kubeadm安装高可用kubernetes1.13集群详细步骤,外部etcd方式
文章目录
- 集群规划
- 组件版本
- 高可用架构说明
- 准备工作
- 1、硬件配置
- 2、安装docker
- 3、修改内核参数
- 4、关闭Swap
- 5、开启ipvs
- 6、禁用selinux,关闭防火墙,
- 7、检查网络,dns,hosts,master1到其他机器的ssh免密,ntp是否正常
- 8、除了上述你还应该提前了解k8s的基本概念术语
- 安装步骤
- 一、安装haproxy和keepalived来创建一个负载均衡器。
- 1、安装haproxy
- 2、安装keepalived
- 3、验证keepalived是否正常工作。
- 二、搭建高可用etcd集群
- 1、 在master1上安装cfssl
- 2、 创建ca证书,客户端,服务端,节点之间的证书
- 1) 创建目录
- 2) 创建ca证书
- 3) 生成客户端证书
- 4) 生成server,peer证书
- 5) 将master1的/etc/etcd/pki目录同步到master2和master3上
- 3、 安装etcd二进制文件
- 4、 service配置文件
- 5、 创建存放etcd数据的目录,启动 etcd
- 6、 验证是否成功
- 7、怎么查看etcd里面存储的k8s的数据呢?
- 三、安装 kubeadm, kubelet 和 kubectl
- 1、添加国内yum源
- 2、指定版本安装
- 3、在所有安装kubelet的节点上,将kubelet设置为开机启动
- 四、提前下载所有需要用到的镜像
- 1、下载基础组件镜像
- 2、下载网络插件flannel镜像
- 五、初始化master
- 1、初始化master1
- 1) 在master1上将搭建etcd时生成的的ca证书和客户端证书复制到指定地点并重命名,如下
- 2) 创建初始化配置文件
- 3) 执行初始化
- 4) 如果初始化失败,你可以回滚上一步操作。
- 5)配置kubectl
- 2、初始化其他master
- 1) 首先将 master1 中的 生成的集群共用的ca 证书,scp 到其他 master 机器。
- 2) 将初始化配置文件复制到master2和master3
- 3) 初始化master2
- 4) 初始化master3
- 3、检查三台master是否初始化成功
- 六、 将worker节点加入集群
- 七、安装网络插件Flannel
- 1、下载yml
- 2、 修改配置文件中的镜像地址
- 3、 执行kube-flannel.yml
- 4、执行后,查看pod状态
- 八、部署高可用 CoreDNS
- 1、查看pod的状态
- 2、我们采用直接编辑coredns的deploy文件来改变它的状态
- 3、重新查看pod状态,发现分布在了不同的机器,这样就消除了单点故障隐患
- 4、验证dns功能,如下则表示正常
- 九、检查测试集群是否搭建成功
- 1、查看组件状态是否正常
- 2、创建一个nginx的service试一下集群是否可用。
- 十、安装dashboard
- 十一、验证高可用功能
集群规划
- etcd节点x3 : 必须是奇数个节点,有两种方式,一种是初始化中kubeadm自动搭建,一种是外部方式,提前搭建好。外部方式最好最常用,这里选择3节点的外部方式。生产环境建议5台,可以避免脑裂。
内部etcd和外部etcd的区别:
内部etcd:本机的组件只能和本机的etcd通信
外部etcd:本机的组件可以和整个etcd集群的任意节点通信。
哪个好不言而喻。
-
master节点x3 : 没有奇数偶数的限制,高可用最少三台
-
node节点x2 : 负载应用的节点,后面可以根据实际情况再增加节点数
-
master VIP(虚拟地址): 使用VIP通过keepalived和haproxy来实现apiserver的高可用,当然也可以直接使用阿里云的slb或者腾讯云的clb这种负载均衡服务。
| 主机名 | ip | 角色 | 组件 |
|---|---|---|---|
| master1-3 | 192.168.255.131-133 | master+etcd | etcd kube-apiserver kube-controller-manager kubectl kubeadm kubelet kube-proxyflannel |
| slave1-2 | 192.168.255.121-122 | node | kubectl kubeadm kubelet kube-proxy flannel |
| vip: 192.168.255.140 | 实现apiserver的高可用 |
组件版本
| 组件 | 版本 | 说明 |
|---|---|---|
| centos | 7.3.1611 | |
| kernel | 3.10.0-514.el7.x86_64 | |
| kubeadm | v1.13.0 | |
| kubelet | v1.13.0 | |
| kubectl | v1.13.0 | |
| kube-proxy | v1.13.0 | 通过设置iptables规则转发service流量到后端的pod |
| flannel | v0.10 | 网络插件,实现集群的通信 |
| etcd | 3.2.26 | 必须>=3.2.18,使用二进制包,外部方式搭建 |
| kubernetes-dashboard | v1.10.1 | |
| keepalived | 1.3.5-8.el7_6 | |
| haproxy | 1.5.18-8.el7 | |
| heapster | v1.5.4 | 性能采集组件(kubernetes-dashboard使用) |
| metrics-server | v0.3.1 | 采集pod的cpu,内存指标,供kubectl top使用 |
| prometheus | v2.8.0 | 采集主机,容器,k8s组件指标,并存储监控数据(tsdb),供grafana读取 |
| grafana | 监控数据前台展示 |
高可用架构说明
架构图:https://github.com/cookeem/kubeadm-ha/blob/master/README_CN.md
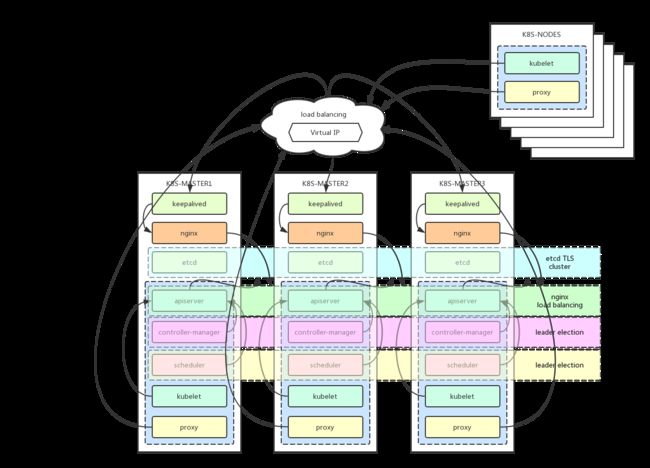
-
kube-apiserver:集群核心,集群API接口、集群各个组件通信的中枢;集群安全控制;
-
etcd:集群的数据中心,用于存放集群的配置以及状态信息,非常重要,如果数据丢失那么集群将无法恢复;因此高可用集群部署首先就是etcd是高可用集群;
-
kube-scheduler:集群Pod的调度中心;默认kubeadm安装情况下–leader-elect参数已经设置为true,保证master集群中只有一个kube-scheduler处于活跃状态;
-
kube-controller-manager:集群状态管理器,当集群状态与期望不同时,kcm会努力让集群恢复期望状态,比如:当一个pod死掉,kcm会努力新建一个pod来恢复对应replicas set期望的状态;默认kubeadm安装情况下–leader-elect参数已经设置为true,保证master集群中只有一个kube-controller-manager处于活跃状态;
-
kubelet: kubernetes node上的 agent,负责与node上的docker engine打交道;
-
kube-proxy: 每个node上一个,负责service vip到endpoint pod的流量转发,原理是通过设置iptables规则实现。
负载均衡
-
keepalived集群设置一个虚拟ip地址,如果某台master宕机,虚拟ip地址会漂移到其他master机器上,实现故障转移
-
haproxy用于master1、master2、master3的apiserver的负载均衡。外部kubectl以及nodes访问apiserver的时候就可以用过keepalived的虚拟ip(192.168.255.140)以及haproxy端口(8443)访问master集群的apiserver
准备工作
在所有节点上作如下准备:
1、硬件配置
强烈建议至少2 cpu ,2G,非硬性要求。1cpu,1G也可以搭建起集群。但是:
1个cpu的话初始化master的时候会报 [WARNING NumCPU]: the number of available CPUs 1 is less than the required 2。此时你需要添加--ignore-preflight-errors="NumCPU"参数
因为安装的东西太多了,内存太少很可能不够,频繁的创建容器,调度容器情况下,cpu使用率也很大。部署插件或者pod时可能会报warning:FailedScheduling:Insufficient cpu, Insufficient memory
2、安装docker
docker18.06版本以下已被验证,最近的版本18.09虽然还未经验证,但经过我测试可以使用,只是初始化时会报warning,官方推荐使用18.06
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 18.09.0. Latest validated version: 18.06
一键安装脚本可参考:https://blog.csdn.net/fanren224/article/details/72598050
3、修改内核参数
禁用ipv6,否则会造成coredns容器无法启动
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward=1
EOF
sysctl --system
如果你不这样做,报错如下
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
4、关闭Swap
k8s1.8版本以后,要求关闭swap,否则默认配置下kubelet将无法启动。
$ swapoff -a
防止开机自动挂载 swap 分区
$ sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
如果你不这样做,报错如下
kubelet[7087]: F0610 21:42:12.912891 7087 server.go:265] failed to run Kubelet: Running with swap on is not supported, please disable swap!
5、开启ipvs
不是必须,只是建议,pod的负载均衡是用kube-proxy来实现的,实现方式有两种,一种是默认的iptables,一种是ipvs,ipvs比iptable的性能更好而已。
ipvs是啥?为啥要用ipvs?:https://blog.csdn.net/fanren224/article/details/86548398
后面master的高可用和集群服务的负载均衡要用到ipvs,所以加载内核的以下模块
需要开启的模块是
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
检查有没有开启
cut -f1 -d " " /proc/modules | grep -e ip_vs -e nf_conntrack_ipv4
没有的话,使用以下命令加载
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
ipvs还需要ipset,检查下有没有。如果没有,安装
yum install ipset -y
6、禁用selinux,关闭防火墙,
7、检查网络,dns,hosts,master1到其他机器的ssh免密,ntp是否正常
8、除了上述你还应该提前了解k8s的基本概念术语
安装步骤
一、安装haproxy和keepalived来创建一个负载均衡器。
这一步的目的是生成一个vip+端口,利用haproxy将流量均衡分配到三台apiserver,并利用keepalived的故障转移特性实现apiser的高可用。
1、安装haproxy
三台master上安装,配置一样
yum install -y haproxy
vim /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
defaults
mode tcp
log global
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
frontend kubernetes
bind *:8443 #配置端口为8443
mode tcp
default_backend kubernetes-master
backend kubernetes-master #后端服务器,也就是说访问192.168.255.140:8443会将请求转发到后端的三台,这样就实现了负载均衡
balance roundrobin
server master1 192.168.255.131:6443 check maxconn 2000
server master2 192.168.255.132:6443 check maxconn 2000
server master3 192.168.255.133:6443 check maxconn 2000
三台haproxy都启动
systemctl enable haproxy && systemctl start haproxy && systemctl status haproxy
2、安装keepalived
在三台master上安装,三台配置不一样,根据备注自己修改
yum install -y keepalived
[root@master1] ~$ vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER #备服务器上改为BACKUP
interface ens33 #改为自己的接口
virtual_router_id 51
priority 100 #备服务器上改为小于100的数字,90,80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.255.140 #虚拟vip,自己设定
}
}
三台都启动
systemctl enable keepalived && systemctl start keepalived && systemctl status keepalived
3、验证keepalived是否正常工作。
查看虚拟ip是不是在master1上。
[root@master1] ~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:24:5f:60 brd ff:ff:ff:ff:ff:ff
inet 192.168.255.131/24 brd 192.168.255.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.255.140/32 scope global ens33
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:55:72:8b:b6 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
然后关闭master1的keepalived服务,测试下vip是否漂移到master2。
[root@master1] ~$ systemctl stop keepalived
[root@master2] ~$ ip a
再启动master1的keepalived服务,查看vip是否重新漂移回来
[root@master1] ~$ systemctl start keepalived
[root@master1] ~$ ip a
如果正常,负载均衡搭建完成。
二、搭建高可用etcd集群
1、 在master1上安装cfssl
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
chmod +x cfssl_linux-amd64 cfssljson_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
2、 创建ca证书,客户端,服务端,节点之间的证书
Etcd属于server ,etcdctl 属于client,二者之间通过http协议进行通信。
- ca证书 自己给自己签名的权威证书,用来给其他证书签名
- server证书 etcd的证书
- client证书 客户端,比如etcdctl的证书
- peer证书 节点与节点之间通信的证书
1) 创建目录
mkdir -p /etc/etcd/pki
cd /etc/etcd/pki
cfssl print-defaults config > ca-config.json
cfssl print-defaults csr > ca-csr.json
2) 创建ca证书
修改vim ca-config.json
server auth表示client可以用该ca对server提供的证书进行验证
client auth表示server可以用该ca对client提供的证书进行验证
{
"signing": {
"default": {
"expiry": "43800h"
},
"profiles": {
"server": {
"expiry": "43800h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
},
"client": {
"expiry": "43800h",
"usages": [
"signing",
"key encipherment",
"client auth"
]
},
"peer": {
"expiry": "43800h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
创建证书签名请求ca-csr.json
{
"CN": "etcd",
"key": {
"algo": "rsa",
"size": 2048
}
}
生成CA证书和私钥
# cfssl gencert -initca ca-csr.json | cfssljson -bare ca
# ls ca*
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem
3) 生成客户端证书
vim client.json
{
"CN": "client",
"key": {
"algo": "ecdsa",
"size": 256
}
}
生成
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=client client.json | cfssljson -bare client -
# ls ca*
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem client-key.pem client.pem
4) 生成server,peer证书
创建配置 vim etcd.json
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"192.168.255.131",
"192.168.255.132",
"192.168.255.133"
],
"key": {
"algo": "ecdsa",
"size": 256
},
"names": [
{
"C": "CN",
"L": "SH",
"ST": "SH"
}
]
}
生成
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=server etcd.json | cfssljson -bare server
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=peer etcd.json | cfssljson -bare peer
5) 将master1的/etc/etcd/pki目录同步到master2和master3上
scp -r /etc/etcd/pki/ master2.hanli.com:/etc/etcd/pki/
scp -r /etc/etcd/pki/ master3.hanli.com:/etc/etcd/pki/
3、 安装etcd二进制文件
在三台master上安装
需要注意的是你安装的版本必须大于等于版本3.2.18,否则报错如下:
[ERROR ExternalEtcdVersion]: this version of kubeadm only supports external etcd version >= 3.2.18. Current version: 3.1.5
下载二进制文件,并将解压后的两个命令移动到/usr/local/bin目录下
wget https://github.com/coreos/etcd/releases/download/v3.1.5/etcd-v3.1.5-linux-amd64.tar.gz
tar -xvf etcd-v3.1.5-linux-amd64.tar.gz
mv etcd-v3.1.5-linux-amd64/etcd* /usr/local/bin
4、 service配置文件
vim /usr/lib/systemd/system/etcd.service, 三台机器配置不一样,需要替换为相应的IP和name。
注意格式很重要,后面的\与结尾的字母中间只能相隔一个空格。
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd
ExecStart=/usr/local/bin/etcd \
--data-dir=/var/lib/etcd \
--name=master1 \ #其他机器相应的修改为master2和master3,与下面的--initial-cluster对应
--cert-file=/etc/etcd/pki/server.pem \
--key-file=/etc/etcd/pki/server-key.pem \
--trusted-ca-file=/etc/etcd/pki/ca.pem \
--peer-cert-file=/etc/etcd/pki/peer.pem \
--peer-key-file=/etc/etcd/pki/peer-key.pem \
--peer-trusted-ca-file=/etc/etcd/pki/ca.pem \
--listen-peer-urls=https://192.168.255.131:2380 \ #修改
--initial-advertise-peer-urls=https://192.168.255.131:2380 \ #修改
--listen-client-urls=https://192.168.255.131:2379,http://127.0.0.1:2379 \ #修改
--advertise-client-urls=https://192.168.255.131:2379 \ #修改
--initial-cluster-token=etcd-cluster-0 \
--initial-cluster=master1=https://192.168.255.131:2380,master2=https://192.168.255.132:2380,master3=https://192.168.255.133:2380 \
--initial-cluster-state=new \
--heartbeat-interval=250 \
--election-timeout=2000
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
5、 创建存放etcd数据的目录,启动 etcd
三台都执行。不用按顺序启动
mkdir /var/lib/etcd
systemctl daemon-reload && systemctl enable etcd && systemctl start etcd && systemctl status etcd
6、 验证是否成功
在任意一台机器(无论是不是集群节点,前提是需要有etcdctl工具和ca证书,server证书)上执行如下命令:
[root@master1] /etc/etcd/pki$ etcdctl --ca-file=/etc/etcd/pki/ca.pem --cert-file=/etc/etcd/pki/server.pem --key-file=/etc/etcd/pki/server-key.pem --endpoints=https://192.168.255.131:2379 cluster-health
2019-01-27 20:41:26.909601 I | warning: ignoring ServerName for user-provided CA for backwards compatibility is deprecated
2019-01-27 20:41:26.910165 I | warning: ignoring ServerName for user-provided CA for backwards compatibility is deprecated
member 5d7a44f5c39446c1 is healthy: got healthy result from https://192.168.255.132:2379
member e281e4e43dceb752 is healthy: got healthy result from https://192.168.255.133:2379
member ea5e4f12ed162d4b is healthy: got healthy result from https://192.168.255.131:2379
cluster is healthy
7、怎么查看etcd里面存储的k8s的数据呢?
设置etcdctl使用的api为3
[root@master1] ~$ export ETCDCTL_API=3
确认下api版本
[root@master1] ~$ etcdctl version
etcdctl version: 3.2.26
API version: 3.2
查看有哪些key
[root@master1] ~$ etcdctl --cacert=/etc/etcd/pki/ca.pem --cert=/etc/etcd/pki/server.pem --key=/etc/etcd/pki/server-key.pem --endpoints=https://192.168.255.131:2379 get / --prefix --keys-only=true
/registry/apiregistration.k8s.io/apiservices/v1.
/registry/apiregistration.k8s.io/apiservices/v1.apps
/registry/apiregistration.k8s.io/apiservices/v1.authentication.k8s.io
/registry/apiregistration.k8s.io/apiservices/v1.authorization.k8s.io
/registry/apiregistration.k8s.io/apiservices/v1.autoscaling
/registry/apiregistration.k8s.io/apiservices/v1.batch
/registry/apiregistration.k8s.io/apiservices/v1.networking.k8s.io
查看某个key
[root@master1] ~$ etcdctl --cacert=/etc/etcd/pki/ca.pem --cert=/etc/etcd/pki/server.pem --key=/etc/etcd/pki/server-key.pem --endpoints=https://192.168.255.131:2379 get /registry/apiregistration.k8s.io/apiservices/v1.batch
/registry/apiregistration.k8s.io/apiservices/v1.batch
{"kind":"APIService","apiVersion":"apiregistration.k8s.io/v1beta1","metadata":{"name":"v1.batch","uid":"bb0dcc37-8aad-11e9-b0b6-000c29245f60","creationTimestamp":"2019-06-09T11:57:18Z","labels":{"kube-aggregator.kubernetes.io/automanaged":"onstart"}},"spec":{"service":null,"group":"batch","version":"v1","groupPriorityMinimum":17400,"versionPriority":15},"status":{"conditions":[{"type":"Available","status":"True","lastTransitionTime":"2019-06-09T11:57:18Z","reason":"Local","message":"Local APIServices are always available"}]}}
至此高可用ssl安全通信etcd集群搭建完成。
三、安装 kubeadm, kubelet 和 kubectl
所有节点安装 kubeadm, kubelet 。kubectl是可选的,你可以安装在所有机器上,也可以只安装在一台master1上。
1、添加国内yum源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2、指定版本安装
yum install -y kubelet-1.13.0 kubeadm-1.13.0 kubectl-1.13.0 --disableexcludes=kubernetes #禁用除kubernetes之外的仓库
3、在所有安装kubelet的节点上,将kubelet设置为开机启动
systemctl enable kubelet
如果你不这样的话,后面初始化master和初始化node时,会报一个warnning:
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
四、提前下载所有需要用到的镜像
在所有节点上提前下载以下镜像
- 基础组件镜像
- 网络插件镜像
- dashborad镜像(如果你准备安装)
1、下载基础组件镜像
有两种办法,本节参考了文章: http://blog.51cto.com/purplegrape/2315451
第一种:从国内源下载好然后修改tag(推荐方式)
1) 先查看要用到的镜像有哪些,这里要注意的是:要拉取的4个核心组件的镜像版本和你安装的kubelet、kubeadm、kubectl 版本需要是一致的。
[root@master] ~$ kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.13.0
k8s.gcr.io/kube-controller-manager:v1.13.0
k8s.gcr.io/kube-scheduler:v1.13.0
k8s.gcr.io/kube-proxy:v1.13.0
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.2.24
k8s.gcr.io/coredns:1.2.6
2、下载
# 拉镜像
kubeadm config images list |sed -e 's/^/docker pull /g' -e 's#k8s.gcr.io#mirrorgooglecontainers#g' |sh -x
docker pull coredns/coredns:1.2.6
# 修改tag,将镜像标记为k8s.gcr.io的名称
docker images |grep mirrorgooglecontainers |awk '{print "docker tag ",$1":"$2,$1":"$2}' |sed -e 's#mirrorgooglecontainers#k8s.gcr.io#2' |sh -x
docker tag coredns/coredns:1.2.6 k8s.gcr.io/coredns:1.2.6
# 删除无用的镜像
docker images | grep mirrorgooglecontainers | awk '{print "docker rmi " $1":"$2}' | sh -x
docker rmi coredns/coredns:1.2.6
3、查看准备好的镜像是否与kubeadm config images list要求的一致。
[root@master] ~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-apiserver-amd64 v1.13.0 177db4b8e93a 28 hours ago 181MB
k8s.gcr.io/kube-controller-manager v1.13.0 b9027a78d94c 28 hours ago 146MB
k8s.gcr.io/kube-proxy v1.13.0 01cfa56edcfc 28 hours ago 80.3MB
k8s.gcr.io/kube-scheduler v1.13.0 3193be46e0b3 28 hours ago 79.6MB
k8s.gcr.io/coredns 1.2.6 f59dcacceff4 2 months ago 40MB
k8s.gcr.io/etcd 3.2.24 3cab8e1b9802 3 months ago 220MB
k8s.gcr.io/pause 3.1 da86e6ba6ca1 12 months ago 742kB
第二种:修改kubeadm配置文件中的docker仓库地址imageRepository,注意:此方法只适用于1.11(不确定)版本以上
1、一开始没有配置文件,先使用下面的命令生成配置文件
kubeadm config print init-defaults > kubeadm.conf
2、将配置文件中的 imageRepository: k8s.gcr.io 改为你自己的私有docker仓库,比如
sed -i '/^imageRepository/ s/k8s\.gcr\.io/u9nigs6v\.mirror\.aliyuncs\.com\/google_containers/g' kubeadm.conf
imageRepository: u9nigs6v.mirror.aliyuncs.com/mirrorgooglecontainers
3、然后运行命令拉镜像
kubeadm config images list --config kubeadm.conf
kubeadm config images pull --config kubeadm.conf
4、查看准备好的镜像是否与kubeadm config images list --kubeadm.conf要求的一致。
docker images
2、下载网络插件flannel镜像
docker pull registry.cn-shanghai.aliyuncs.com/gcr-k8s/flannel:v0.10.0-amd64
五、初始化master
1、初始化master1
1) 在master1上将搭建etcd时生成的的ca证书和客户端证书复制到指定地点并重命名,如下
[root@master1] ~$ mkdir -p /etc/kubernetes/pki/etcd/
#etcd集群的ca证书
[root@master1] ~$ cp /etc/etcd/pki/ca.pem /etc/kubernetes/pki/etcd/
#etcd集群的client证书,apiserver访问etcd使用
[root@master1] ~$ cp /etc/etcd/pki/client.pem /etc/kubernetes/pki/apiserver-etcd-client.pem
#etcd集群的client私钥
[root@master1] ~$ cp /etc/etcd/pki/client-key.pem /etc/kubernetes/pki/apiserver-etcd-client-key.pem
#确保
[root@master1] ~$ tree /etc/kubernetes/pki/
/etc/kubernetes/pki/
├── apiserver-etcd-client-key.pem
├── apiserver-etcd-client.pem
└── etcd
└── ca.pem
1 directory, 3 files
2) 创建初始化配置文件
网络插件采用flannel,flannel默认的CIDR地址是 “10.244.0.0/16”, etcd使用外部方式。
需要知道的是,三台master初始化将共同使用此配置文件,配置完全一样
[root@master1] ~$ vim kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta1
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.255.131
bindPort: 6443
---
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: v1.13.0
imageRepository: k8s.gcr.io
apiServer:
certSANs:
- "master1.hanli.com"
- "master2.hanli.com"
- "master3.hanli.com"
- "192.168.255.131"
- "192.168.255.132"
- "192.168.255.133"
- "192.168.255.140"
- "127.0.0.1"
controlPlaneEndpoint: "192.168.255.140:8443"
etcd:
external:
endpoints:
- https://192.168.255.131:2379
- https://192.168.255.132:2379
- https://192.168.255.133:2379
caFile: /etc/kubernetes/pki/etcd/ca.pem #搭建etcd集群时生成的ca证书
certFile: /etc/kubernetes/pki/apiserver-etcd-client.pem #搭建etcd集群时生成的客户端证书
keyFile: /etc/kubernetes/pki/apiserver-etcd-client-key.pem #搭建etcd集群时生成的客户端密钥
networking:
podSubnet: "10.244.0.0/16"
~
3) 执行初始化
[root@master1] ~$ kubeadm init --config=kubeadm-init.yaml
[init] Using Kubernetes version: v1.13.0
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 18.09.0. Latest validated version: 18.06
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] External etcd mode: Skipping etcd/ca certificate authority generation
[certs] External etcd mode: Skipping etcd/server certificate authority generation
[certs] External etcd mode: Skipping etcd/peer certificate authority generation
[certs] External etcd mode: Skipping etcd/healthcheck-client certificate authority generation
[certs] External etcd mode: Skipping apiserver-etcd-client certificate authority generation
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [master1.hanli.com kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master1.hanli.com master2.hanli.com master3.hanli.com] and IPs [10.96.0.1 192.168.255.131 192.168.255.140 192.168.255.131 192.168.255.132 192.168.255.133 192.168.255.140 127.0.0.1]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 19.005280 seconds
[uploadconfig] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.13" in namespace kube-system with the configuration for the kubelets in the cluster
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "master1.hanli.com" as an annotation
[mark-control-plane] Marking the node master1.hanli.com as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node master1.hanli.com as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: j1268k.2vyfdcimdtiejtdm
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstraptoken] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstraptoken] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstraptoken] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstraptoken] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 192.168.255.140:8443 --token j1268k.2vyfdcimdtiejtdm --discovery-token-ca-cert-hash sha256:5cb3516306bf1a8f2957255b3bbcc17a89056c7d96fa9b2946dbef7e17e2ad39
4) 如果初始化失败,你可以回滚上一步操作。
kubeadm reset
重置之后,你再次初始化后,然后使用kubectl get node会报错如下:
这是因为你用kubeadm reset重置过,.kube目录并没有删除,还是之前的。
[root@master1] ~$ kubectl get node
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
解决办法是删除rm -rf .kube/,重新执行那三条命令来生成新的.kube目录。
5)配置kubectl
要使用 kubectl来 管理集群操作集群,需要做如下配置:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果不这样做的话,使用kubectl会报错
[root@master1] ~$ kubectl get pods -n kube-system -o wide
The connection to the server localhost:8080 was refused - did you specify the right host or port?
测试下,kubectl是否正常,需要注意是此时master1的notready状态是正常的,因为我们还没有部署flannel网络插件
[root@master1] ~$ kubectl get node
NAME STATUS ROLES AGE VERSION
master1.hanli.com NotReady master 66s v1.13.0
2、初始化其他master
1) 首先将 master1 中的 生成的集群共用的ca 证书,scp 到其他 master 机器。
[root@master1] ~$ scp -r /etc/kubernetes/pki/* master2.hanli.com:/etc/kubernetes/pki/
[root@master1] ~$ scp -r /etc/kubernetes/pki/* master3.hanli.com:/etc/kubernetes/pki/
这里最好了解下pki目录中的每个证书文件都是干啥用的
[root@master1] ~$ tree /etc/kubernetes/pki/
/etc/kubernetes/pki/
├── apiserver.crt
├── apiserver-etcd-client-key.pem
├── apiserver-etcd-client.pem
├── apiserver.key
├── apiserver-kubelet-client.crt
├── apiserver-kubelet-client.key
├── ca.crt
├── ca.key
├── etcd
│ └── ca.pem
├── front-proxy-ca.crt
├── front-proxy-ca.key
├── front-proxy-client.crt
├── front-proxy-client.key
├── sa.key
└── sa.pub
1 directory, 15 files
2) 将初始化配置文件复制到master2和master3
[root@master1] ~$ scp kubeadm-init.yaml master2.hanli.com:/root/
[root@master1] ~$ scp kubeadm-init.yaml master3.hanli.com:/root/
3) 初始化master2
[root@master2] ~$ kubeadm init --config=kubeadm-init.yaml
4) 初始化master3
[root@master3] ~$ kubeadm init --config=kubeadm-init.yaml
3、检查三台master是否初始化成功
此时,你的node状态应该是这样的
[root@master1] ~$ kubectl get node
NAME STATUS ROLES AGE VERSION
master1.hanli.com NotReady master 33m v1.13.0
master2.hanli.com NotReady master 5m29s v1.13.0
master3.hanli.com NotReady master 4m51s v1.13.0
你的pod状态应该是这样的:
[root@master1] ~$ kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-86c58d9df4-dwltw 0/1 ContainerCreating 0 16m <none> master2.hanli.com <none> <none>
kube-system coredns-86c58d9df4-l4bcw 0/1 ContainerCreating 0 16m <none> master2.hanli.com <none> <none>
kube-system kube-apiserver-master1.hanli.com 1/1 Running 0 15m 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-apiserver-master2.hanli.com 1/1 Running 0 9m51s 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-apiserver-master3.hanli.com 1/1 Running 0 8m42s 192.168.255.133 master3.hanli.com <none> <none>
kube-system kube-controller-manager-master1.hanli.com 1/1 Running 0 15m 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-controller-manager-master2.hanli.com 1/1 Running 0 9m51s 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-controller-manager-master3.hanli.com 1/1 Running 0 8m42s 192.168.255.133 master3.hanli.com <none> <none>
kube-system kube-proxy-dxsw9 1/1 Running 0 9m51s 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-proxy-ggjks 1/1 Running 0 8m42s 192.168.255.133 master3.hanli.com <none> <none>
kube-system kube-proxy-k5j7z 1/1 Running 0 16m 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-scheduler-master1.hanli.com 1/1 Running 0 15m 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-scheduler-master2.hanli.com 1/1 Running 0 9m51s 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-scheduler-master3.hanli.com 1/1 Running 0 8m42s 192.168.255.133 master3.hanli.com <none> <none>
六、 将worker节点加入集群
在所有work节点上执行以下命令
[root@slave1] ~$ kubeadm join 192.168.255.140:8443 --token j1268k.2vyfdcimdtiejtdm --discovery-token-ca-cert-hash sha256:5cb3516306bf1a8f2957255b3bbcc17a89056c7d96fa9b2946dbef7e17e2ad39
[root@slave2] ~$ kubeadm join 192.168.255.140:8443 --token j1268k.2vyfdcimdtiejtdm --discovery-token-ca-cert-hash sha256:5cb3516306bf1a8f2957255b3bbcc17a89056c7d96fa9b2946dbef7e17e2ad39
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 18.09.0. Latest validated version: 18.06
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[discovery] Trying to connect to API Server "192.168.255.140:8443"
[discovery] Created cluster-info discovery client, requesting info from "https://192.168.255.140:8443"
[discovery] Requesting info from "https://192.168.255.140:8443" again to validate TLS against the pinned public key
[discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "192.168.255.140:8443"
[discovery] Successfully established connection with API Server "192.168.255.140:8443"
[join] Reading configuration from the cluster...
[join] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet] Downloading configuration for the kubelet from the "kubelet-config-1.13" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[tlsbootstrap] Waiting for the kubelet to perform the TLS Bootstrap...
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "slave2.hanli.com" as an annotation
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the master to see this node join the cluster.
检查work节点是否正常加入集群
[root@master1] ~$ kubectl get node
NAME STATUS ROLES AGE VERSION
master1.hanli.com NotReady master 36m v1.13.0
master2.hanli.com NotReady master 8m39s v1.13.0
master3.hanli.com NotReady master 8m1s v1.13.0
slave1.hanli.com NotReady 53s v1.13.0
slave2.hanli.com NotReady 46s v1.13.0
此处遇到一个问题,如上你所看到的,worker节点加入后,node节点的roles属性为none,原因我在https://stackoverflow.com/questions/48854905/how-to-add-roles-to-nodes-in-kubernetes看到,貌似是个bug(存疑)
你可以这样解决:
kubectl label node slave1.hanli.com node-role.kubernetes.io/worker=worker
也可以不用管,直接忽略应该也可以
七、安装网络插件Flannel
各种网络插件有什么区别?在什么情况下该怎么选择?
不在本文叙述范围。真实原因是我也不清楚。。。网络是最难的东西
只需在master1上执行
1、下载yml
下载完成后打开看看,大体上了解下它可能会做些什么事情,蒙头就apply是不建议的行为。
[root@master] ~$ wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
需要注意的是:
flannel 默认会使用主机的第一张物理网卡,如果你有多张网卡,需要通过配置单独指定。修改 kube-flannel.yml 中的以下部分。
当然如果你有一张物理网卡,可以不用修改。
[root@master] ~$ vim kube-flannel.yml
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.10.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=ens33 #添加
2、 修改配置文件中的镜像地址
只需要修改amd64结尾的镜像地址,以arm64,ppc64le。。为结尾的不用修改。因为这个配置文件会根据节点的label(beta.kubernetes.io/arch=amd64)自动选择使用哪个镜像来创建。(你也可以把除了amd64之外的daemon相关配置删除)
在第四步的时候,我们已经下载好了flannel镜像,请再确认一下所以节点是否已经存在镜像。并将image字段的值,修改为你的
镜像地址。注意有两处地方需要修改。
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-flannel-ds-amd64
initContainers:
- name: install-cni
image: registry.cn-shanghai.aliyuncs.com/gcr-k8s/flannel:v0.10.0-amd64
command:
- cp
args:
....
containers:
- name: kube-flannel
image: registry.cn-shanghai.aliyuncs.com/gcr-k8s/flannel:v0.10.0-amd64
3、 执行kube-flannel.yml
[root@master] ~$ kubectl apply -f kube-flannel.yml
4、执行后,查看pod状态
如下表示正常
[root@master1] ~$ kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-86c58d9df4-g8xh4 1/1 Running 0 5m12s 10.244.4.2 slave1.hanli.com
kube-system coredns-86c58d9df4-gtcll 1/1 Running 0 5m12s 10.244.4.3 slave1.hanli.com
kube-system kube-apiserver-master1.hanli.com 1/1 Running 0 24m 192.168.255.131 master1.hanli.com
kube-system kube-apiserver-master2.hanli.com 1/1 Running 0 19m 192.168.255.132 master2.hanli.com
kube-system kube-apiserver-master3.hanli.com 1/1 Running 1 17m 192.168.255.133 master3.hanli.com
kube-system kube-controller-manager-master1.hanli.com 1/1 Running 2 24m 192.168.255.131 master1.hanli.com
kube-system kube-controller-manager-master2.hanli.com 1/1 Running 0 19m 192.168.255.132 master2.hanli.com
kube-system kube-controller-manager-master3.hanli.com 1/1 Running 0 17m 192.168.255.133 master3.hanli.com
kube-system kube-flannel-ds-amd64-cs7n7 1/1 Running 0 93s 192.168.255.122 slave2.hanli.com
kube-system kube-flannel-ds-amd64-jsz4n 1/1 Running 0 89s 192.168.255.131 master1.hanli.com
kube-system kube-flannel-ds-amd64-lplcp 1/1 Running 0 89s 192.168.255.121 slave1.hanli.com
kube-system kube-flannel-ds-amd64-qf5md 1/1 Running 0 93s 192.168.255.133 master3.hanli.com
kube-system kube-flannel-ds-amd64-t5khz 1/1 Running 0 96s 192.168.255.132 master2.hanli.com
kube-system kube-proxy-dxsw9 1/1 Running 0 19m 192.168.255.132 master2.hanli.com
kube-system kube-proxy-ggjks 1/1 Running 0 17m 192.168.255.133 master3.hanli.com
kube-system kube-proxy-gscwx 1/1 Running 0 3m25s 192.168.255.121 slave1.hanli.com
kube-system kube-proxy-k5j7z 1/1 Running 0 25m 192.168.255.131 master1.hanli.com
kube-system kube-proxy-rrsb8 1/1 Running 0 6m8s 192.168.255.122 slave2.hanli.com
kube-system kube-scheduler-master1.hanli.com 1/1 Running 2 24m 192.168.255.131 master1.hanli.com
kube-system kube-scheduler-master2.hanli.com 1/1 Running 0 19m 192.168.255.132 master2.hanli.com
kube-system kube-scheduler-master3.hanli.com 1/1 Running 0 17m 192.168.255.133 master3.hanli.com
八、部署高可用 CoreDNS
1、查看pod的状态
可以看到两个coredns都在slave1上,存在单点故障问题,我们需要想办法让coredns分布在不同的机器上,来避免单点故障,从而实现高可用。
[root@master1] ~$ kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-86c58d9df4-g8xh4 1/1 Running 0 5m12s 10.244.4.2 slave1.hanli.com <none> <none>
kube-system coredns-86c58d9df4-gtcll 1/1 Running 0 5m12s 10.244.4.3 slave1.hanli.com <none> <none>
kube-system kube-apiserver-master1.hanli.com 1/1 Running 0 24m 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-apiserver-master2.hanli.com 1/1 Running 0 19m 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-apiserver-master3.hanli.com 1/1 Running 1 17m 192.168.255.133 master3.hanli.com <none> <none>
kube-system kube-controller-manager-master1.hanli.com 1/1 Running 2 24m 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-controller-manager-master2.hanli.com 1/1 Running 0 19m 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-controller-manager-master3.hanli.com 1/1 Running 0 17m 192.168.255.133 master3.hanli.com <none> <none>
kube-system kube-flannel-ds-amd64-cs7n7 1/1 Running 0 93s 192.168.255.122 slave2.hanli.com <none> <none>
kube-system kube-flannel-ds-amd64-jsz4n 1/1 Running 0 89s 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-flannel-ds-amd64-lplcp 1/1 Running 0 89s 192.168.255.121 slave1.hanli.com <none> <none>
kube-system kube-flannel-ds-amd64-qf5md 1/1 Running 0 93s 192.168.255.133 master3.hanli.com <none> <none>
kube-system kube-flannel-ds-amd64-t5khz 1/1 Running 0 96s 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-proxy-dxsw9 1/1 Running 0 19m 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-proxy-ggjks 1/1 Running 0 17m 192.168.255.133 master3.hanli.com <none> <none>
kube-system kube-proxy-gscwx 1/1 Running 0 3m25s 192.168.255.121 slave1.hanli.com <none> <none>
kube-system kube-proxy-k5j7z 1/1 Running 0 25m 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-proxy-rrsb8 1/1 Running 0 6m8s 192.168.255.122 slave2.hanli.com <none> <none>
kube-system kube-scheduler-master1.hanli.com 1/1 Running 2 24m 192.168.255.131 master1.hanli.com <none> <none>
kube-system kube-scheduler-master2.hanli.com 1/1 Running 0 19m 192.168.255.132 master2.hanli.com <none> <none>
kube-system kube-scheduler-master3.hanli.com 1/1 Running 0 17m 192.168.255.133 master3.hanli.com <none> <none>
2、我们采用直接编辑coredns的deploy文件来改变它的状态
在sepc和container之间,添加如下字段,注意格式缩进
[root@master1] ~$ kubectl edit deploy/coredns -n kube-system
..............
template:
metadata:
creationTimestamp: null
labels:
k8s-app: kube-dns
spec:
affinity: # 添加start
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostname
weight: 100 # 添加end
containers:
- args:
- -conf
- /etc/coredns/Corefile
image: k8s.gcr.io/coredns:1.2.6
imagePullPolicy: IfNotPresent
........
编辑完后,正常情况下会输出如下。如果不是下面的状态,表示你编辑出错了,检查下是不是单词少了个字母之类的
deployment.extensions/coredns edited
3、重新查看pod状态,发现分布在了不同的机器,这样就消除了单点故障隐患
[root@master1] ~$ kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-769c489984-428hc 1/1 Running 0 2m51s 10.244.3.2 slave2.hanli.com <none> <none>
kube-system coredns-769c489984-9cb46 1/1 Running 0 2m50s 10.244.1.2 master2.hanli.com <none> <none>
4、验证dns功能,如下则表示正常
[root@master1] ~$ kubectl run curl --image=radial/busyboxplus:curl -it
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
If you don't see a command prompt, try pressing enter.
[ root@curl-66959f6557-w4bjj:/ ]$ nslookup kubernetes.default
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
[ root@curl-66959f6557-w4bjj:/ ]$
九、检查测试集群是否搭建成功
1、查看组件状态是否正常
节点状态
[root@master1] ~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1.hanli.com Ready master 71m v1.13.0
master2.hanli.com Ready master 64m v1.13.0
master3.hanli.com Ready master 63m v1.13.0
slave1.hanli.com Ready <none> 49m v1.13.0
slave2.hanli.com Ready <none> 51m v1.13.0
组件状态
[root@master1] ~$ kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
服务账户
[root@master1] ~$ kubectl get serviceaccount
NAME SECRETS AGE
default 1 69m
集群信息,注意这里的api地址正是我们搭建的vip地址。
[root@master1] ~$ kubectl cluster-info
Kubernetes master is running at https://192.168.255.140:8443
KubeDNS is running at https://192.168.255.140:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
2、创建一个nginx的service试一下集群是否可用。
创建
[root@master1] ~$ kubectl run nginx --replicas=2 --labels="run=load-balancer-example" --image=nginx --port=80
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
deployment.apps/nginx created
暴露端口
[root@master1] ~$ kubectl expose deployment nginx --type=NodePort --name=example-service
service/example-service exposed
查看详细信息
[root@master1] ~$ kubectl describe service example-service
Name: example-service
Namespace: default
Labels: run=load-balancer-example
Annotations: <none>
Selector: run=load-balancer-example
Type: NodePort
IP: 10.99.229.55
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 31775/TCP
Endpoints: <none>
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
服务状态
[root@master1] ~$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
example-service NodePort 10.99.229.55 <none> 80:31775/TCP 60s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 75m
访问服务ip
[root@master1] ~$ curl 10.99.229.55:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
查看endpoint
[root@master1] ~$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
curl-66959f6557-w4bjj 1/1 Running 1 8m49s 10.244.3.3 slave2.hanli.com <none> <none>
nginx-58db6fdb58-mc9cc 1/1 Running 0 2m54s 10.244.3.4 slave2.hanli.com <none> <none>
nginx-58db6fdb58-xk5hr 1/1 Running 0 2m54s 10.244.4.4 slave1.hanli.com <none> <none>
访问endpoint,与访问服务ip结果相同,请求service,本质上请求的还是endpoint。
[root@master1] ~$ curl 10.244.3.4:80
[root@master1] ~$ curl 10.244.4.4:80
通过节点IP来访问,集群内所以节点+NodePort均可以访问
[root@master1] ~$ curl 192.168.255.131:31775
[root@master1] ~$ curl 192.168.255.132:31775
[root@master1] ~$ curl 192.168.255.133:31775
[root@master1] ~$ curl 192.168.255.121:31775
[root@master1] ~$ curl 192.168.255.122:31775
十、安装dashboard
参考: https://blog.csdn.net/fanren224/article/details/86610466

十一、验证高可用功能
将master1关机,如果还是可以执行kubectl命令,创建pod等,说明高可用搭建成功。
这是因为vip已漂移到master2,只要VIP存在,apiserver就还是可以接收我们的指令。
重启后vip又会回到master1。