60为例,如果当前时间是12:00:00,你无法设置12:01:01的任务,更谈不上12:02:00以及失效时间更加往后的任务了。在《嵌入式系统的实时概念》第十一章提到使用一个外部的event flow buffer来暂时存储超过interval的事件,不过更好的方式是使用层级的时间轮。层级时间轮中假设时间轮大小都不变,但是tickMs则是不断递增,假设Level0的tickMs=1s,则Level1的tickMs=1s*60=60s,Level2的tickMs=60s*60=3600s以此类推。每一层的tickMs表示的是在当前时间轮中移动一格的粒度/单位,Level0=1s,Level1=60s,Level2=3600s。可以用钟表的秒钟,分针,时针的移动来理解这三个时间轮:秒针走动一格需要花费一秒,分针走动一格花费60秒,时针走动一格花费3600秒。而且更高层级的tickMs等于低一层的整个时间轮范围,比如Level0的interval=1s*60=60s,刚好作为Level1的tickMs,Level1的interval=60s*60=3600s,也作为Level2的tickMs。也就是说Level1的一格等于Level0走完一圈,Level2的一格等于Level1走完一圈。
那么为什么tickMs的单位不同,假设有几个任务的失效时间分别是[20s,60s,70s,120s,3600s],如果所有时间轮的tickMs都是1s,总共需要3600/60=60个时间轮!既然每个时间轮的tickMs都相等,跟直接用一个大小等于3600的时间轮是没有任何区别的。而如果使用层级时间轮,总共只需要3个时间轮,20s在Level0的第20个单元格,60s和70s在Level1的第一个单元格内,120s在Level1的第二个单元格上,3600在Level2的第一个单元格上(思考下为什么要把60s这种刚好等于当前时间轮范围的任务放在下一个时间轮,而不是当前时间轮上)。
confluent有篇博客详细介绍了时间轮的改进和性能对比,图3-77中当前指针指向任务①所在的bucket,则任务①已经超时了,当发生一次tick之后,任务①已经彻底从队列中移除了,tick一次之后当前指针指向了任务②所在的bucket,因为任务②也已经超时了,也就是说tick指针指向哪里,那里就已经超时了,在当前指针所指向的bucket里的任务都应该被取出来执行。

图3-77 时间轮tick到当前bucket,这个bucket的任务都超时
摘自:http://www.confluent.io/blog/apache-kafka-purgatory-hierarchical-timing-wheels
图3-78有两个时间轮分别是Level0和Level1,在Time0时加入了⑦⑧⑨三个任务,任务⑦在Level0的7-8之间,任务⑧⑨在Level1的8-16之间。这里你可能会认为⑧和⑨应该紧接着Level0的7-8的下一个应该放在Level1的0-8,这样才叫做无缝衔接嘛。不过如果把⑧⑨放在Level1的0-8之间,1)本身就不符合取值范围,因为⑧⑨在0-8之外,而放在8-16之间正好满足⑧⑨的取值范围。2)Level1当前指向了0-8表示这个区间的所有任务都已经超时,如果⑧⑨放在这里,那么它们就都会超时,而此时连任务⑦都还没超时,⑧⑨怎么可能超时呢。3)Level1的0-8这一格子对应了Level0的所有格子,所以Level1指向0-8表示任务在0-8之间的正在超时,不过具体0-8之间的任务则还是以Level0为准,这就好比在Time8时,Level1指向了8-16,表示8-16之间的任务正在超时,但是具体8-16之间的任务也是以Level0为准。
在Time0之后发生一次Tick后,Level0的指针指向1-2,而Level2的指针没有变化,而Level0的0消失,1添加了9。图3-78中当前时间=Time7时,Level0的指针指向了7-8之间,Level2的指针还是没有变化,任务⑦超时。再次发生tick之后,指针移动到8-9(这里已经不是0-1了),这时候Level1的指针终于移动了一格从原先的0-8移动到8-16(想象下秒针走了一圈60s,分针才终于挪动了一格)。而Level1原先在8-16之间存在任务⑧⑨,那么是不是说这两个任务同时失效了呢?实际上外界真实时钟走动的粒度只和第一个时间轮Level0的tickMs相等,Level1走动一格只表示当前这一格的所有任务在Level0走完一圈后都会失效,就好比Level1指向0-8时表示Level0中任务时间在0-8之间只有Level0走完一圈才会全部失效。因此需要把Level1的任务⑧⑨从Level1中解除出来,放到更细粒度的Level0中才能真正决定任务什么时候真正失效。所以在Timer8时,Level1的任务⑧⑨被一一放回Level0的各个bucket中,原先在Level1中挤在同一个单元格里的多个任务被分散在Level0的各个单元格中,这样原先在Level1的各个任务现在就会参照Level0中的tickMs(也就是真实的tickMs)。
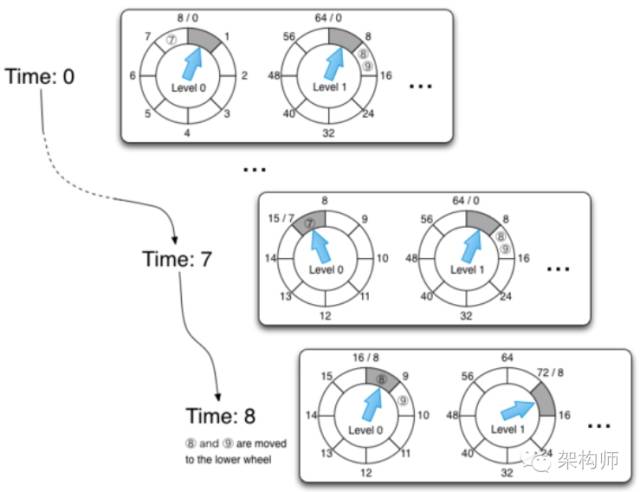
图3-78 层级时间轮的收敛和发散
可以这么理解,在Time0到Time7之间,任务⑧⑨在Level1中蓄势待发,但是因为Level0还没有走完一圈,Level1的指针不会移动,只有Level0走完一圈后,Level1才会移动一次,并把Level1一格的任务按照Level0的tickMs粒度重新划分。Level0代表的永远是真实的时钟移动,超时的任务一定是在Level0中被选中的,在其他Level中的任务在接近超时的时候只会源源不断地进入到Level0中。可以认为除了Level0,其他Level都是虚拟出来的时间轮,这些更高级的时间轮因为tickMs粒度比较大,可以存储数据量更大的任务,但是不具备执行超时任务的能力,当高级别的时间轮发生一次tick后,需要把tick指向的所有任务移动到低级别的时间轮中,从而有机会被放到Level0中真正地执行。
来源:zqhxuyuan.github.io
原文:http://zqhxuyuan.github.io/2016/05/26/2016-05-13-Kafka-Book-Sample/#%E7%AC%AC%E4%BA%8C%E7%AB%A0_%E7%94%9F%E4%BA%A7%E8%80%85