NLP重大突破?一文读懂XLNet“屠榜”背后的原理
作者 | 李理
原文链接:https://fancyerii.github.io/2019/06/30/xlnet-theory/
本文介绍XLNet的基本原理,读者阅读前需要了解BERT等相关模型,不熟悉的读者建议学习BERT课程。
语言模型和BERT各自的优缺点
在论文里作者使用了一些术语,比如自回归(Autoregressive, AR)语言模型和自编码(autoencoding)模型等,这可能让不熟悉的读者感到困惑,因此我们先简单的解释一下。自回归是时间序列分析或者信号处理领域喜欢用的一个术语,我们这里理解成语言模型就好了:一个句子的生成过程如下:首先根据概率分布生成第一个词,然后根据第一个词生成第二个词,然后根据前两个词生成第三个词,……,直到生成整个句子。而所谓的自编码器是一种无监督学习输入的特征的方法:我们用一个神经网络把输入(输入通常还会增加一些噪声)变成一个低维的特征,这就是编码部分,然后再用一个Decoder尝试把特征恢复成原始的信号。我们可以把BERT看成一种AutoEncoder,它通过Mask改变了部分Token,然后试图通过其上下文的其它Token来恢复这些被Mask的Token。如果读者不太理解或者喜欢这两个jargon,忽略就行了。
给定文本序列 x = [ x 1 , . . . , x T ] \mathbf{x}=[x_1,...,x_T] x=[x1,...,xT],语言模型的目标是调整参数使得训练数据上的似然函数最大:
m a x θ l o g p θ ( x ) = ∑ t = 1 T l o g p θ ( x t ∣ x < t ) = ∑ t = 1 T l o g e x p ( h θ ( x 1 : t − 1 ) T e ( x t ) ) ∑ x ′ e x p ( h θ ( x 1 : t − 1 ) T e ( x ′ ) ) 等式(1) \underset{\theta}{max}\; log p_\theta(\mathbf{x})=\sum_{t=1}^T log p_\theta(x_t \vert \mathbf{x}_{<t})=\sum_{t=1}^T log \frac{exp(h_\theta(\mathbf{x}_{1:t-1})^T e(x_t))}{\sum_{x'}exp(h_\theta(\mathbf{x}_{1:t-1})^T e(x'))} \text{ 等式(1)} θmaxlogpθ(x)=t=1∑Tlogpθ(xt∣x<t)=t=1∑Tlog∑x′exp(hθ(x1:t−1)Te(x′))exp(hθ(x1:t−1)Te(xt)) 等式(1)
记号 x < t \mathbf{x}_{<t} x<t表示t时刻之前的所有x,也就是 x 1 : t − 1 \mathbf{x}_{1:t-1} x1:t−1 。 。 。 h θ ( x 1 : t − 1 ) h_\theta(\mathbf{x}_{1:t-1}) hθ(x1:t−1) 是 R N N 或 者 T r a n s f o r m e r ( 注 : T r a n s f o r m e r 也 可 以 用 于 语 言 模 型 , 比 如 在 O p e n A I G P T ) 编 码 的 t 时 刻 之 前 的 隐 状 态 。 是RNN或者Transformer(注:Transformer也可以用于语言模型,比如在OpenAI GPT)编码的t时刻之前的隐状态。 是RNN或者Transformer(注:Transformer也可以用于语言模型,比如在OpenAIGPT)编码的t时刻之前的隐状态。e(x)$是词x的embedding。
而BERT是去噪(denoising)自编码的方法。对于序列 x \mathbf{x} x,BERT会随机挑选15%的Token变成[MASK]得到带噪声版本的 x ^ \hat{\mathbf{x}} x^。假设被Mask的原始值为 x ˉ \bar{\mathbf{x}} xˉ,那么BERT希望尽量根据上下文恢复(猜测)出原始值了,也就是:
m a x θ l o g p θ ( x ˉ ∣ x ^ ) ≈ ∑ t = 1 T m t l o g p θ ( x t ∣ x ^ ) = ∑ t = 1 T m t l o g e x p ( H θ ( x ) t T e ( x t ) ) ∑ x ′ e x p ( H θ ( x ) t T e ( x ′ ) ) 等式(2) \underset{\theta}{max}\;log p_\theta(\bar{\mathbf{x}} | \hat{\mathbf{x}}) \approx \sum_{t=1}^Tm_t log p_\theta(x_t | \hat{\mathbf{x}})=\sum_{t=1}^T m_t log \frac{exp(H_\theta(\mathbf{x})_{t}^T e(x_t))}{\sum_{x'}exp(H_\theta(\mathbf{x})_{t}^T e(x'))} \text{ 等式(2)} θmaxlogpθ(xˉ∣x^)≈t=1∑Tmtlogpθ(xt∣x^)=t=1∑Tmtlog∑x′exp(Hθ(x)tTe(x′))exp(Hθ(x)tTe(xt)) 等式(2)
上式中 m t = 1 m_t=1 mt=1表示t时刻是一个Mask,需要恢复。 H θ H_\theta Hθ是一个Transformer,它把长度为 T T T的序列 x \mathbf{x} x映射为隐状态的序列 H θ ( x ) = [ H θ ( x ) 1 , H θ ( x ) 2 , . . . , H θ ( x ) T ] H_\theta(\mathbf{x})=[H_\theta(\mathbf{x})_1, H_\theta(\mathbf{x})_2, ..., H_\theta(\mathbf{x})_T] Hθ(x)=[Hθ(x)1,Hθ(x)2,...,Hθ(x)T]。注意:前面的语言模型的RNN在t时刻只能看到之前的时刻,因此记号是 h θ ( x 1 : t − 1 ) h_\theta(\mathbf{x}_{1:t-1}) hθ(x1:t−1);而BERT的Transformer(不同与用于语言模型的Transformer)可以同时看到整个句子的所有Token,因此记号是 H θ ( x ) H_\theta(\mathbf{x}) Hθ(x)。
这两个模型的优缺点分别为:
-
独立假设
- 注意等式(2)的约等号 ≈ \approx ≈,它的意思是假设在给定 x ^ \hat{\mathbf{x}} x^的条件下被Mask的词是独立的(没有关系的),这个显然并不成立,比如"New York is a city",假设我们Mask住"New"和"York"两个词,那么给定"is a city"的条件下"New"和"York"并不独立,因为"New York"是一个实体,看到"New"则后面出现"York"的概率要比看到"Old"后面出现"York"概率要大得多。而公式(1)没有这样的独立性假设,它是严格的等号。
-
输入噪声
- BERT的在预训练时会出现特殊的[MASK],但是它在下游的fine-tuning中不会出现,这就是出现了不匹配。而语言模型不会有这个问题。
-
双向上下文
- 语言模型只能参考一个方向的上下文,而BERT可以参考双向整个句子的上下文,因此这一点BERT更好一些。关于为什么RNN只能是单向的上下文而BERT可以参考整个句子的上线,读者可以参考ELMo和OpenAI GPT的问题。
排列(Permutation)语言模型
根据上面的讨论,语言模型和BERT各有优缺点,有什么办法能构建一个模型使得同时有它们的优点并且没有它们缺点呢?
借鉴NADE(不了解的读者可以忽略,这是一种生成模型)的思路,XLNet使用了排列语言模型,它同时有它们的优点。
给定长度为T的序列 x \mathbf{x} x,总共有 T ! T! T!种排列方法,也就对应 T ! T! T!种链式分解方法。比如假设 x = x 1 x 2 x 3 \mathbf{x}=x_1x_2x_3 x=x1x2x3,那么总共用 3 ! = 6 3!=6 3!=6种分解方法:
p ( x ) = p ( x 1 ) p ( x 2 ∣ x 1 ) p ( x 3 ∣ x 1 x 2 ) ⇒ 1 → 2 → 3 p ( x ) = p ( x 1 ) p ( x 2 ∣ x 1 x 3 ) p ( x 3 ∣ x 1 ) ⇒ 1 → 3 → 2 p ( x ) = p ( x 1 ∣ x 2 ) p ( x 2 ) p ( x 3 ∣ x 1 x 2 ) ⇒ 2 → 1 → 3 p ( x ) = p ( x 1 ∣ x 2 x 3 ) p ( x 2 ) p ( x 3 ∣ x 2 ) ⇒ 2 → 3 → 1 p ( x ) = p ( x 1 ∣ x 3 ) p ( x 2 ∣ x 1 x 3 ) p ( x 3 ) ⇒ 3 → 1 → 2 p(\mathbf{x})=p(x_1)p(x_2|x_1)p(x_3|x_1x_2) \Rightarrow 1 \rightarrow 2 \rightarrow 3 \\ p(\mathbf{x})=p(x_1)p(x_2|x_1x_3)p(x_3|x_1) \Rightarrow 1 \rightarrow 3 \rightarrow 2 \\ p(\mathbf{x})=p(x_1|x_2)p(x_2)p(x_3|x_1x_2) \Rightarrow 2 \rightarrow 1 \rightarrow 3 \\ p(\mathbf{x})=p(x_1|x_2x_3)p(x_2)p(x_3|x_2) \Rightarrow 2 \rightarrow 3 \rightarrow 1 \\ p(\mathbf{x})=p(x_1|x_3)p(x_2|x_1x_3)p(x_3) \Rightarrow 3 \rightarrow 1 \rightarrow 2 p(x)=p(x1)p(x2∣x1)p(x3∣x1x2)⇒1→2→3p(x)=p(x1)p(x2∣x1x3)p(x3∣x1)⇒1→3→2p(x)=p(x1∣x2)p(x2)p(x3∣x1x2)⇒2→1→3p(x)=p(x1∣x2x3)p(x2)p(x3∣x2)⇒2→3→1p(x)=p(x1∣x3)p(x2∣x1x3)p(x3)⇒3→1→2
注意 p ( x 2 ∣ x 1 x 3 ) p(x_2 \vert x_1x_3) p(x2∣x1x3)指的是第一个词是 x 1 x_1 x1并且第三个词是 x 3 x_3 x3的条件下第二个词是 x 2 x_2 x2的概率,也就是说原来词的顺序是保持的。如果理解为第一个词是 x 1 x_1 x1并且第二个词是 x 3 x_3 x3的条件下第三个词是 x 2 x_2 x2,那么就不对了。
如果我们的语言模型遍历 T ! T! T!种分解方法,并且这个模型的参数是共享的,那么这个模型应该就能(必须)学习到各种上下文。普通的从左到右或者从右往左的语言模型只能学习一种方向的依赖关系,比如先"猜"一个词,然后根据第一个词"猜"第二个词,根据前两个词"猜"第三个词,……。而排列语言模型会学习各种顺序的猜测方法,比如上面的最后一个式子对应的顺序 3 → 1 → 2 3 \rightarrow 1 \rightarrow 2 3→1→2,它是先"猜"第三个词,然后根据第三个词猜测第一个词,最后根据第一个和第三个词猜测第二个词。
因此我们可以遍历 T ! T! T!种路径,然后学习语言模型的参数,但是这个计算量非常大(10!=3628800,10个词的句子就有这么多种组合)。因此实际我们只能随机的采样 T ! T! T!里的部分排列,为了用数学语言描述,我们引入几个记号。 Z T \mathcal{Z}_T ZT表示长度为T的序列的所有排列组成的集合,则 z ∈ Z T z \in \mathcal{Z}_T z∈ZT是一种排列方法。我们用 z t z_t zt表示排列的第t个元素,而 z < t z_{<t} z<t表示z的第1到第t-1个元素。
举个例子,假设T=3,那么 Z T \mathcal{Z}_T ZT共有6个元素,我们假设其中之一 z = [ 1 , 3 , 2 ] z=[1,3,2] z=[1,3,2],则 z 3 = 2 z_3=2 z3=2,而 z < 3 = [ 1 , 3 ] z_{<3}=[1,3] z<3=[1,3]。
有了上面的记号,则排列语言模型的目标是调整模型参数使得下面的似然概率最大:
m a x θ E z ∼ Z T [ ∑ t = 1 T l o g p θ ( x z t ∣ x z < t ) ] \underset{\theta}{max} \mathbb{E}_{z \sim \mathcal{Z}_T}[\sum_{t=1}^Tlog p_\theta(x_{z_t}|\mathbf{x}_{z_{<t}})] θmaxEz∼ZT[t=1∑Tlogpθ(xzt∣xz<t)]
上面的公式看起来有点复杂,细读起来其实很简单:从所有的排列中采样一种,然后根据这个排列来分解联合概率成条件概率的乘积,然后加起来。
注意:上面的模型只会遍历概率的分解顺序,并不会改变原始词的顺序。实现是通过Attention的Mask来对应不同的分解方法。比如 p ( x 1 ∣ x 3 ) p ( x 2 ∣ x 1 x 3 ) p ( x 3 ) p(x_1 \vert x_3)p(x_2 \vert x_1x_3)p(x_3) p(x1∣x3)p(x2∣x1x3)p(x3),我们可以在用Transformer编码 x 1 x_1 x1时候让它可以Attend to x 3 x_3 x3,而把 x 2 x_2 x2Mask掉;编码 x 3 x_3 x3的时候把 x 1 , x 2 x_1,x_2 x1,x2都Mask掉。

图:排列语言模型在预测 x 3 x_3 x3时不同排列的情况
比如图的左上,对应的分解方式是 3 → 2 → 4 → 1 3 \rightarrow 2 \rightarrow 4 \rightarrow 1 3→2→4→1,因此预测 x 3 x_3 x3是不能attend to任何其它词,只能根据之前的隐状态 m e m mem mem来预测。而对于左下, x 3 x_3 x3可以attend to其它3个词。
Two-Stream Self-Attention for Target-Aware Representations
没有目标(target)位置信息的问题
上面的思想很简单,但是如果我们使用标准的Transformer来实现时会有问题。我们来看一个例子。
假设输入的句子是"I like New York",并且一种排列为z=[1, 3, 4, 2],假设我们需要预测 z 3 = 4 z_3=4 z3=4,那么根据公式:
p θ ( X z 3 = x ∣ x z 1 z 2 ) = p θ ( X 4 = x ∣ x 1 x 3 ) = e x p ( e ( x ) T h θ ( x 1 x 3 ) ) ∑ x ′ e x p ( e ( x ′ ) T h θ ( x 1 x 3 ) ) p_\theta(X_{z_3}=x|x_{z_1z_2})=p_\theta(X_4=x|x_1x_3)=\frac{exp(e(x)^Th_\theta(x_1x_3))}{\sum_{x'}exp(e(x')^Th_\theta(x_1x_3))} pθ(Xz3=x∣xz1z2)=pθ(X4=x∣x1x3)=∑x′exp(e(x′)Thθ(x1x3))exp(e(x)Thθ(x1x3))
注意,我们通常用大写的X表示随机变量,比如 X 4 X_4 X4,而小写的x表示某一个具体取值,比如x,我们假设x是"York",则 p θ ( X 4 = x ) p_\theta(X_4=x) pθ(X4=x)表示第4个词是York的概率。用自然语言描述:上面的概率是第一个词是I,第3个词是New的条件下第4个词是York的概率。
另外我们再假设一种排列为z’=[1,3,2,4],我们需要预测 z 3 = 2 z_3=2 z3=2,那么:
p θ ( X z 3 = x ∣ x z 1 z 2 ) = p θ ( X 2 = x ∣ x 1 x 3 ) = e x p ( e ( x ) T h θ ( x 1 x 3 ) ) ∑ x ′ e x p ( e ( x ′ ) T h θ ( x 1 x 3 ) ) p_\theta(X_{z_3}=x|x_{z_1z_2})=p_\theta(X_2=x|x_1x_3)=\frac{exp(e(x)^Th_\theta(x_1x_3))}{\sum_{x'}exp(e(x')^Th_\theta(x_1x_3))} pθ(Xz3=x∣xz1z2)=pθ(X2=x∣x1x3)=∑x′exp(e(x′)Thθ(x1x3))exp(e(x)Thθ(x1x3))
则上面是表示是第一个词是I,第3个词是New的条件下第2个词是York的概率。我们仔细对比一下公式会发现这两个概率是相等的。但是根据经验,显然这两个概率是不同的,而且上面的那个概率大一些,因为York跟在New之后是一个城市,而"York New"是什么呢?
上面的问题的关键是模型并不知道要预测的那个词在原始序列中的位置。了解Transformer的读者可能会问:输入的位置编码在哪里呢?位置编码的信息不能起作用吗?注意:位置编码是和输入的Embedding加到一起作为输入的,因此 p θ ( X 4 = x ∣ x 1 x 3 ) p_\theta(X_4=x \vert x_1x_3) pθ(X4=x∣x1x3)里的 x 1 x_1 x1和 x 3 x_3 x3是带了位置信息的,模型(可能)知道(根据输入的向量猜测)I是第一个词,而New是第三个词,但是第四个词的向量显然这个是还不知道(知道了还要就不用预测了),因此就不可能知道它要预测的词到底是哪个位置的词,因此我们必须"显式"的告诉模型我要预测哪个位置的词。
为了后面的描述,我们再把上面的两个公式写出更加一般的形式。给定排列z,我们需要计算 p θ ( X z t ∣ x z < t = x ) p_\theta(X_{z_t} \vert \mathbf{x}_{z_{<t}}=x) pθ(Xzt∣xz<t=x),如果我们使用普通的Transformer,那么计算公式为:
p θ ( X z t = x ∣ x z < t ) = e x p ( e ( x ) T h θ ( x z < t ) ) ∑ x ′ e x p ( e ( x ′ ) T h θ ( x z < t ) ) p_\theta(X_{z_t}=x \vert \mathbf{x}_{z_{<t}})=\frac{exp(e(x)^Th_\theta(\mathbf{x}_{z_{<t}}))}{\sum_{x'}exp(e(x')^Th_\theta(\mathbf{x}_{z_{<t}}))} pθ(Xzt=x∣xz<t)=∑x′exp(e(x′)Thθ(xz<t))exp(e(x)Thθ(xz<t))
根据前面的讨论,我们知道问题的关键是模型并不知道要预测的到底是哪个位置的词,为了解决这个问题,我们把预测的位置 z t z_t zt放到模型里:
p θ ( X z t = x ∣ x z < t ) = e x p ( e ( x ) T g θ ( x z < t , z t ) ) ∑ x ′ e x p ( e ( x ′ ) T g θ ( x z < t , z t ) ) p_\theta(X_{z_t}=x \vert \mathbf{x}_{z_{<t}})=\frac{exp(e(x)^Tg_\theta(\mathbf{x}_{z_{<t}}, z_t))}{\sum_{x'}exp(e(x')^Tg_\theta(\mathbf{x}_{z_{<t}}, z_t))} pθ(Xzt=x∣xz<t)=∑x′exp(e(x′)Tgθ(xz<t,zt))exp(e(x)Tgθ(xz<t,zt))
上式中 g θ ( x z < t , z t ) g_\theta(\mathbf{x}_{z_{<t}}, z_t) gθ(xz<t,zt)表示这是一个新的模型g,并且它的参数除了之前的词 x z < t \mathbf{x}_{z_{<t}} xz<t,还有要预测的词的位置 z t z_t zt。
Two-Stream Self-Attention
接下来的问题是用什么模型来表示 g θ ( x z < t , z t ) g_\theta(\mathbf{x}_{z_{<t}}, z_t) gθ(xz<t,zt)。当然有很多种可选的函数(模型),我们这里通过位置 z t z_t zt来从context x z < t \mathbf{x}_{z_{<t}} xz<t里通过Attention机制提取需要的信息来预测这个位置的词。那么它需要满足如下两点要求:
-
为了预测 x z t \mathbf{x}_{z_t} xzt, g θ ( x z < t , z t ) g_\theta(\mathbf{x}_{z_{<t}}, z_t) gθ(xz<t,zt)只能使用位置信息 z t z_t zt而不能使用 x z t \mathbf{x}_{z_t} xzt。这是显然的:你预测一个词当然不能知道要预测的是什么词。
-
为了预测 z t z_t zt之后的词, g θ ( x z < t , z t ) g_\theta(\mathbf{x}_{z_{<t}}, z_t) gθ(xz<t,zt)必须编码了 x z t x_{z_t} xzt的信息(语义)。
但是上面两点要求对于普通的Transformer来说是矛盾的无法满足的。因为上面是理解为什么要搞出两个Stream的关键,所以我这里再啰嗦一点举一个例子。
假设输入的句子还是"I like New York",并且一种排列为z=[1, 3, 4, 2],假设t=2,我们现在是在计算 g θ ( x z < t , z t ) g_\theta(\mathbf{x}_{z_{<t}}, z_t) gθ(xz<t,zt),也就是给定第一个位置的词为I预测第三个位置为New的概率,显然我们不能使用New本身的而只能根据第一个位置的I来预测。假设我们非常幸运的找到了一很好的函数g,它可以能够比较好的预测这个概率 g θ ( x 1 , z 2 ) g_\theta(x_1, z_2) gθ(x1,z2)。现在我们又需要计算t=3,也就是根据 g θ ( x 1 , z 2 ) g_\theta(x_1, z_2) gθ(x1,z2)和 z t z_t zt来预测York,显然知道第三个位置是New对于预测第四个位置是York会非常有帮助,但是 g θ ( x 1 , z 2 ) g_\theta(x_1, z_2) gθ(x1,z2)并没有New这个词的信息。读者可能会问:你不是说g可以比较好的根据第一个词I预测第三个词New的概率吗?这里有两点:I后面出现New的概率并不高;在预测York时我们是知道第三个位置是New的,只不过模型的限制我们没有重复利用这信息。
为了解决这个问题,论文引入了两个Stream,也就是两个隐状态:
-
内容隐状态 h θ ( x z < t ) h_\theta(\mathbf{x}_{z_{<t}}) hθ(xz<t),简写为 h z t h_{z_t} hzt,它就会标准的Transformer一样,既编码上下文(context)也编码 x z t x_{z_t} xzt的内容。
-
查询隐状态 g θ ( x z < t , z t ) g_\theta(\mathbf{x}_{z_{<t}}, z_t) gθ(xz<t,zt),简写为 g z t g_{z_t} gzt,它只编码上下文和要预测的位置 z t z_t zt,但是不包含 x z t x_{z_t} xzt。
下面我们介绍一下计算过程。我们首先把查询隐状态 g i ( 0 ) g_i^{(0)} gi(0)初始化为一个变量w,把内容隐状态 h i ( 0 ) h_i^{(0)} hi(0)初始化为词的Embedding e ( x i ) e(x_i) e(xi)。这里的上标0表示第0层(不存在的层,用于计算第一层)。因为内容隐状态可以编码当前词,因此初始化为词的Embedding是比较合适的。
接着从m=1一直到第M层,我们逐层计算:
 上面两个流分别使用自己的Query向量 g z t g_{z_t} gzt和 h z t h_{z_t} hzt;但是Key和Value向量都是用的h,因为h是内容。但是注意Query流不能访问 z t z_t zt的内容,因此KV是 h z < t ( m − 1 ) h_{z_{<t}}^{(m-1)} hz<t(m−1),这里用的是小于号(<)表示不包括t时刻的content。而Content流的KV是 h z ≤ t ( m − 1 ) h_{z_{\le t}}^{(m-1)} hz≤t(m−1),它包含 x z t x_{z_t} xzt。
上面两个流分别使用自己的Query向量 g z t g_{z_t} gzt和 h z t h_{z_t} hzt;但是Key和Value向量都是用的h,因为h是内容。但是注意Query流不能访问 z t z_t zt的内容,因此KV是 h z < t ( m − 1 ) h_{z_{<t}}^{(m-1)} hz<t(m−1),这里用的是小于号(<)表示不包括t时刻的content。而Content流的KV是 h z ≤ t ( m − 1 ) h_{z_{\le t}}^{(m-1)} hz≤t(m−1),它包含 x z t x_{z_t} xzt。
上面的梯度更新和标准的self-attention是一样的。在fine-tuning的时候,我们可以丢弃掉Query流而只用Content流。最后在计算公式的时候我们可以用最上面一层的Query向量 g z t ( M ) g_{z_t}^{(M)} gzt(M)。
下面我们通过下图来直观的了解计算过程。

图:Two Stream排列模型的计算过程
图的左上是Content流Attention的计算,假设排列为 3 → 2 → 4 → 1 3 \rightarrow 2 \rightarrow 4 \rightarrow 1 3→2→4→1,并且我们现在预测第1个位置的词的概率。根据排列,我们可以参考所有4个词的信息,因此 K V = [ h 1 ( 0 ) , h 2 ( 0 ) , h 3 ( 0 ) , h 4 ( 0 ) ] KV=[h_1^{(0)},h_2^{(0)},h_3^{(0)},h_4^{(0)}] KV=[h1(0),h2(0),h3(0),h4(0)],而 Q = h 1 ( 0 ) Q=h_1^{(0)} Q=h1(0)。
左下是Query流的计算,因为不能参考自己的内容,因此 K V = [ h 2 ( 0 ) , h 3 ( 0 ) , h 4 ( 0 ) ] KV=[h_2^{(0)},h_3^{(0)},h_4^{(0)}] KV=[h2(0),h3(0),h4(0)],而 Q = g 1 ( 0 ) Q=g_1^{(0)} Q=g1(0)。
而图的右边是完整的计算过程,我们从下往上看,首先h和g分别被初始化为 e ( x i ) e(x_i) e(xi)和W,然后Content Mask和Query Mask计算第一层的输出 h ( 1 ) h^{(1)} h(1)和 g ( 1 ) g^{(1)} g(1),然后计算第二层……。注意最右边的Content Mask和Query Mask,我们先看Content Mask。它的第一行全是红点,表示第一个词可以attend to所有的词(根据 3 → 2 → 4 → 1 3 \rightarrow 2 \rightarrow 4 \rightarrow 1 3→2→4→1),第二个词可以attend to它自己和第三个词,……。而Query Mask和Content Mask的区别就是不能attend to自己,因此对角线都是白点。
部分预测
虽然排列语言模型有很多有点,但是它的计算量很大(排列很多),很难优化。因此我们只预测一个句子后面的一些词,为什么不预测前面的词呢?因为前面的词的上下文比较少,上下文信息相对较少。比如句子"I like New York"。预测I的时候没有任何上下文,因此可能的选择很多。而到最后一个词York的时候,如果New已经知道了,那么York的概率就非常大了。
因此我们把一个排列 z z z分成两个子序列 z ≤ c z_{\le c} z≤c和 z > c z_{>c} z>c,分别叫做non-target序列和target序列,其中c是切分点。我们会使用一个超参数K,表示1/K的Token会被预测,因此根据公式:
∣ z ∣ − c ∣ z ∣ = 1 K \frac{|z|-c}{|z|}=\frac{1}{K} ∣z∣∣z∣−c=K1
可以计算出 K ≈ ∣ z ∣ − c ∣ z ∣ K \approx \frac{\vert z \vert -c}{\vert z \vert} K≈∣z∣∣z∣−c,约等于的原因是因为K是整数。前面c个不用预测的Token,我们不需要计算其Query流,从而可以节省计算时间。
融入Transformer-XL的优点
到此为止,XLNet的核心思想已经比较清楚了:还是使用语言模型,但是为了解决双向上下文的问题,引入了排列语言模型。排列语言模型在预测时需要target的位置信息,因此通过引入Two-Stream,Content流编码到当前时刻的所有内容,而Query流只能参考之前的历史以及当前要预测的位置。最后为了解决计算量过大的问题,对于一个句子,我们只预测后面的1/K的词。
接下来XLNet借鉴了Transformer-XL的优点,它对于很长的上下文的处理是要由于传统的Transformer的。我们这里只是简单的介绍Transformer-XL,有兴趣的读者可以参考Transformer-XL论文。
Transformer-XL思想简介
首先Transformer-XL是一个语言模型,也就是改进Transformer来根据历史的词预测下一个词。它不同于BERT的Mask语言模型问题,也不同于XLNet使用的排列语言模型。我们知道OpenAI GPT就是使用Transformer来进行语言模型的建模。因为Transformer要求输入是定长的词序列(不像RNN可以处理变成的输入序列),太长的截断,不足的padding,这样我们把一个语料库的字符串序列切分成固定长度的segments。它有下面一些问题:
-
由于定长的要求,我们不可能让输入太长。因此虽然Self-Attention机制虽然不太受长度的约束,但是Transformer的语言模型实际能够考虑的上下文就是输入的长度。
-
因为我们在序列语言模型的时候通常很难准确的分句(或者有时候一个句子比最大长度还长),所以一个Segment很可能不是一个完整的句子(甚至它是从某个句子的中间部分开始的),这样前面的几个词就很难预测(给人一个没头没脑的句子也很难预测),因为语言模型是自回归的,一步错步步错。这就是所谓的context fragmentation的问题。
-
预测的性能问题,假设我们要使用Transformer语言模型来计算一个句子的概率(而不是用于下游的任务),那么我们首先要计算 P ( x 1 ) P(x_1) P(x1),然后计算 P ( x 2 ∣ x 1 ) P(x_2 \vert x_1) P(x2∣x1),……,一直计算到 P ( x T ∣ x 1 , . . . , x T − 1 ) P(x_T \vert x_1, ..., x_{T-1}) P(xT∣x1,...,xT−1)。每个时刻都需要用Transformer计算一次,而不能像RNN那样之前的把历史都编码到一个context向量里。

图:普通的Transformer语言模型的训练和预测
上图做是普通的Transformer语言模型的训练过程。假设Segment的长度为4,如图中我标示的:根据红色的路径,虽然 x 8 x_8 x8的最上层是受 x 1 x_1 x1影响的,但是由于固定的segment,x_8无法利用 x 1 x_1 x1的信息。而预测的时候的上下文也是固定的4,比如预测 x 6 x_6 x6时我们需要根据 [ x 2 , x 3 , x 4 , x 5 ] [x_2,x_3,x_4,x_5] [x2,x3,x4,x5]来计算,接着把预测的结果作为下一个时刻的输入。接着预测 x 7 x_7 x7的时候需要根据 [ x 3 , x 4 , x 5 , x 6 ] [x_3,x_4,x_5,x_6] [x3,x4,x5,x6]完全进行重新的计算。之前的计算结果一点也用不上。
而Transformer-XL如下图所示:

图:Transformer-XL的训练和预测
我们会把之前一个固定长度的词序列每一层的输出都放到一个cache里,比如把 x 1 , . . . , x 4 x_1,...,x_4 x1,...,x4的计算结果都存起来,那么在训练第二个Segment [ x 5 , . . . , x 8 ] [x_5,...,x_8] [x5,...,x8]的时候就可以让Self-Attention机制参考 [ x 1 , . . . , x 4 ] [x_1,...,x_4] [x1,...,x4]的信息了。当然在反向计算梯度的时候,cache里的内容是不会参与梯度的计算的。而在预测的时候,比如右图我们在计算 x 12 x_{12} x12作为输入的时候,之前那些 [ x 11 , x 10 , . . . ] [x_{11},x_{10},...] [x11,x10,...]都不需要重新计算。而普通的的Transformer是需要的,为什么呢?我们仔细看一下上图,在t=12的时候, x 11 x_{11} x11可以attend to [ x 11 , . . . , x 9 ] [x_{11},...,x_{9}] [x11,...,x9](而 x 8 x_8 x8被截掉了),而在t=11的时候可以attend to [ x 11 , . . . , x 8 ] [x_{11},...,x_{8}] [x11,...,x8],因此这两个计算结果是不同的,需要重新计算。
Segment基本的状态重用
根据之前的思路,我们用cache缓存部分历史的状态。虽然计算梯度的时候只使用本segment的信息,但是在forward的时候其实是用到了之前的segment(甚至很久以前的segment,只有cache的空间足够大)的信息,因此它又有点类似于RNN。下面我们形式化的用数学语言来描述状态重用的过程。假设两个相邻的segment为 s τ = [ x τ , 1 , x τ , 2 , . . . , x τ , L ] s_\tau=[x_{\tau,1}, x_{\tau,2}, ..., x_{\tau,L}] sτ=[xτ,1,xτ,2,...,xτ,L]和 s τ + 1 = [ x τ + 1 , 1 , x τ + 1 , 2 , . . . , x τ + 1 , L ] s_{\tau+1}=[x_{\tau+1,1}, x_{\tau+1,2}, ..., x_{\tau+1,L}] sτ+1=[xτ+1,1,xτ+1,2,...,xτ+1,L]。假设segment s τ s_\tau sτ的第n层的隐状态序列为 h τ n ∈ R L × d h_\tau^n \in R^{L \times d} hτn∈RL×d,那么计算segment s τ + 1 s_{\tau+1} sτ+1的隐状态的过程如下:

上式中 S G ( h τ n − 1 ) SG(h_{\tau}^{n-1}) SG(hτn−1)函数代表 h τ n − 1 h_{\tau}^{n-1} hτn−1不参与梯度的计算。我们看到,计算Query的时候只是用本segment的信息 h τ + 1 n − 1 h_{\tau+1}^{n-1} hτ+1n−1,而计算Key和Value的时候同时使用了 h τ + 1 n − 1 h_{\tau+1}^{n-1} hτ+1n−1和 h τ n − 1 h_{\tau}^{n-1} hτn−1(实际用的是 h ~ τ + 1 n − 1 \tilde{h}_{\tau+1}^{n-1} h~τ+1n−1)。
Transformer-XL的相对位置编码
Transformer-XL不能像BERT那样使用绝对位置编码,下面我们来分析一些为什么不行。
和前面一样,假设两个相邻的segment为 s τ = [ x τ , 1 , x τ , 2 , . . . , x τ , L ] s_\tau=[x_{\tau,1}, x_{\tau,2}, ..., x_{\tau,L}] sτ=[xτ,1,xτ,2,...,xτ,L]和 s τ + 1 = [ x τ + 1 , 1 , x τ + 1 , 2 , . . . , x τ + 1 , L ] s_{\tau+1}=[x_{\tau+1,1}, x_{\tau+1,2}, ..., x_{\tau+1,L}] sτ+1=[xτ+1,1,xτ+1,2,...,xτ+1,L]。假设segment s τ s_\tau sτ的第n层的隐状态序列为 h τ n ∈ R L × d h_\tau^n \in R^{L \times d} hτn∈RL×d,那么计算公式如下:
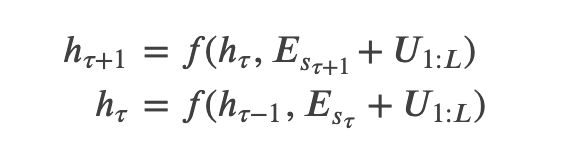
上式中 E s τ E_{s_{\tau}} Esτ是segment的每一个词的Embedding的序列。我们发现 E s τ E_{s_{\tau}} Esτ和 E s τ + 1 E_{s_{\tau+1}} Esτ+1都是加了 U 1 : L U_{1:L} U1:L,因此模型无法通过向量判断它到底是当前segment的第i个位置还是前一个Segment的第i个位置。注:不熟悉位置编码的读者需要参考Transformer图解。它的基本思想就是给每一个绝对位置一个Embedding,因此模型可以通过这个Embedding猜测它在编码哪个位置的信息,也可以学到某个位置用什么向量来表示更好。
因此Transformer-XL必须使用相对位置编码,它使用了和原始的Transformer使用正弦函数不同的方法。原始的Transformer是把位置信息embedding进去直接加到输入里,而Transformer-XL是在Attention计算的时候利用当前Query和Key的相对位置。因为XLNet使用的是正弦函数的位置编码,所以这里就不介绍Transformer-XL的位置编码方法了,感兴趣的读者可以参考Transformer-XL论文。
在XLNet里融入Transformer-XL的思想
首先XLNet借鉴了Transoformer-XL的相对位置编码的思想,这个和它基本一样,因此这里不再介绍。另外一点就是cache前一个segment的隐状态。我们假设有两个从原始序列 s \mathbf{s} s里抽取的两个连续Segment, x ~ = s 1 : T \tilde{x}=s_{1:T} x~=s1:T和 x = s T + 1 : 2 T x=s_{T+1:2T} x=sT+1:2T。同时假设 z ~ \tilde{z} z~和 z z z分别是[1,…,T]和[T+1,…,2T]的一个排列。然后根据排列 z ~ \tilde{z} z~的概率分解我们首先计算第一个segment,并且把Content流的隐状态 h ~ ( m ) \tilde{h}^{(m)} h~(m) cache下来,这里 h ~ ( m ) \tilde{h}^{(m)} h~(m)是第m层的Content流的隐状态。那么计算第二个Segment的Content流的方法如下:
h z t ( m ) ← Attention ( Q = h z t ( m − 1 ) , K V = [ h ~ ( m − 1 ) , h z ≤ t ( m − 1 ) ] ; θ ) h_{z_t}^{(m)} \leftarrow \text{Attention} (Q=h_{z_t}^{(m-1)},KV=[\tilde{h}^{(m-1)},h_{z \le t}^{(m-1)}];\theta) hzt(m)←Attention(Q=hzt(m−1),KV=[h~(m−1),hz≤t(m−1)];θ)
上式用自然语言描述就是:为了计算 z t z_t zt第m层的隐状态,我们使用Attention机制,其中Query是上一次的隐状态 h z t ( m − 1 ) h_{z_t}^{(m-1)} hzt(m−1),而Key和Value除了 z 1 , . . . , z t z_1,...,z_t z1,...,zt第m-1层的隐状态,也需要attend to cached上一个segment的所有第m-1层的隐状态。
在计算第二个segment时,我们只需要知道隐状态 h ~ ( m ) \tilde{h}^{(m)} h~(m)就可以了,而并不需要知道它是通过哪个排列 z ~ \tilde{z} z~计算出来的。这样我们在cache前一个segment时不用考虑它的排列。
建模多个segment
许多下游的任务会有多余一个输入序列,比如问答的输入是问题和包含答案的段落。下面我们讨论怎么在自回归框架下怎么预训练两个segment。和BERT一样,我们选择两个句子,它们有50%的概率是连续的句子(前后语义相关),有50%的概率是不连续(无关)的句子。我们把这两个句子拼接后当成一个句子来学习排列语言模型。输入和BERT是类似的:[A, SEP, B, SEP, CLS],这里SEP和CLS是特殊的两个Token,而A和B代表两个Segment。而BERT稍微不同,这里把CLS放到了最后。原因是因为对于BERT来说,Self-Attention唯一能够感知位置是因为我们把位置信息编码到输入向量了,Self-Attention的计算本身不考虑位置信息。而前面我们讨论过,为了减少计算量,这里的排列语言模型通常只预测最后1/K个Token。我们希望CLS编码所有两个Segment的语义,因此希望它是被预测的对象,因此放到最后肯定是会被预测的。
但是和BERT不同,我们并没有增加一个预测下一个句子的Task,原因是通过实验分析这个Task加进去后并不是总有帮助。【注:其实很多做法都是某些作者的经验,后面很多作者一看某个模型好,那么所有的Follow,其实也不见得就一定好。有的时候可能只是对某个数据集有效果,或者效果好是其它因素带来的,一篇文章修改了5个因素,其实可能只是某一两个因素是真正带来提高的地方,其它3个因素可能并不有用甚至还是有少量副作用。】
相对Segment编码
BERT使用的是绝对的Segment编码,也就是第一个句子对于的Segment id是0,而第二个句子是1。这样如果把两个句子换一下顺序,那么输出是不一样的。XLNet使用的是相对的Segment编码,它是在计算Attention的时候判断两个词是否属于同一个Segment,如果位置i和j的词属于同一个segment,那么使用一个可以学习的Embedding s i j = s + s_{ij}=s_+ sij=s+,否则 s i j = s − s_{ij}=s_- sij=s−。也就是说,我们只关心它们是属于同一个Segment还是属于不同的Segment的。当我们从位置i attend to j的时候,我们会这样计算一个新的attention score: a i j = ( q i + b ) T s i j a_{ij}=(q_i+b)^Ts_{ij} aij=(qi+b)Tsij。这里的 q i q_i qi是第i位置的Query向量,b是一个可以学习的bias。最后我们会把这个attention score加到原来计算的Attention score里,这样它就能学到当i和j都属于某个segment的特征和i和就属于不同segment的特征。
XLNet与BERT的对比
XLNet和BERT都是预测一个句子的部分词,但是背后的原因是不同的。BERT使用的是Mask语言模型,因此只能预测部分词(总不能把所有词都Mask了然后预测?)。而XLNet预测部分词是出于性能考虑,而BERT是随机的选择一些词来预测。
除此之外,它们最大的区别其实就是BERT是约等号,也就是条件独立的假设——那些被MASK的词在给定非MASK的词的条件下是独立的。但是我们前面分析过,这个假设并不(总是)成立。下面我们通过一个例子来说明(其实前面已经说过了,理解的读者跳过本节即可)。
假设输入是[New, York, is, a, city],并且假设恰巧XLNet和BERT都选择使用[is, a, city]来预测New和York。同时我们假设XLNet的排列顺序为[is, a, city, New, York]。那么它们优化的目标函数分别为:

从上面可以发现,XLNet可以在预测York的使用利用New的信息,因此它能学到"New York"经常出现在一起而且它们出现在一起的语义和单独出现是完全不同的。
XLNet与语言模型的对比
和语言模型相比,XLNet最大的优势就是通过输入序列的各种排列,同时学习到上下文的信息。
实验
Pretraining和实现
和BERT一样,XLNet使用了BooksCorpus和英文的维基百科作为训练数据,这两者总共13GB的文本。此外,XLNet还增加了Giga5(16GB)、ClueWeb 2012-B和Common Crawl的数据来进行Pretraining。对于ClueWeb 2012-B和Common Crawl的内容使用了启发式的规则进行了预处理,最终各自保留了19GB和78GB的文本。使用SentencePiece工具后分别得到2.78B, 1.09B, 4.75B, 4.30B和19.97B Token(subword unit),总计32.89B。
最大的模型XLNet-Large采样了和BERT-large一样的超参数,从而得到类似大小的模型。序列长度和cache分别设置为512和384。训练XLNet-Large是在512核心(不是512个)的TPU v3芯片上进行,使用Adam优化器迭代了500K次。使用了线性的Learning rate decay,batch大小是2048,最终训练了2.5天。我们发现模型仍然是欠拟合(underfitting)的,如果继续训练的话在训练数据上的loss还能下降。但是对于下游的任务并没有太大帮助。因此我们判断是因为数据太大了,默认没有能力完全拟合数据。为了与BERT对比,我们也训练了XLNet-Base模型,它只使用了BooksCorpus和维基百科的数据。
因为引入了递归(recurrence)的机制,我们使用双向的输入pipeline,也就是把一个batch的一半样本正常顺序输入而另一半反向输入。对于XLNet-Large,我们设置K为6,也就是预测1/6的Token。Fine-tuning过程基本是follow BERT。此外我们采样了span-based预测,也就是我们首先采样一个长度L, L ∈ [ 1 , . . . , 5 ] L \in [1, ..., 5] L∈[1,...,5],也就是最少一个Token(1-gram),最多连续5个Token(5-gram)。然后使用长度为KL的上下文来预测这个n-gram。后面的代码分析我们会看到这一点。
RACE数据集
RACE数据集,它包含大概100K个问题。它是中国12岁到18岁的学生在初中和高中的英语阅读理解问题。下图是其中一个样例,我们在中学经常做的阅读理解题。

图:RACE阅读理解题示例
下图是实验结果,我们可以看到XLNet比最好的BERT模型要提升很多。

图:RACE数据集的结果对比
SQuAD数据集
SQuAD是一个大规模的阅读理解任务的数据集。和前面的选择题不同,SQuAD可以看成问答题,也就是需要从阅读的文章找答案。如下图所示:

图:SQuAD数据示例
SQuAD1.1假设答案是原文的一个连续的一个或者多个词,并且答案是一定存在的。而SQuAD2.0可能会问没有答案的问题。因此为了fine-tuning SQuAD2.0,我们使用了Multi-Task Learning:其中一个损失函数是一个二分类的logistic regression损失函数,它判断有没有答案;而另一个就是标标准的span抽取的损失函数(感兴趣的读者可以参考BERT的论文)。因为v1.1的问题是包含在v2.0里的,因此在打榜的时候我们直接使用v2.0的模型去做v1.1的题目,只是把判断有没有答案的部分去掉(因为v1.1肯定有答案)。另外因为很多参赛者会使用额外的数据,我们也增加了NewsQA的数据作为训练数据。如下表所示,我们的单一的模型(很多好成绩都是好的模型的Ensembling)取得了SOTA的成绩。

图:SQuAD数据集结果对比
文本分类
我们在IMDB,Yelp-2,Yelp-5,DBpedia,AG,Amazon-2和Amazon-5等文本分类数据集上做了对比实验,结果如下:

图:常见文本分类数据集结果对比
GLUE数据集
GLUE数据集上的实验如下:

图:GLUE数据集结果对比
ClueWeb09-B
ClueWeb09-B是一个文档排序的数据集。它主要用于搜索引擎:给定一个Query,然后给相关的网页排序。下面是实验结果:

图:ClueWeb09-B数据集结果对比
Ablation对比实验
因为XLNet引入了很多改进点,包括实验排列语言模型,使用Transformer-XL里的改进,而且还使用了不同的Pretraining数据,为了发现哪些改进是有效的,下面做了Ablation实验,对比的主要是BERT-base和XLNet-base,因为它们的训练数据都是BooksCorpus和Wiki。

图:Ablation对比实验
从上面的对比实验发现:加上预测下一个句子这个Multi-Task任务在XLNet里并无作用。而去掉memory、span-based的预测和双向的数据时效果都是有所下降的,因此它们都是有用的。
代码
请参考下一篇XLNet代码分析。