对似然函数感兴趣的读者,请参阅“驯估学”(上)
建模图像,分布若何?
很多方法可以参数化图像。例如,3D场景投影(渲染)为2D可以表示图像。或者,将图像参数化为向量化的草图(如SVG图形)或拉普拉斯金字塔,甚至是机械臂的电机扭矩所途径的轨迹。简单起见,研究人员通常将图像的似然函数,建立在RGB像素上的联合分布上。RGB是一种通用数字格式,已被证明能够有效地捕获可见电磁波谱。
每个RGB像素由uint8格式的无符号整数编码,有256个可能的值。因此,一幅具有3072个像素的图像,辅之以256个可能值,组合成个可能的存在状态。由于这个数量是有限的,我们【在理论上】就可以使用一个的骰子来表示一幅图像。然而这个数字太大了,无法在内存中存储。哪怕只有3个uint8编码的像素,联合建模又可能的类别,(对于即使是现代计算机来说也)是极为繁重的任务了。为了使计算易处理,我们必须将整个图像的可能性“分解”为条件独立的像素分布的组合。一种简单的因子分解方法如下,使每个像素的概率彼此独立:
这也称为平均场解码器(请参阅此注释,其中名称来自“均值 - 场”)。每个像素都具有易处理的密度函数或质量函数。
另一种选择是令像素似然具有自回归性,其中每个条件分布具有易处理的密度函数或质量函数。
我们需要考虑如何为上式中每个条件分布建模。以下是一些常见的做法,以及使用过这些做法的文章:
- 1.每个通道都是伯努利分布(DRAW)
- 2.每个通道都是256个类别的分类分布(PixelRNN,Image Transformer)
- 3.实数化数据的连续概率密度(Real-NVP)
- 4.离散逻辑斯蒂混合分布(PixelCNN++,Image Transformer)
像素值作为伯努利分布的输出概率
【注:“输出概率”或“发射概率”,在随机过程中,与“转移概率”相对。“输出概率”是当下时刻每个状态的可能性,“转移概率”是对于某状态、其转移到其他状态的可能性。在本文中,输出概率指伯努利分布的参数,即一次伯努利实验正面朝上的可能性。】
在调试可能性模型时,先在MNIST、FashionMNIST、NotMNIST数据集上实验是不错的选择【, 因为】:
- 这些数据集可以完全存储在计算机RAM中;
- 它们不需要大量的网络架构调整(你可以只专注于算法方面);
- 在这些数据集上训练较小的生成模型,只需要普通的硬件设施,例如缺少GPU的笔记本电脑。
选择伯努利随机变量建模像素的条件似然是很常见的做法。 对于像素值只可能为0或1(正面还是反面)的二值化数据,伯努利分布就够用了。

但是,MNIST和几个类似的数据库,往往被编码为[0,1]范围内的浮点值。256个整数被归一化为位于[0,1]之间的小数。这就产生了一个数字表示问题,因为伯努利分布不能在0到1之间采样!
对于在非二值化MNIST上训练的论文,我们须将编码值解释为相应伯努利变量的输出概率。如果我们看到像素值为0.9,则实际上表示该像素为1的伯努利似然参数是0.9,而不是样本自己的采样值是0.9。 优化目标是最小化预测概率分布的输出概率(由一个标量参数控制)与数据中固有的输出概率之间的交叉熵。 两个伯努利的交叉熵用输出概率可写成:
根据本文前半部分的结论,最小化这种交叉熵会等价于最大化似然!这些玩具图像数据集的平均对数似然(相对熵)通常以nat为单位报告在论文中。
DRAW论文(Gregor等人2015)将这一想法扩展到每通道颜色的建模。 然而,将彩色像素数据解释为输出概率存在严重的缺点。 【不加任何修正地使用伯努利分布的话,】当我们从生成模型中进行采样时,我们会得到杂乱、布满斑点的图像,而不是看起来像自然的连贯图像。 下面这段Python代码,可以重现这个问题:
import tensorflow_datasets as tfds
import numpy as np
import matplotlib.pyplot as plt
builder = tfds.builder("cifar10")
builder.download_and_prepare()
datasets = builder.as_dataset()
np_datasets = tfds.as_numpy(datasets)
img = next(np_datasets['train'])['image']
sample = np.random.binomial(1,p=img.astype(np.float32)/256)
fig, arr = plt.subplots(1, 2)
arr[0].imshow(img)
arr[1].imshow((sample*255).astype(np.uint8))
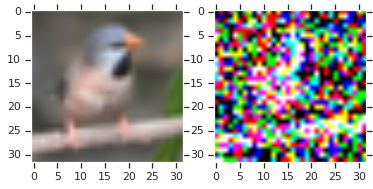
将像素值解释为“输出概率”会产生不合实际的样本。这样做虽然对于手写数字和小数据库适用,但是不适用于更大规模的自然图像。使用伯努利解码器的论文通常会显示输出概率(例如在重建或插补任务中)而不是实际样本。
像素值作为类别分布
较大的彩色图像数据集(SVHN,CIFAR10,CelebA,ImageNet)是以8位RGB格式编码的(每个通道是一个uint8整数,其值的范围为0到255,包括0和255)。
我们可以尝试在图像中实际uint8像素值上对分布进行建模,而不是将它们的像素值解释为伯努利输出概率。 最简单的选择之一是256类的类别分布【离散的随机变量,在有限多(K个)可能的类别中,依照各个类别具有的概率,落在其中某个类别上,所形成的分布】。

对于彩色图像,通常报告各像素以2为底的对数(比特)为单位的交叉熵,而不是以e为底的对数。如果测试集的图像均为3072像素,平均似然的交叉熵(单位nats)为,“每像素比特数”为。
这个度量受到我们前面讨论的启发,可类比于“平均似然压缩比”:对于通常使用8位编码的像素,我们可以使用生成式模型,设计一种无损编码方案(编码的平均长度恰好等于熵),将整个数据集压缩到平均像素位长为3【】。
在撰写本文时,Cifar10数据集上训练的稀疏变换器(Sparse Transformers)的最佳生成式模型,测试集上达到了每像素2.80比特的似然值。作为比较方案,PNG和WebP(广泛使用的无损图像压缩算法)分别在Cifar10图像上达到约5.87和4.61比特的水平(如果不计算像标题和CRC校验和那样的额外字节,PNG格式可低至5.72比特/像素【bpp, bits per pixel】)。
这个结果令我们欢欣鼓舞,这预示着利用机器学习我们可以设计出比现有压缩方案更好的、对内容有所感知、编码又最短的方案。高效的无损压缩可用于改进哈希算法,使下载速度更快、改善缩放响应。最重要的是,所有这些技术,今天都触手可得。
像素值作为“随机实数化”的连续密度分布
如果我们希望通过优化连续密度模型(例如高斯混合模型),来最大化离散数据的对数似然,可能导致解的“退化”(degeneration)现象,最终得到模型给每个可能的离散值{0,...,255}分配相同的可能性。 即使使用了无限充足的数据来训练,该模型也可以通过简单地“挤压”尖峰,收窄分布,来实现任意高的似然。
【从驯估学(上)得到:
如果取离散值,则当在离散值上等于,其余各处为0时,达到理论上的最小值。示意图在下方左图。】
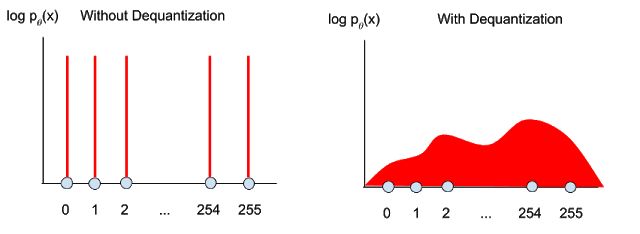
为了解决这个问题,常见的做法是将噪声添加到整数像素值,来对数据进行“实数化”(De-Quantization)【译者按:通行译法是“反量化”或“解量化”,但我觉得“实数化”更容易理解】。 这个操作写为,其中来自均匀分布。据我所知,第一篇在密度建模中使用随机实数化的文章是 Uria等人的工作(2013年),奠基了 Dinh等人在2014年和 Salimans等人在2017的工作,以及建立在这三个工作之上的其他工作,从此随机实数化成为实践中的常见做法。
离散模型在一个个区间内分配概率质量(probability mass),而连续模型则【依据密度函数在区间的每个点上】分配密度。令的和分别表示真实数据分布的离散概率质量和连续密度,并令的和代表模型对二者的估计。 我们将在下面推导出,依据实数化后的数据,优化其连续似然模型的密度函数,可以得到优化真实数据的离散概率质量模型的下界。【原文符号写错了。】
将密度函数在区间上积分,可以得到密度函数的总质量:
我们从真实数据分布中采样,采样噪声样本,得到。模型的目标是最大化下式中的似然函数:
根据期望的定义:
展开被积函数:
【,因为只能取离散值,】
根据Cauchy-Schwarz不等式:
代入密度函数的总质量:
根据Jensen不等式:
代入密度函数的总质量:
最近的一篇论文Flow ++中提出,使用学习的实数化随机变量,可以改善变分上界的紧致性。直观理解,单个重要性采样的导致的噪声方差,将小于均匀采样在积分上导致的噪声方差【,而较低的噪声方差将是上限紧致的关键因素】。由于不同架构选择了迥异的实数化方案,所以这一系列工作之间不能以控制变量的方式来公平比较。
【变分法形式化大致如下:
】
【为了公平】比较Flow ++和均匀采样的实数化框架的生成模型,一种方法是允许研究人员在训练时使用(他们喜欢的)任何一种变分下界,但是在模型评估时将似然评估的值,统一换算成多个样本的紧密下界。直观理解,当整合了更多样本后,我们的估计模型可以更好地逼近相应离散模型的真实对数似然。
例如,我们可以报告从固定的采样得到的实数化分布的多样本下界,就像VAE文献中通常所做的那样,给出的多样本IWAE下界。有关VAE和IWAE变分下界的讨论超出了本教程的范围,我会在将来单独介绍。
【关于图像的讨论还未结束,另外对标准化流也将在“驯估学”(下)中继续。请接着读下去,加油!】