hadoop高可用集群搭建
Hadoop HA 集群搭建
文章目录
- Hadoop HA 集群搭建
- 1.hadoop基础集群环境准备(1-10步)
- 2.ZooKeeper集群搭建(1-7步)
- 3.hadoop分布式集群安装(1-3步)
- 4.修改hadoop配置文件
- 4.1修改hadoop-env.sh
- 4.2修改core-site.xml
- 4.3修改hdfs-site.xml
- 4.4修改mapred-site.xml
- 4.5修改yarn-site.xml
- 4.6增加slaves
- 5.远程发送安装包
- 6.远程发送配置文件
- 7.集群初始化操作
- 7.1启动zookeeper服务
- 7.2启动journalnode
- 7.3格式化namenode
- 7.4发送元数据
- 7.5格式化zkfc
- 7.6启动
- 配置成功!
集群规划:
| HDFS | YARN | zk | |
|---|---|---|---|
| hadoop01 | namenode+zkfc+journalnode+datanode | nodemanager+resourcemanager | QuorumPeerMain |
| hadoop02 | namenode+zkfc+journalnode+datanode | nodemanager | QuorumPeerMain |
| hadoop03 | journalnode+datanode | nodemanager+resourcemanager | QuorumPeerMain |
1.hadoop基础集群环境准备(1-10步)
2.ZooKeeper集群搭建(1-7步)
3.hadoop分布式集群安装(1-3步)
4.修改hadoop配置文件
进入到hadoop配置文件目录
cd /home/hadoop/apps/hadoop-2.7.6/etc/hadoop
4.1修改hadoop-env.sh
改一下JAVA_HOME
export JAVA_HOME=/home/hadoop/apps/jdk1.8.0_73

- 后面的文件都是将所有内容复制到configuration标签中
4.2修改core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://bd1906/value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/data/hadoopdata/value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181value>
property>
4.3修改hdfs-site.xml
- data的存储位置可以根据实际情况来修改一下
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.nameservicesname>
<value>bd1906value>
property>
<property>
<name>dfs.ha.namenodes.bd1906name>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.bd1906.nn1name>
<value>hadoop01:8020value>
property>
<property>
<name>dfs.namenode.http-address.bd1906.nn1name>
<value>hadoop01:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.bd1906.nn2name>
<value>hadoop02:8020value>
property>
<property>
<name>dfs.namenode.http-address.bd1906.nn2name>
<value>hadoop02:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/bd1906value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/home/hadoop/data/hadoopdata/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.bd1906name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
4.4修改mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop02:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop02:19888value>
property>
4.5修改yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yarn_bd1906value>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop01value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop03value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>86400value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
4.6增加slaves
vi slaves
加入
hadoop01
hadoop02
hadoop03
5.远程发送安装包
- 先切换到有hadoop-2.7.6文件夹的目录
cd /home/hadoop/apps
发送
scp -r hadoop-2.7.6 hadoop02:/home/hadoop/apps/
scp -r hadoop-2.7.6 hadoop03:/home/hadoop/apps/
6.远程发送配置文件
sudo scp /etc/profile hadoop02:/etc/
sudo scp /etc/profile hadoop03:/etc/
三台机器同时执行
source /etc/profile
hadoop version
7.集群初始化操作
- 必须按照步骤一步一步的来
- 每一步都要成功
7.1启动zookeeper服务
三台机器都要启动
zkServer.sh start
7.2启动journalnode
三台机器都要启动
hadoop-daemon.sh start journalnode
7.3格式化namenode
在hadoop01(任意一个namenode节点)中,看到如图所示的successfully再继续往下
hadoop namenode -format

7.4发送元数据
将hadoop1的元数据发送到hadoop02中
scp -r /home/hadoop/data/hadoopdata/dfs hadoop02:/home/hadoop/data/hadoopdata
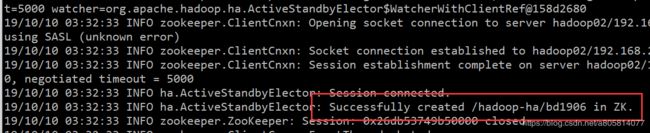
7.5格式化zkfc
在hadoop01(任意一个namenode节点)中,看到如图所示的successfully再继续往下
hdfs zkfc -formatZK
7.6启动
启动hdfs(任意节点)
start-dfs.sh
启动yarn(在hadoop01)
start-yarn.sh
在另一个节点启动resourcemanager(hadoop03)
yarn-daemon.sh start resourcemanager
最后查看一下进程
jps
