知乎登陆
知乎登陆
@(博客)[Python, 登陆, 知乎, 爬虫]
文章目录
- 知乎登陆
- 背景
- 题外话
- 环境
- 寻找切入点
- 问题的转移1
- 问题的转移2
- 继续撸
- 开始代码
- 完善代码
018.8.12
背景
因为学年综合实践准备的一部分需要爬取知乎全站,所以为了方便,自动登陆是很有必要的。而由于许多学习爬虫的各友,都爱拿知乎练手——其实我倒非然,这算是第一次对知乎“开战”,是客观因素导致的必然——以至于知乎加强了反扒机制

我爬虫经验有限,实在不知该对这样的加密如何下手,一番搜索引擎之后,得到的都是过期操作。Github上找到了通过二维码扫描登陆的思路,那就以此宣战吧。
也在此感谢这名网友的无私奉献,点击可查看
题外话
说句题外话:切不可以惯性思维
另:完整代码已上传Github,文章末尾有链接。里边的study文件是我整个思考过程中产生的测试代码,如果只是需要实现知乎登陆,则study文件可以直接删除
环境
(1)python3.6
(2)主要第三方库:
requestsPIL:pip3 install -i https://pypi.douban.com/simple/ pillow利用豆瓣源,加快下载速度,因为直接安装可能会出现timeout的错误
(3)chrome
寻找切入点
第一步肯定是先来到知乎提供二维码登陆的界面,利用开发工具,可查看请求这个二维码图片需要那些数据
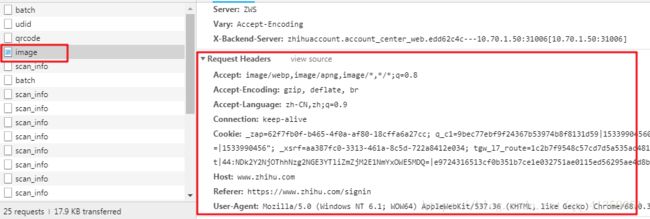
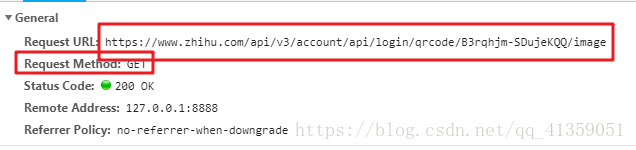
能看到是get请求,headers也很寻常,但多次刷新可发现请求的url地址有一部分在改变
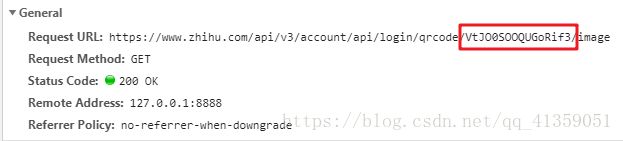
这肯定算不上什么难点,我们寻找前面的文件,能找到这部分动态改变的值
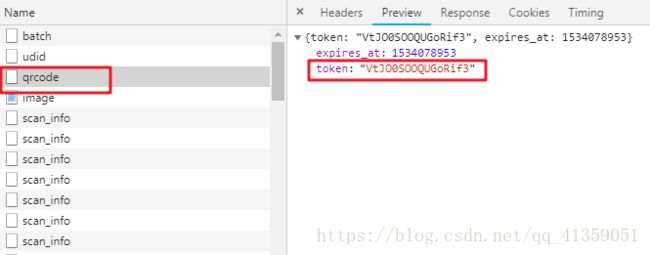
为了方便阐述,那就把image称之为A文件,qrcode成为B文件。这里就有了一个思路,先请求B文件,拿到token值以后,拼接成目的url,再去请求A文件
问题的转移1
于是我们从A迁移到了B
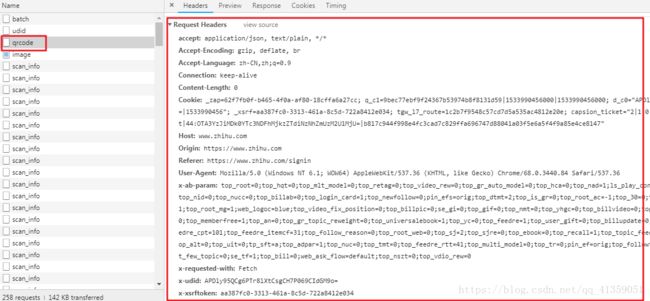
可见请求B文件的时候,headers字段是真的很多,但绝对不会所有都必要,这只能排除法了
以我拙见是这样处理的,首先看清楚了,是POST请求(从爬虫到现在也几个月了,还是爬了不少网站,真的不提交数据用post请求的,我第一次见,所以之前一直是惯性思维的用get,然后一直请求失败, 所以各位入门爬虫的注意了,千万注意了别掉坑里)
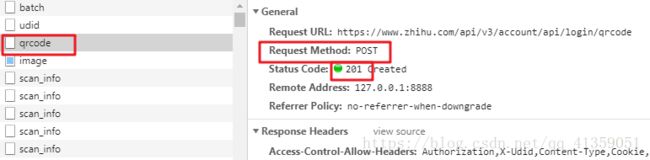
复制了所有headers,做一次post的请求,再看看状态码是不是201(为了避免请求被重定向,建议打印请求内容,或者关闭重定向,后面皆以打印内充处理不再单独提示)(对应study/test1.py文件)
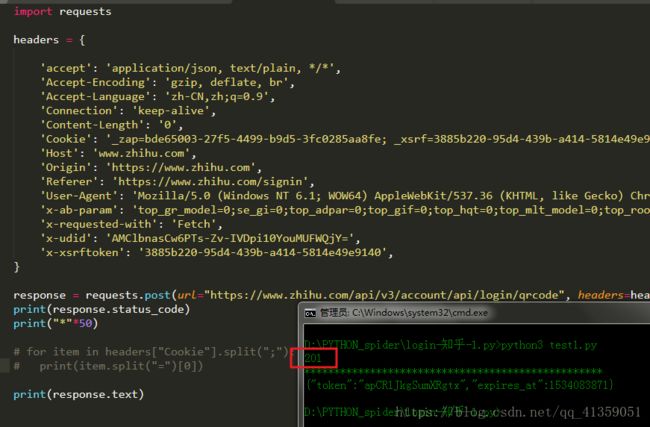
可以说很OK,然后就开始排除法,首先去掉的是最常用不到的噻。通过几轮排除下来,发现Cookie和User-Agent是必要的,既然需要用到cookie,我们就得维持会话,所以要实例化一个session对象了,实现如下:
session = requests.session()
顺便也把Cookie分解了,看看需要哪些内容
for item in headers["Cookie"].split(";"):
print(item.split("=")[0])

(这些很重要,可得记住了)
问题的转移2
那么如何让session对象持有完整的cookie呢?
我们回到最初的起点,再来分析一下完整的过程
打开开发者工具,刷新页面,然后点击二维码登陆(当然,这里建议你清除一下cookies,最好选择**【高级】**而不是【基本】)
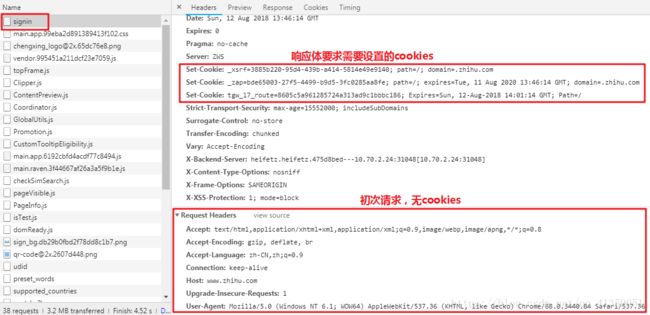
我们可以看到第一次请求登陆界面的时候,请求是不带cookies的;而请求之后,按照响应体的要求,会设置对应的**_xsrf**,_zap,tgw_17。前面我们知道需要6个,这里才三个肯定是不够的,所以继续找signin后面的文件,看看到底有什么猫腻在里头
于是在udid这个文件中,你会发现响应体要求设置q_c1,d_c0;也就是说,在成功请求这个文件之后,Cookie就包含这两个部分了
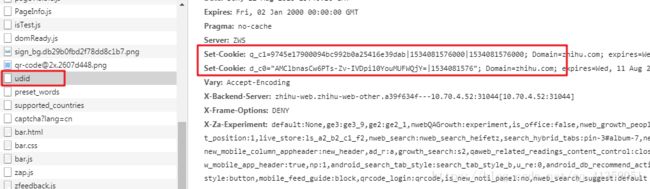
照例复制下完整的headers,找到请求的url,以及请求方式(注意了!这里也是post),最后排除法,找到必要的部分(对应study/test2.py文件)
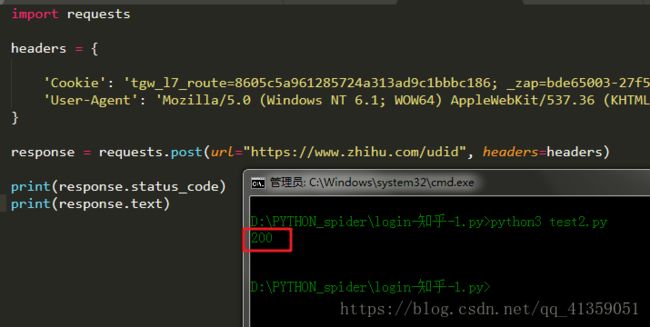
仍然是Cookie以及User-Agent
继续撸
还不够,现在我们的cookies还差capsion_ticket部分,所以继续撸
于是找到了captcha?lang=cn文件,它的响应体告诉浏览器,可以设置capsion_ticket了
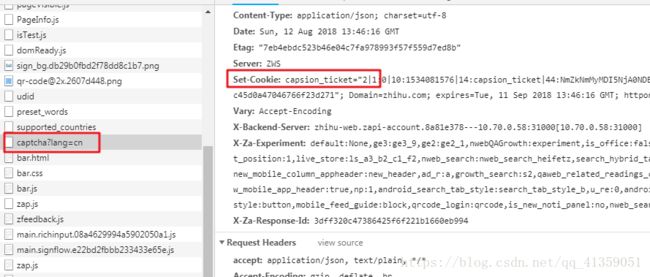
(对应study/test3.py文件)
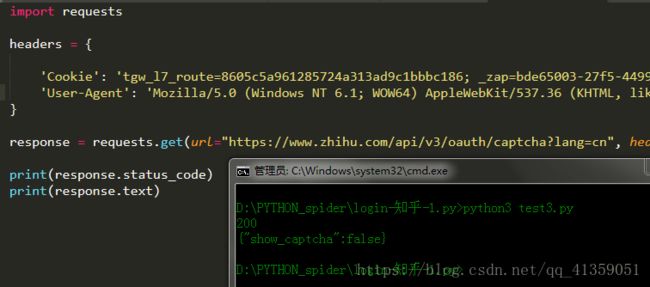
开始代码
有了这波分析,我们就可以开始动手敲代码了
(对应studyget-qrcode.py文件)
import requests
session = requests.session()
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36'
}
# 第一次请求,为了Cookie(_xsrf,_zap,tgw_17)
session.get(url="https://www.zhihu.com/signin", headers=HEADERS)
# 第二次请求,为了Cookie(q_c1,d_c0)
session.post(url="https://www.zhihu.com/udid", headers=HEADERS)
# 第三次请求,为了Cookie(capsion_ticket)
session.get(url="https://www.zhihu.com/api/v3/oauth/captcha?lang=cn", headers=HEADERS)
# 第四次请求,为了token,用于构建二维码图片的请求链接
response = session.post(url="https://www.zhihu.com/api/v3/account/api/login/qrcode", headers=HEADERS)
# print(response.json())
# 第五次请求,为了二维码图片
url4QR = "https://www.zhihu.com/api/v3/account/api/login/qrcode/{0}/image".format(response.json().get("token"))
response = session.get(url=url4QR, headers=HEADERS)
if response.status_code == 200:
with open("qr.jpg", "wb") as file:
file.write(response.content)
print("【保存二维码成功】")
else:
print("【请求二维码图片错误】")
运行结果如下
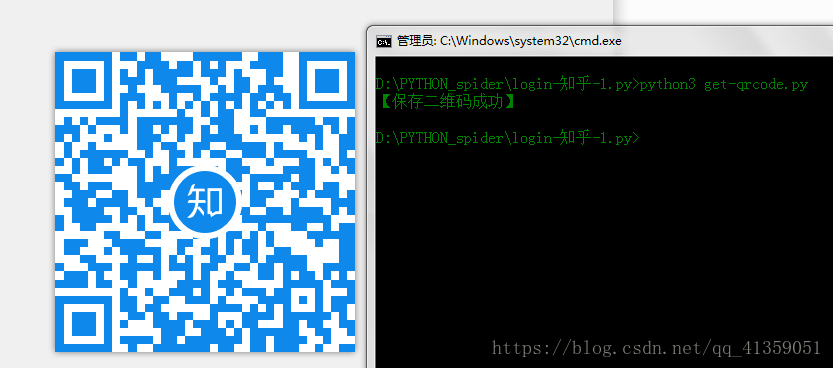
这时候以为扫描二维码就登陆成功了吗?然而没有
我们扫描一下网页的二维码登陆一下试试,会发现在手机上点击确认登陆以后,请求知乎www.zhihu.com网页的时候,Cookie又多了一个z_c0

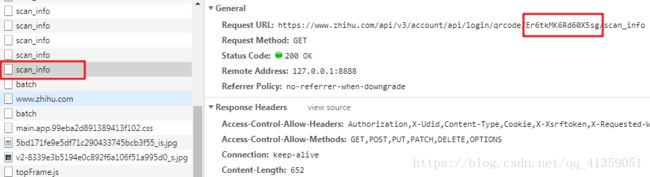
晕!但是扶住墙,老规矩。可以看到距离知乎首页文件最近的一个scan_info文件,说了要设置z_c0
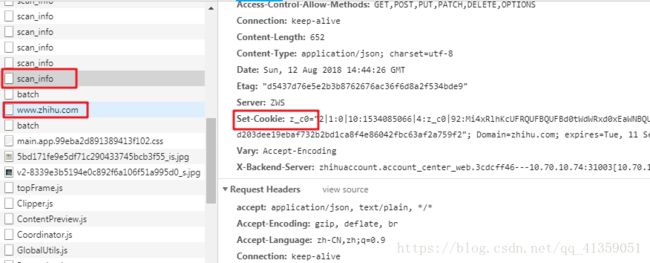
于是在我们扫描二维码之后,应该先请求这个文件,再请求首页文件;查看请求的url,也能发现,这个文件也有一部分是动态的,而且正是之前获取的token
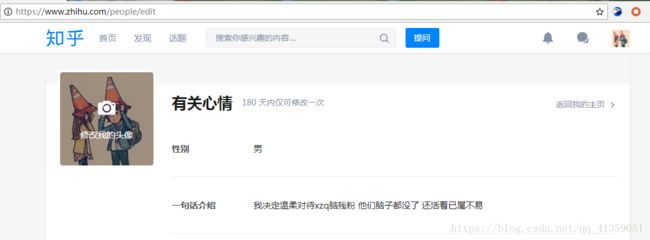
为了确保我们成功登陆,可测试编辑页面,因为这个页面只有在登陆成功后可以访问,不然就会被重定向到登陆页面去
添加代码如下
# 阻塞程序,给予用户扫描二维码的时间
input("请随便输入后回车")
# 请求scan_info文件,并打印状态码
print(session.get("https://www.zhihu.com/api/v3/account/api/login/qrcode/{0}/scan_info".format(token), headers=HEADERS).status_code)
# 请求编辑页面
response = session.get("https://www.zhihu.com/people/edit", headers=HEADERS, allow_redirects=False)
if response.status_code == 200:
print("登陆成功")
print(response.text[:10000])
嗯,写到这儿的时候,宿舍断网了,于是我打开手机热点准备测试代码(之所以要说这个细节,因为我不确实是不是因为使用的手机热点,才造成了后面的错误),结果第一次请求的时候报了如下错
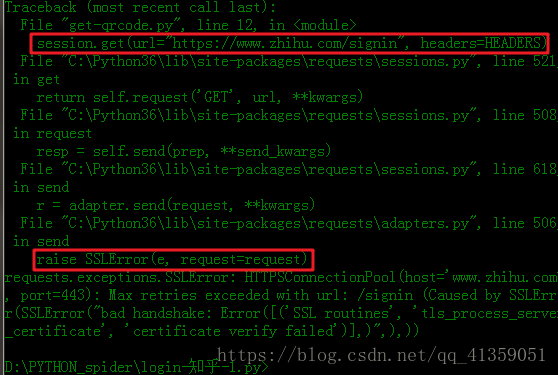
其实关闭SSL验证就好,加上参数verify=False,加了这个参数以后会报InsecureRequestWarning警告,我的处理方式是关闭这个警告。加上如下代码即可
from requests.packages import urllib3
from requests.packages.urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
好了,测试代码吧。效果如下
成功
华丽的分割线---------------------------------------------------------------------------
今天起来测试过了,的确是因为使用手机热点才造成SLLError。不过我认为也可以加上之前的处理措施,避免因此出错
完善代码
现在基本功能实现了,但不够完善
- 比如难道用户每次使用都要登陆?我们可以设置本地cookies,这样就可以等cookies失效之后再登陆
- 比如难道每次用户都要手动去打开二维码图片?我们可以利用PIL库来实现图片自动打开
以下是我程序的整体逻辑设计
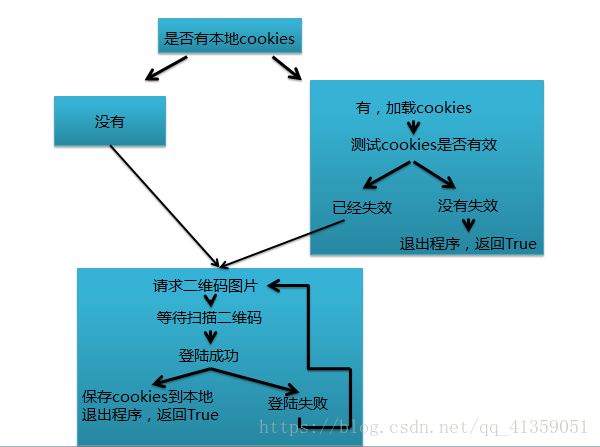
以下是我代码的逻辑设计
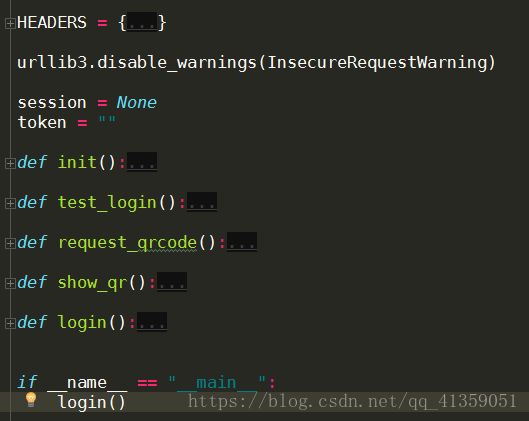
因为完整代码已经上传GitHub,有详细注释,就不在这细说了