这篇简单梳理下与多线程相关的硬件知识,了解它们能够让我们更清晰的了解多线程工作的本质,以及关键字synchronized、volatile、final的实现原理。
我们会发现,每一个硬件部件的引入都是为了解决某些问题,然后它们又诞生了新的问题。(程序员就处在这样的永无止境的循环中……)
高速缓存
1. 缓存概念
先来说说缓存的概念,现在的处理器运行速度远大于内存的读写速度的,为了填补两者之间鸿沟,硬件设计者引入了高速缓存的概念。

如左图,高速缓存是一种存取速率远比内存快而容量远比主内存小的存储部件。有了它之后,CPU不再与主内存直接打交道,而是读、写高速缓存里的数据,高速缓存再与主内存发生读、写。
如右图,现代处理器一般具有多个层级的高速缓存,分为一级缓存(L1d Cache)、二级缓存(L2d Cache)、三级缓存(L3d Cache)。一级缓存可能直接集成在处理器内核中,存取速度 一级缓存 > 二级缓存 > 三级缓存。存储容量一级缓存 < 二级缓存 < 三级缓存。
2. 缓存结构

高速缓存的内部结构是一个拉链散列表,和
HashMap的底层结构以及原理(可见 HashMap原理解析)十分相似。它分为若干桶,每个桶是一个链表,包含若干缓存条目(
Cache Line)
缓存条目近一步可以分为三个部分:

- Data Block(缓存行):存储从主内存中读取的数据以及准备写入主内存的数据,一个缓存行可存储多个变量
- Tag:包含缓存行中数据的位置信息
- Flag:缓存行的状态信息
CPU访问内存时,会通过内存地址解码的三个数据:index(桶编号)、tag(缓存条目的相对编号)、offset(变量在缓存条目中的位置偏移)来获取高速缓存中对应的数据。
如果找到且缓存行的Flag为有效,则缓存命中;否则缓存会从主内存中加载对应数据,该过程处理器会处于停顿(stall)状态不能执行其他指令。
3. 缓存一致性协议(MESI)
由于每个处理器都有自己的高速缓存,当多线程并发访问同一个共享变量时,就会出现这些线程所在的处理器各自保存了一份该共享变量的副本数据。当一个处理器对副本数据进行更新后,如何让其他处理器察觉并作出反应呢?这就要靠:缓存一致性协议(MESI协议)
注:下面两节概念可快速浏览过,主要结合3.3节例子回过头来理解
3.1 MESI概念
MESI协议将缓存条目的状态划分为了四种:
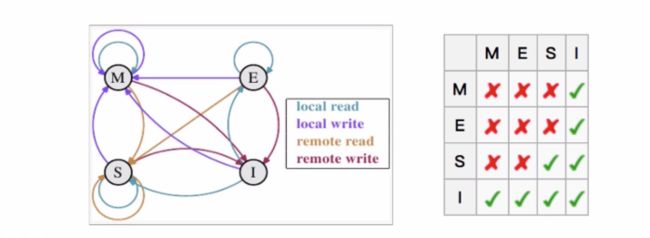
M:被修改(Modified)
该缓存行的数据是被修改过的,与主存中的数据不一致。任一时刻,多个处理器的高速缓存中,Tag值相同的缓存条目,只有一个能处于该状态。
在其它CPU读取同一Tag的缓存条目数据之前,该缓存行中的数据会写回主存,然后变为独享(exclusive)状态E:独享的(Exclusive)
该缓存行以独占的方式保留了相应内存地址的副本数据,其他所有CPU上的高速缓存都不能保留该数据的有效副本。该缓存条目的数据与主存中数据一致。
在任何时刻当有其它CPU读取该内存时,该状态将变成共享状态(shared);当CPU修改该缓存行中内容时,该状态变成修改状态(Modified)。S:共享的(Shared)
该缓存行的数据可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致。
当有一个CPU修改该缓存行数据时,其它CPU中该缓存行可以被作废,即变成无效状态(Invalid)。I: 无效的(Invalid)
该缓存行是无效的,不包含任何内存地址对应的有效副本数据。该状态是缓存条目的初始状态。
3.2 MESI消息
另外,为了缓存之间的通讯,协调各个处理器的读、写内存操作,MESI协议还定义了下面的一组消息:
| 请求消息 | 描述 | 返回消息 | 描述 |
|---|---|---|---|
| Read | 通知其他处理器,主内存正准备读取某个数据。该消息包含待读取数据的内存地址 | Read Response | 返回请求读取的数据,该消息可能是主内存返回的,也可能是其他高速缓存返回。 |
| Invalidate | 通知其他处理器将高速缓存中指定内存地址对应的缓存条目状态置为I,即通知这些处理器删除指定内存地址的副本数据 |
Invalidate Acknowledge | 接收Invalidate消息必须回复该消息,表示已经删除其高速缓存上面的数据 |
| Read Invalidate | 由Read和Invalidate组合而成的复合消息。作用在于通知其他处理器,当前处理器准备更新(Read-Modify-Write)一个数据,请求其他处理器删除自己高速缓存中的副本副本数据。 |
Read Response与Invalidate Acknowledge | 接收到请求的处理器必须返回这两个消息 |
| Writeback | 该消息包含需要写入主内存的数据及其对应的内存地址 |
处理器在执行内存读写操作时,在有必要的情况下会往总线发送特定的请求消息,同时每个处理器还会嗅探(也称拦截)总线中由其他处理器发出的请求消息并在一定条件下往总线回复相应的响应消息。
3.3 举例说明
上面的概念简单看一下就行,我们主要要明白的是:MESI协议对内存数据访问的控制类似读写锁,它使得针对同一地址的读内存操作是并发的,而针对同一地址的写内存操作是独占的。从而保障了缓存间数据的一致
现在我们来举两个例子看一下具体过程:
并发读
当处理器Processor 0要读取缓存中的数据S时,如果发现S所在的缓存条目状态为M、E或S,那么处理器可直接读取数据。
如果S所在的缓存条目状态状态为 I,说明Processor 0的缓存中不包含S的有效数据。这时,Processor 0会往总线发送一条Read消息来读取S的有效数据,而缓存状态不为 I 的其他处理器(如Process 1)或主内存(其他处理器缓存条目状都为 I 时从主内存读)收到消息后需要回复Read Response,来将有效的S数据返回给发送者。
需要注意的是,返回有效数据的其他处理器(如Process 1),如果状态为M,则会先将数据写入主内存,此时状态为E,然后在返回Read Response后,再将状态更新为S。
这样,Processor 0读取的永远是最新的数据,即使其他处理器对这个数据做了更改,也会获取到其他处理器最新的修改信息。
互斥写
当处理器Processor 0要向地址A中写数据时,如果地址A所在的缓存条目状态为E、M,说明Processor 0已拥有该数据的独占权,Processor 0可直接将数据写入A,然后将缓存条目状态改为M
如果写的缓存条目状态为S,处理器Processor 0需要往总线发送Invalidate消息来获取该缓存条目的独占权,当接收到其他所有处理器返回的Invalidate Acknowledge消息后,Processor 0才会确定自己已获得独占权,然后再将数据更新到地址A中,并将对应的缓存条目状态改为M
如果写的缓存条目状态为I,处理器Processor 0需要往总线发送Read Invalidate消息来获取该缓存条目的独占权,其他步骤同S
需要注意的是,如果接收到Invalidate消息的其他其他处理器,缓存条目状态为M,则该处理器会先将数据写入主内存(以方便发送Read Invalidate指令的处理器读到最新值),然后再将状态改为I
这样,Processor 0与其他处理器写的时候,永远只有一个处理器能够获得独占权,即实现了互斥写。
写缓冲器和无效化队列
依照上面的MESI协议,多线程并发访问同一个共享变量时,并发读和互斥写,应该是已经解决了数据一致性问题,那为什么我们编程中还是会出现 “可见性” 这样线程不安全的问题呢?
原因在于写缓冲器和无效化队列的引入。MESI协议虽然解决了缓存一致性问题,但其本身有一个性能缺陷:处理器每次写数据时,都得等待其他所有处理器将其高速缓存中对应的数据删除,并接收到它们返回的Read Response与Invalidate Acknowledge消息后才执行写操作。这个过程无疑是很消耗时间的。
无奈的硬件设计者,解决了缓存一致性问题后,为了解决新出现的性能问题,又引入了新的部件:写缓冲器和无效化队列。
1. 写缓冲器
写缓冲器是处理器内部一个容量比高速缓存还小的高速存储部件,每个处理器都有自身的写缓冲器,且一个处理器无法读取另一个处理器上的写缓冲器内容。写缓冲器的引入主要是为了解决上面提到的MESI的写延迟问题。
1.1 写操作过程
引入写缓冲器后,当处理器要写入数据时:
如果相应的缓存条目状态为 E、M,则直接写入,无需发送消息(照旧)
如果相应的缓存条目状态为 S, 处理器会将写操作相关信息存入写缓冲器,并发送Invalidate消息。(不再等待响应消息)
如果相应的缓存条目状态为 I,发生“写未命中”,将写操作相关信息存入写缓冲器,并发送Read Invalidate消息。(不再等待响应消息)
当处理器将写操作写入写缓冲器后,则认为写操作已经完成。而实际上,当处理器收到其他所有处理器回应的Read Response、Invalidate Acknowledge消息后,处理器才会将写缓冲器中对应的写操作写入相应的缓存行,这个时候,写操作才算真正完成。
写缓冲器让处理器在执行写操作时不需要再额外的等待,减少了写操作的延时,提高了处理器的指令执行效率。
1.2 读操作过程
引入写缓存器后,处理器读取数据时,由于该数据的更新结果可能仍然停留在写缓冲器中,所以处理器会先从写缓冲器中找寻数据,没有找到时,才从高速缓存中找。
这种处理器直接从写缓冲器中读取数据的技术被称为:存储转发
2. 无效化队列
处理器在接收到Invalidate消息后,并不马上删除消息中指定地址对应的副本数据,而是将消息存入无效化队列之后就回复Invalidate Acknowledge消息,从而减少了执行写操作的处理器的等待时间。
需要注意的是,有些处理器(如X86)可能并没有使用无效化队列
3. 写缓冲器和无效化队列带来的新问题
写缓冲器和无效化队列的引入带来了性能的提高,同时又带来了新的两个问题:内存重排序与可见性
3.1 内存重排序
| Processor 1 | Processor 2 |
|---|---|
| data = 1; // S1 | |
| ready = true; // S2 | |
| while(!ready) continue; //L3 | |
| system.out.println(data); //L4 |
如上表,变量data初始值为0,变量ready初始值为false。两个处理器Processor 1和Processor 2在各自的线程上执行上述代码。执行的绝对时间顺序为 S1——>S2——>L3——>L4
以StoreStore(写又写)操作为例,看写缓冲造成的重排序
如果S1步data值的写操作被写入写缓冲器、还没真正的写到高速缓存中,而S2步的ready值的写操作已经写入到了高速缓存。那在L3步读取ready值时,根据MESI协议,会读到正确的ready值:true;但在L4步读取data时,会读到data的初始值0,而不是在另外一个处理器写缓冲器中的值:修改值1
在处理器Processor 2看来,S1和S2的执行顺序就好像反了一样,即发生了重排序。以LoadLoad(读又读)为例,看无效化队列造成的重排序
同上面的步骤,S2已被同步到高速缓存,S1写入写缓冲器,并发送了Invalidate消息。当执行L3时,读取到正确的值:true,当执行到L4时,由于无效化队列,Processor 2虽然发送了Invalidate Acknowledge消息,但并没有删除自己高速缓存中的data数据,所以会读取到其高速缓存中的data:0
3.2 可见性
一个处理器的写缓冲器中的内容是无法被其他处理器读取的,这个也就造成了一个处理器更新一个共享变量后,对其他处理器而言,看不到这个更新的值,即可见性。
写缓冲器是可见性问题的硬件根源。
内存屏障
为了解决写缓冲器和无效化队列带来的可见性和重排序问题,操心碎的硬件设计者又推出了新的方案:内存屏障。
内存屏障是被插入两个CPU指令之间的一种指令,用来禁止处理器指令发生重排序(像屏障一样),从而保障有序性的。另外,为了达到屏障的效果,它也会使处理器写入、读取值之前,将写缓冲器的值写入高速缓存,清空无效队列,从而“附带”的保障了可见性。
内存屏障其实就是volatile、synchronized的底层实现原理,具体细节将在下一章讨论。
本文总结自:
黄文海《Java多线程编程实战指南》——第12章