LinkedHashMap jdk1.8基础和源码分析
文章目录
- LinkedHashMap实例讲解
- LinkedHashMapEntry节点结构
- 构造函数
- 一、增
- 1、构造节点
- 2、afterNodeInsertion(boolean evict)
- 二、删
- afterNodeRemoval(Node< K,V> e)
- 三、改
- afterNodeAccess(Node< K,V> e)
- 四、查
- get(Object key) 查询操作
- containsValue(Object value)
- 总结
上一篇文章:
HashMap jdk1.8基础和源码分析
// HashMap继承自AbstractMap,实现了Map接口
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
// LinkedHashMap继承自HashMap,实现了Map接口
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
HashMap是数组+单链表的实现方式,迭代是无序的,next只能指向本bucket的其它Node,JDK1.7是头插法,JDK1.8是尾插法并支持红黑树。
LinkedHashMap是数组+双向链表的实现方式,迭代有序,before和after可以指向其它bucket的LinkedHashMapEntry,并由accessOrder 决定迭代输出的顺序,一是按照插入节点的顺序,二是按访问顺序。
LruCache/DiskLruCache 缓存的核心是:LRU(Least Recently Used)最近最少使用算法,即当缓存快要满时,会优先淘汰那些近期最少使用的缓存对象。如果满了就用LinkedHashMap的迭代器删除队头元素。removeEldestEntry
LinkedHashMap实例讲解
下面来看下LinkedHashMap能实现一些什么样的效果:
-
accessOrder = false,是按插入节点的顺序进行遍历
-
assessOrder = true,是按访问的顺序进行遍历
System.out.println("以下是accessOrder=false的情况: 默认为false");
Map<String, String> map = new LinkedHashMap<>();
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
map.put("2", "d");
map.get("1");
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
System.out.println("以下是accessOrder=true的情况:");
map = new LinkedHashMap<String, String>(16, 0.75f, true);
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
map.put("5", null);
map.put("3", "e");//3调整至末尾
map.get("2");//2移动到了内部的链表末尾
iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
日志输出:
以下是accessOrder=false的情况: 默认为false
1=a
2=d //更新了value,但是遍历顺序不会改变
3=c
以下是accessOrder=true的情况:
1=a //长期不进行访问的,会存放在链表的首部
5=null
3=e
2=b //最近访问的map,最后输出
LinkedHashMapEntry节点结构
LinkedHashMap的节点比HashMap的节点多一个before、after的引用。
static class LinkedHashMapEntry<K,V> extends HashMap.Node<K,V> {
LinkedHashMapEntry<K,V> before, after;
LinkedHashMapEntry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
构造函数
head/tail 头结点和尾节点
构造函数多了一个accessOrder,accessOrder默认为false
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
//双向链表的头结点(head/eldest)
transient LinkedHashMapEntry<K,V> head;
//双向链表的尾节点(tail/youngest)
transient LinkedHashMapEntry<K,V> tail;
//true for access-order,false for insertion-order
final boolean accessOrder; //true按访问顺序,false按插入顺序
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false; //
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
//可指定accessOrder,其余初始化情况,默认为false
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
HashMap的增put、删remove、改put、查get 都会调用以下方法,HashMap其实是个空实现,真正的实现在LinkedHashMap中。
//HashMap其实是个空实现
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { } //访问、修改了元素
void afterNodeInsertion(boolean evict) { } //插入元素
void afterNodeRemoval(Node<K,V> p) { } //移除元素
一、增
LinkedHashMap没有重写put操作,是调用其父类HashMap的put(key, value)。
当不存在相同的key时,会通过newNode()创建一个LinkedHashMapEntry节点,添加在双向链表的尾部。
-
分析1:当存在key一样的数据时,回调afterNodeAccess(e),即更改的操作,可能会变更访问顺序
-
分析2:当不存在key一样的数据时,插入一条新的数据,回调afterNodeInsertion(true),即插入的操作。
1、构造节点
在创建新节点的时候,LinkedHashMap重写了newNode()方法,用于构建一个LinkedHashMapEntry节点。
默认创建一个LinkedHashMapEntry时,是将新插入节点放在双向链表的尾部。
//返回一个LinkedHashMapEntry节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMapEntry<K,V> p = new LinkedHashMapEntry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//将这个新插入的节点放在链表尾部
private void linkNodeLast(LinkedHashMapEntry<K,V> p) {
LinkedHashMapEntry<K,V> last = tail; //临时变量存储尾节点
tail = p;
if (last == null) //如果尾节点为null, 则是一个空链表,head 指向这个新的节点
head = p;
else { // 如果尾节点不为空,非空链表,更新p.before、last.after
p.before = last;
last.after = p;
}
}
2、afterNodeInsertion(boolean evict)
put操作时,如果不存在相同的key,通过newNode()添加一个新节点,会回调afterNodeInsertion()
afterNodeInsertion(true) 不需要对before、after、head、tail进行操作,因为不管是按访问顺序还是插入顺序遍历,这个新加入的节点都是添加到双向链表的尾部。
evict为true,且不是一个空链表,且需要删除最老的节点时,则会删除head头结点,removeNode是HashMap中的实现。
默认是不对头结点进行删除的,在构建一个LruCache会在达到Cache的上限时返回true,在容器快要满时,对最近最少使用的进行删除。
//LinkedHashMap实现
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMapEntry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true); //见remove的分析
}
}
//默认返回false则不删除节点。构建一个LruCache会在达到Cache的上限时返回true
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
二、删
LinkedHashMap没有重写remove(),是调用其父类HashMap的remove(Object key)。
如果存在匹配的key,会执行afterNodeRemoval()将链表的指向删除。
afterNodeRemoval(Node< K,V> e)
分析1:如果e是头结点,则head指向e.after;否则e的上一个节点的after指向e.after
分析2:如果e是尾节点,则tail指向e.befor;否则e的下一个节点的before指向e.before
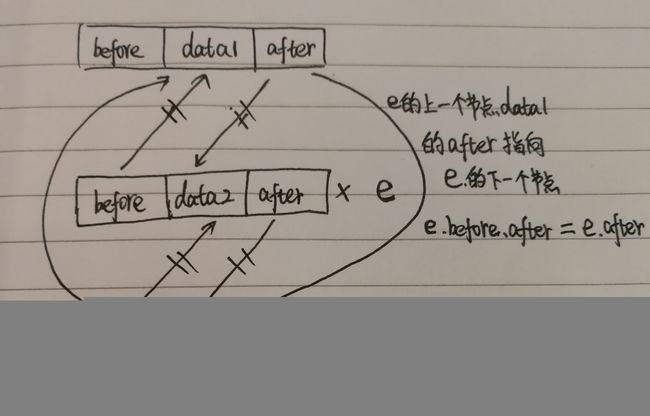
//linkedHashMap实现
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMapEntry<K,V> p =
(LinkedHashMapEntry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null) //见分析1
head = a;
else
b.after = a;
if (a == null) //见分析2
tail = b;
else
a.before = b;
}
三、改
LinkedHashMap没有重写put操作,是调用其父类HashMap的put(key, value)。
-
分析1:当存在key一样的数据时,回调afterNodeAccess(e),即更改的操作,可能会变更访问顺序
-
分析2:当不存在key一样的数据时,插入一条新的数据,回调afterNodeInsertion(true),即插入的操作。
afterNodeAccess(Node< K,V> e)
put操作时,如果存在相同的key,用newValue替代oldValue时,回调afterNodeAccess()
只有在accessOrder为true,即按访问顺序进行迭代遍历时,会将这个Node移到双向链表的尾部,实现最近访问的最后输出,长期不进行更新访问的在双向链表的首部。
- 分析1:当accessOrder为true,且e != tail时才执行;即按访问顺序进行遍历,且e不是尾节点(尾节点时已通过newNode()将当前节点添加到链表的尾部,所以无需操作)。
- 分析2: 如果e是头结点,即e.before为null,head指向e.after;否则e的上一个节点的after将指向e.after
- 分析3:如果e是尾节点,即e.after为null, tail指向e.before;否则e的下一个节点的before将指向e.before
- 分析4:如果尾节点为null,是个空链表,则head指向e;否则将e添加到链表的尾部,e.before=tail,tail.after=e;
- 分析5:尾节点tail指向变更的这个节点e
//LinkedHashMap实现
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMapEntry<K,V> last;
if (accessOrder && (last = tail) != e) { //见分析1
LinkedHashMapEntry<K,V> p =
(LinkedHashMapEntry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null) //e是头结点,见分析2
head = a;
else
b.after = a;
if (a != null) //e是尾节点,见分析3
a.before = b;
else
last = b;
if (last == null) //空链表,见分析4
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
四、查
get(Object key) 查询操作
LinkedHashMap重写了get(Object key)方法,
只有在accessOrder为true时,会对访问顺序进行变更,即将当前节点放入双向链表的尾部,以实现最近访问的最后输出。
//linkedHashMap的实现
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null) //调用其父类HashMap的getNode()方法
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
containsValue(Object value)
linkedHashMap根据双向链表的head进行遍历匹配;
HashMap需要先对table数组进行遍历,然后对table中的每个table[i]进行单链表的遍历;
//linkedHashMap的实现
public boolean containsValue(Object value) {
for (LinkedHashMapEntry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
//HashMap的实现
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
总结
1、节点保留了HashMap的数组+单链表(红黑树)结构,另外节点新增before、after指针,实现了双向链表的结构(双向链表是有顺序的),hashMap具有的特性它都有。
2、accessOrder 为 false 则按插入顺序进行迭代遍历;accessOrder 为 true 则按访问顺序进行迭代遍历(默认accessOrder为false)。
3、put插入,afterNodeInsertion(),判断是否需要删除最老的节点,即长期没有被访问更新的节点。
4、put更新,afterNodeAccess(),只有在accessOrder为true时,才对双向链表的的链接顺序进行更改。
5、remove删除,afterNodeRemoval(),对双向链表的的链接顺序进行更改。
6、get查询,afterNodeAccess 只有在accessOrder为true时,才对双向链表的的链接顺序进行更改。