U-GAT-IT
论文原文:U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
一、解决的问题——unpaired image-to-image translation
1. Selfie2Anime

2. Anime2Selfie

3. Horse2Zebra

4. Zebra2Horse

6. Cat2Dog

7. Dog2Cat

8. Photo2Vangoph

9. Photo2Portrait

二、Overview
本文在CycleGAN的基础上,通过一个辅助的分类器提出了一种新的注意力机制(attention mechanism),并结合了新的正则化方式AdaLIN,构建了一个end2end的弱监督图像跨域转换模型。
文本的亮点有2——
- 使用新的attn机制,能够引导生成器G关注那些区分源域与目标域的更重要的区域,从而使得G的性能能够更好发挥,并让G对于图像整体的改变与obj.形变有更好的处理能力。以往的GAN由于前景obj.与背景混在一起,因此GAN的性能被均摊弱化了。
- 引入新的正则化方式AdaLIN(自适应layer norm与instance norm),考虑到以下:

我们可以看到IN与LN的异同——①相同点是都是对instance做得正则,与Batch无关;②不同点是IN进一步局限到单个channel之间,而LN则跨过所有channels。因此,IN假设不同feature的不同channels之间是无关的(uncorrelated),因此单独作用于每个channel可能会引入对原来的语义(semantic content)的干扰;而LN尽管是对所有channels作权衡,但考虑到normalization的本质还是“平滑”,容易抹消一些语义信息。作者认为可以把两者结合起来,互相抵消他们之间的不足,同时又结合了两者的优点。
adaptive的最朴素的思想是寻找一个比率ratio,来权衡某一层中IN与LN的关系,即:
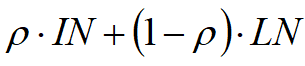
其中这个![]() 就是一个权重,经过训练得到(前向、方向传播、梯度更新)。本文正是这么做的!
就是一个权重,经过训练得到(前向、方向传播、梯度更新)。本文正是这么做的!
三、Attention
了解作者的具体思路之前,我们要回顾一下attn的一个常见的结构。
一般来说,在卷积网络中,attn的结构如下:

其原理与作用是:通过矩阵点积可以计算矩阵每个位置i与其他位置的关系,和这个关系再经过softmax作先相对处理与exp平滑后可以较好地表征不同位置的重要程度。再用这个map去与原来的feature map做pixel-wise的乘积,就可以对重要的地方做增强(highlight),对次要的地方做弱化(weaken)。具体的计算过程如下图所示

但追溯回去的更朴素的思想是来源于分类——CAM(Class Activation Mapping)。

如上图所示,利用CNN+FC进行分类的经典结构,但是FC有一个不优的地方就是对输入图像大小有限制,必须是固定的,不然拉成长向量后无法匹配。于是我们可以对CNN的最后一层输出![]() 做GAP(Global Average Pooling)或者GMP(Global Maximum Pooling),压缩为
做GAP(Global Average Pooling)或者GMP(Global Maximum Pooling),压缩为![]() 长向量,这样就不受HW的影响了。将这个向量经过若干层FC就可以进行分类了。
长向量,这样就不受HW的影响了。将这个向量经过若干层FC就可以进行分类了。
好了,回来我们思考:在测试的时候,fc的权重 是固定的,那么分类的结果就直接依赖于GAP的结果,因此,在分类中:属于某第j类的概率
是固定的,那么分类的结果就直接依赖于GAP的结果,因此,在分类中:属于某第j类的概率 。其中
。其中![]() 就是原feature的第i个channel经过avg池化的值。经过池化后消失了空间信息,但是
就是原feature的第i个channel经过avg池化的值。经过池化后消失了空间信息,但是![]() 越大说明原来的二维特征中存在某部分值就越大!那么,如果我们把fc的权重用来对feature的每个channel做加权叠加呢?
越大说明原来的二维特征中存在某部分值就越大!那么,如果我们把fc的权重用来对feature的每个channel做加权叠加呢?![]() 就应该能够体现空间上,哪一部分对于分到第j类的贡献最大,经过正则化可以得到上图中的热值图!因此fc的权重本身就是对feature的一种注意力机制,
就应该能够体现空间上,哪一部分对于分到第j类的贡献最大,经过正则化可以得到上图中的热值图!因此fc的权重本身就是对feature的一种注意力机制,![]() 就是经过attn highlight后的feature!
就是经过attn highlight后的feature!
四、U-GAT-IT
下面仅从cycle的一个方向讲解:
1. Generator --

大致的思路是:分别输入源域图像![]() 与目标域图像
与目标域图像![]() ,经过编码器
,经过编码器![]() (两次下采样与4个残差块)可以得到输出的特征
(两次下采样与4个残差块)可以得到输出的特征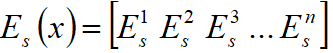 .
.
在这里网上经过GAP或者GMP后,经过辅助的分类器![]() 分类(二分类,是源域-0还是目标域-1),利用
分类(二分类,是源域-0还是目标域-1),利用![]() 的权重
的权重 作为channel wise的attention,可以得到attention focused on后的feature:
作为channel wise的attention,可以得到attention focused on后的feature:

最后有: 。注意这里的a或者A是activation map的意思。
。注意这里的a或者A是activation map的意思。
这之后,将黄色的activation map往上继续前馈,(猜测应该是)再次使用GAP(不用GMP是因为它不可导)后经过fc,预测2c个参数,c对应feature map的通道数,其中,c个是作为缩放因子![]() ,c个是作为偏移量
,c个是作为偏移量![]() ,
,![]() 与
与![]() 将应用于后面的特征做AdaLIN正则化——
将应用于后面的特征做AdaLIN正则化——
1)先分别以IN和BN的方式求出均值(![]() ,
,![]() )和标准差(
)和标准差(![]() ,
,![]() ),对feature做标准化。
),对feature做标准化。

2)加权求和,

这与Style-based GAN中的AdaIN是很相似的。
其中,![]() 是一个学习权重,类似switchable normalization中的一样。通过反向传播更新,即:
是一个学习权重,类似switchable normalization中的一样。通过反向传播更新,即: ,
,![]()
是学习率。
这之后,将正则化后feature继续前馈,经过8个残差和2个上采样,得到输出。
这里我们注意到,![]() 与
与![]() 是从
是从![]() 得到的,
得到的,![]() 与
与![]() 由于正则化有关系,正则化IN可以考虑强化content,LN可以综合全局,即
由于正则化有关系,正则化IN可以考虑强化content,LN可以综合全局,即

这也就是为什么文章的attn这么强大的缘故,因此所有一切都被串联在一起。通过BP学习,attn能够更好的关注在源域与目标差异所在的区域(对于Selfie2Anime的任务就是shape change了)。
2. Discriminator --
同样![]() 也包含一个编码器
也包含一个编码器![]() 和解码器(分类器)
和解码器(分类器) ,和辅助分类器
,和辅助分类器![]() 用于生成attn。结构如下——
用于生成attn。结构如下——

与生成器G是类似的,这里不做重复。
五、Objective function
1. GAN Loss

2. Cycle Loss

3. Identity Loss

4. CAM Loss
前面三个loss是很平常的,下面两个是关于两个辅助分类器的分类loss。
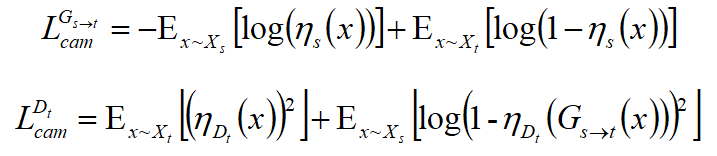
最后总的loss是四个的加权和(当然被忘了cycle另一个方向的版本)。

六、Implementation
作者提了一些trick,如G用ReLU做激活,D用Leaky ReLU(slope=0.2)激活。采用multi-scale的PatchGAN。训练的时候,对lr前500k个iterations固定1e-4,然后线性衰减,共1000k个iterations。对权重的正则化项系数取0.02.
作者只在G和D的解码器使用AdaLIN模块,在编码器使用IN。这是因为:decoder的作用是:残差块能够嵌合features,上采样块则负责合成目标图像,因此在编码阶段加入AdaLIN意义不大。
** 关于原笔记PDF欢迎私聊博主获取!