Tokyo Cabinet TC 源码学习笔记
Tokyo Cabinet TC 源码学习笔记
1 TC数据库简介
1.1 基本数据库类型
1.2 数据库参数
1.3 常用的测试命令
2 Hash Database
2.1 文件结构
2.2 基本实现
2.2.1 缓存机制
2.2.2 共享内存
2.2.3 查询流程
2.2.4 写入流程
2.2.5 删除流程
2.2.6 free pool管理
2.2.7 事务机制
3 B+ tree database
3.1 文件结构
3.2 基本实现
3.2.1 缓存机制
3.2.2 分裂节点
3.2.3 查询流程
3.2.4 写入流程
3.2.5 隐患
TC数据库简介
基本数据库类型
TC中一共支持六种数据类型,分别以数据库文件的后缀区分:
Hash Database(.tch)、B+ Tree Database(.tcb)、Table Database(.tct)、Fixed-length Database(.tcf)、内存Hash Database(*)、内存B+ tree database(+)。
Hash Database是最基本的结构了,只提供key-value存储方式,类似于memcached,Hash Database的特点是查找速度很快,bucket越多,数据越分散,查找越快。
Hash database支持的参数有:"mode", "bnum", "apow", "fpow", "opts", "rcnum", "xmsiz", 和 "dfunit".
内存Hash Database支持的参数有:"bnum", "capnum", 和 "capsiz"
B+ Tree Database的特点是一个key可以有重复value,而且允许在value之间上下移动,value按插入顺序排列,可以范围查找key,也可以前缀查找key,查找的复杂度是O(log n),所以n越大性能越低,但是在亿级以内的数据性能基本稳定。
B+ tree database支持的参数有:"mode", "lmemb", "nmemb", "bnum", "apow", "fpow", "opts", "lcnum", "ncnum", "xmsiz", and "dfunit"
内存B+ Tree Database支持的参数有:"capnum" and "capsiz".
Table Database的特点是支持检索,支持多列字段,支持列索引,性能不如其它结构。
Table Database提供了类似RMDB的存储功能,一个主键可以有多个字段,例如,在RMDB中user表可能会有user_id、name和password等字段,而在Table Database也提供这种支持。
Table database支持的参数有:"mode", "bnum", "apow", "fpow", "opts", "rcnum", "lcnum", "ncnum", "xmsiz", "dfunit", and "idx".
Fixed-length Database的读写速度是最快的,并且存储所需的空间是最小的(因为不需要存储数据以外的结构关系,但是因为是定长的,所以会有空间浪费),key只 能是数字,而value的长度是有限的,所以必须设置一个合适的value长度,太长会浪费空间,间接影响性能(TPS)。
Fixed-length database支持的参数有:"mode", "width", 和 "limsiz".
数据库参数
合理的设置数据库参数可以提高性能,格式是:数据库名[#参数名1=参数值1][ #参数名2=参数值2]… …。例如它可以指定bucket存储桶的数量 “tc.tch#bnum=1000000”。
以下是个参数的含义:
capnum :设置记录的最大容量
capsiz :设置内存型database的内存容量,内存不足记录将按照顺序移除
mode : 可选的选项:w (写)、r (读)、c (创建)、t (截断)、t (无锁)、f (非阻塞锁)。默认值为 :wc
idx :设置索引的列名,用:分割
opts :可选的选项:l (64位bucket数组,database容量可以超过2G)、d (Deflate压缩)、b(BZIP2压缩)、t(TCBS压缩)
bnum :bucket的数量
apow :指定记录队列的大小(2的幂数). 如果负数,设置无效
fpow :指定free block pool最大的记录数(2的幂数). 如果负数,设置无效
rcnum :设置缓存记录的最大数,如果数值不是大于0则会禁用缓存,默认禁用
lcnum :设置缓存叶节点(leaf nodes)的最大数,如果数值不是大于0则会禁用缓存,默认值4096
ncnum :设置缓存非叶节点(non-leaf nodes)的最大数,如果数值不是大于0则会禁用缓存,默认值512
xmsiz :设置额外内存映射容量,如果数值不是大于0则会禁用内存映射,默认值67108864
dfunit :设置磁盘空间整理的最小单位数,如果数值不是大于0则会禁止自动的磁盘空间整理,默认值0
width :设置记录的固定大小,如果数值不是大于0,则默认是255
limsiz :设置数据库文件的大小,如果数值不是大于0,则默认是268435456
lmemb :设置每个叶节点页(leaf page)的成员数,如果数值不是大于0,则默认是128
nmemb :设置每个非叶节点页(non-leaf page)的成员数,如果数值不是大于0,则默认是256
常用的测试命令
TC提供个各种数据库的管理和测试命令,可以用命令去测试它的性能,也可以参考CAPI自己写测试工具,各数据库的测试命令形式和参数比较相似,如Hash数据库的命令:tchtest、tchmttest(多线程)、tchmgr(管理数据库),B+数据库命令是以tcb开头的tcbtest、tcbmttest、tcbmgr,而Fixed-length数据库以tcf,Table数据库以tct开头的一组命令。
Hash Database
部分实现原理是根据对TC的代码理解,还有查询各种资料总结出来的结果,重点研究了tch实现原理和各种参数(影响性能)的作用的实现
文件结构
hash数据库文件分为四个部分:数据库文件头,bucket 数组,free pool数组,最后的是真正存放record的部分
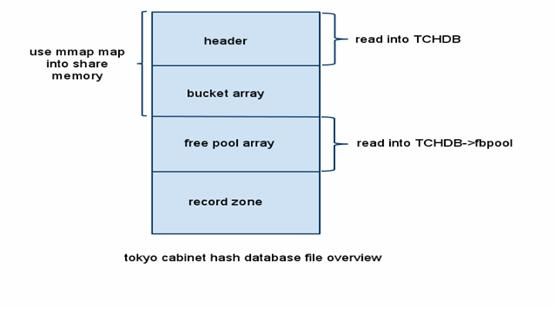
图-1 Hash数据库文件结构图
第一部分是header,固定大小是256字节,存放关于该数据库的一些基本信息,格式如下:
| name |
offset |
length |
feature |
| magic number |
0 |
32 |
identification of the database. Begins with "ToKyO CaBiNeT" |
| database type |
32 |
1 |
hash (0x01) / B+ tree (0x02) / fixed-length (0x03) / table (0x04) |
| additional flags |
33 |
1 |
logical union of open (1<<0) and fatal (1<<1) |
| alignment power |
34 |
1 |
the alignment size, by power of 2 |
| free block pool power |
35 |
1 |
the number of elements in the free block pool, by power of 2 |
| options |
36 |
1 |
logical union of large (1<<0), Deflate (1<<1), BZIP2 (1<<2), TCBS (1<<3), extra codec (1<<4) |
| bucket number |
40 |
8 |
the number of elements of the bucket array |
| record number |
48 |
8 |
the number of records in the database |
| file size |
56 |
8 |
the file size of the database |
| first record |
64 |
8 |
the offset of the first record |
| opaque region |
128 |
128 |
users can use this region arbitrarily |
其中opaque region是预留部分,可以用来做扩展用,例如B+数据库可以看做TCH的扩展,而B+数据库的一些基本信息就是存放在opaque region中。
第二部分是bucket数组,可以将bucket数组下标视为hash的一级索引,存放的数值是对应的记录在文件中的位置。
bucket 数组大小可以设置(bnum参数大小),数组元素是int64 or int32类型。
第三部分free pool管理record部分空闲区域:
free pool数组大小可以设置((1 << hdb->fpow) * 2 * sizeof(HDBFB))),数组元素是结构体
typedef struct { // type of structure for a free block
uint64_t off; // offset of the block
uint32_t rsiz; // size of the block
} HDBFB
重点注意的是:free pool空间大小(数组大小)是固定的且按照rsiz排序,如果管理的free block个数超出范围,则先合并free pool中相邻的block,如果仍超出范围,将丢弃数组前面的记录。
令关注dfunit参数:当对free pool的insert 操作超过dfunit个数时,会在操作数据库时触发磁盘管理。
第四部分是record zero,其中分为两类区域,一类是存放记录的区域, 其存储的数据格式如下:
| name |
offset |
length |
feature |
| magic number |
0 |
1 |
identification of record block. always 0xC8 |
| hash value |
1 |
1 |
the hash value to decide the path of the hash chain |
| left chain |
2 |
4 |
the alignment quotient of the destination of the left chain |
| right chain |
6 |
4 |
the alignment quotient of the destination of the right chain |
| padding size |
10 |
2 |
the size of the padding |
| key size |
12 |
vary |
the size of the key |
| value size |
vary |
vary |
the size of the value |
| key |
vary |
vary |
the data of the key |
| value |
vary |
vary |
the data of the value |
| padding |
vary |
vary |
useless data |
另一类是没有存储记录的区域,其存储的数据格式:
| name |
offset |
length |
Feature |
| magic number |
0 |
1 |
identification of record block. always 0xB0 |
| block size |
1 |
4 |
size of the block |
基本实现
Hash数据库的基本知识:
1) 所有的record是以二叉树的形式组织在同一个bucket上面的.
2) 这个二叉树不是平衡的二叉树
3) 为了解决问题二造成的极端不平衡问题,TC引入了二级hash,以保证这个二叉树尽可能的平衡.
缓存机制
关于cache机制:其实就是一个内存hash数据库(tcmap的8维数组,按照key索引),每次读取数据时(get)会put数据到cache中,当cache中的记录超过最大值(rcnum)时,删除cache中older数据(128为基数)记录
共享内存
插入数据库时,落在mmap共享内存中的数据库不会实时写入到磁盘,落入mmap之外的会实时写入到磁盘中;读取数据时,会读取mmap部分和磁盘部分,如果两部分都有的则合并成结果返回。
参数:xmsiz:map内存映射的真实大小,值必须大于header+bucket部分空间大小,否则设置无效。
查询流程
几点说明 :
1. bucket中存放的offset是数据库文件的中偏移量,可以根据offset读取数据,按照 record有数据时的格式解析得到该record数据记录的大小size,这样可以直接读取数据。
2. 读取时还是分为两部分,先读取mmap中的,再读取磁盘中的
查询的步骤如下图:
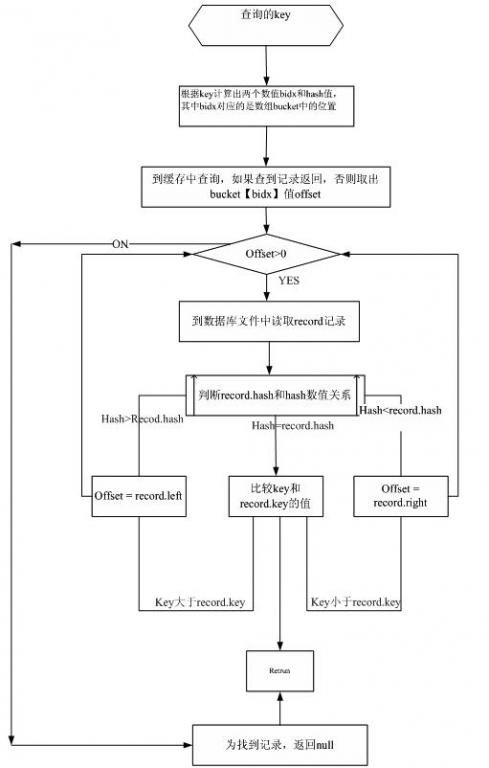
图-2 查询流程
写入流程
写入数据key ,value:
写入的流程如图:
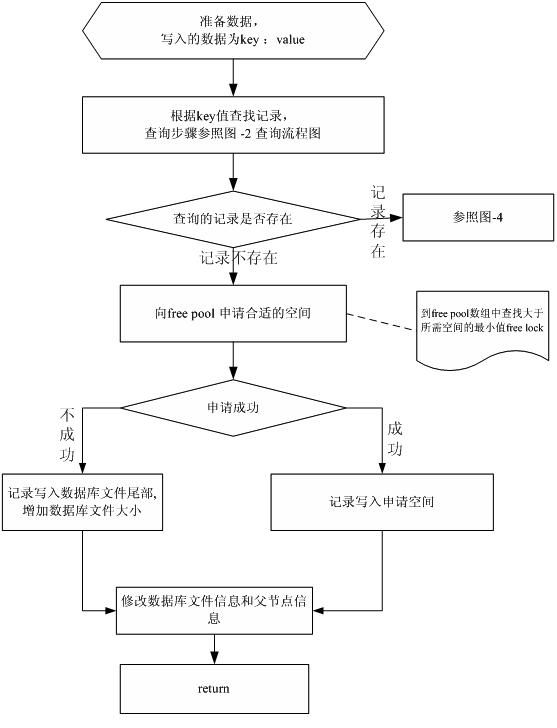
图-3 写入流程
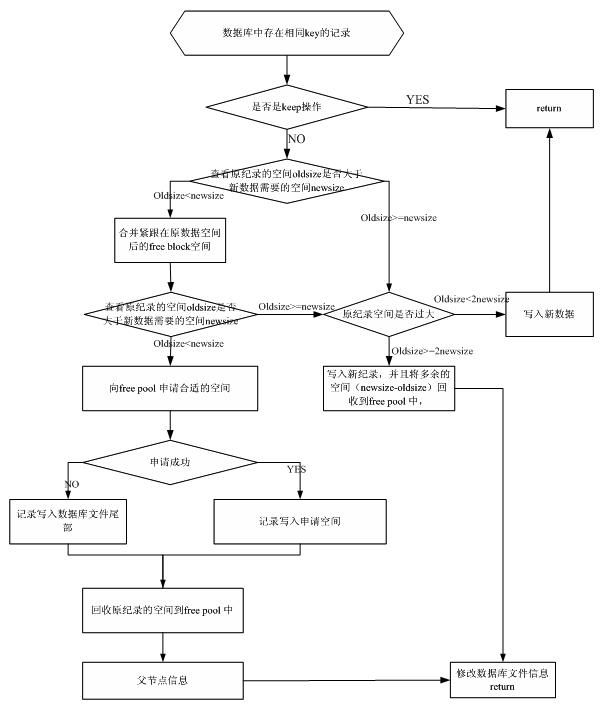
图-4 写入流程
删除流程
删除key值数据库
删除数据步骤:
按照查询步骤查询key
如果不存在key,结束 ;否则 3
将该记录的magic number置为0xb0,将这条被删除记录的block插入到free pool数组中的合适位置
同一个bidx是以二叉树形式组织在一起的,删除了一个数据之后会破坏二叉树的性质,所以需要在二叉树中找到合适的记录来替换删除这条记录之后剩下的位置。如下图调整节点的结构

图5 节点重组
修改数据库头文件信息
free pool管理
free pool的管理是利用一个数组,最多只能管理和数组大小相同的空间个数。该数组按照管理的空间大小排序。
free pool数组大小可以设置((1 << hdb->fpow) * HDBFBPALWRAT * sizeof(HDBFB))),数组元素是结构体
typedef struct { // type of structure for a free block
uint64_t off; // offset of the block
uint32_t rsiz; // size of the block
} HDBFB
申请空间:
通过二分法查找适合的block, free pool数组中比申请空间大的最小值
如果申请失败,则增加文件大小(返回空间的位置是文件的尾部)
空间管理:
对于释放的空间,插入到free pool数组中
如果free pool 达到最大值,对free pool 进行排序(按照off),合并相邻的空间;对free pool 进行排序(按照rsiz),如果free pool 仍达到最大值,放弃free pool中多余部分(放弃数组前面超出范围的管理空间)。
如果free pool 没有达到最大值,按照rsiz排序规则插入数据
每次插入free pool时,会判断是否需要空间回收,相关参数是dfunit(小于 1 时无效)。
空间回收:
对于释放的空间,插入到free pool数组时
判断是否需要回收空间,如果对free pool插入的操作的次数大于dfunit,则执行磁盘回收
如图,回收前和回收后的比较

图-6 回收空间
事务机制
Hash中的事务机制比较简单,在对数据库进行修改之前,会将原纪录信息写入到事务文件中(dbname.wal),当事务出现中断时,会从事务文件中将记录信息回写到数据库中。
B+ tree database
文件结构
B+树索引建立在hash数据库上,其数据存储均在Hash数据库中,文件结构和Hash相同,参照图1 。
第一部分Header,B+将自己的数据库信息存储在Hash头文件的opaque region部分:
| opaque region |
128 |
128 |
users can use this region arbitrarily |
存储的结构如下:
| name |
offset |
length |
feature |
| comparison function |
0 |
1 |
tccmplexical (0x00), tccmpdecimal (0x01), tccmpint32 (0x02), tccmpint64 (0x03), other (0xff) |
| reserved region |
1 |
7 |
not used |
| record number of leaf node |
8 |
4 |
the maximum number of records in a leaf node |
| index number of non-leaf node |
12 |
4 |
the maximum number of indices in a leaf node |
| root node ID |
16 |
8 |
the page ID of the root node of B+ tree |
| first leaf ID |
24 |
8 |
the page ID of the first leaf node |
| last leaf ID |
32 |
8 |
the page ID of the last leaf node |
| leaf number |
40 |
8 |
the number of the leaf nodes |
| non-leaf number |
48 |
8 |
the number of the non-leaf nodes |
| record number |
56 |
8 |
the number of records in the database |
Bucket和free pool部分采用hash的实现。
Record记录的实现和Hash中的实现是一致的,不同情况在于况key和value的值是有格式的:
当record储存的是叶子节点时:
Key: nodeid(B+树种给节点的编号, 叶节点从1开始编号)
Value:
| name |
offset |
length |
feature |
| previous leaf |
0 |
vary |
the ID number of the previous leaf node |
| next leaf |
vary |
vary |
the ID number of the next leaf node |
| record1 |
|||
| record2 |
|||
| 。。。 。。。 |
|||
| recordn |
|||
其中每个record的格式如下:
| name |
offset |
length |
feature |
| key size |
0 |
vary |
the size of the key |
| value size |
vary |
vary |
the size of the value |
| duplication number |
vary |
vary |
the number of values with the same key |
| key |
vary |
vary |
the data of the key |
| value |
vary |
vary |
the data of the value |
| duplicated records |
vary |
vary |
a list of value sizes and value data |
当record储存的是非叶子节点时:
Key: #(nodeid-2^48-1) (非叶子节点从2^48+1开始编号)
Value:
| name |
offset |
length |
feature |
| accession ID |
0 |
vary |
the ID number of the first child node |
| index1 |
|||
| index2 |
|||
| 。。。 。。。 |
|||
| indexn |
|||
其中每个index的结构:
| name |
offset |
length |
feature |
| page ID |
0 |
vary |
the ID number of the referred page |
| key size |
vary |
vary |
the size of the key |
| key |
vary |
vary |
the data of the key |
基本实现
缓存机制
B+数据库中定义了两个cache用来缓存叶子节点(leafc)和非叶子节点(nodec),它们的大小受控于参数lcnum(leafc存储最大的叶子节点数目)和ncnum(nodec存储最大的非叶子节点数目)。
下面有几点重要的说明:
查询记录时,会将叶子节点和所有访问过的非叶子节点缓存到cache中
当发生修改操作时,只会对cache中的节点进行修改
每次向cache中的节点新增记录时,都需要申请内存,节点中保存的是指向内存的指针
当发生删除操作时,只会设置cache中节点的删除标示
只有当cache中的节点过大(leafc记录大于lcnum或者nodec大于ncnum)时,从cache中删除节点,如果这些节点已经变化(修改、新建或者删除),则将变化保存到磁盘中
分裂节点
对B+中节点的几点说明:
B+中非叶子节点中的indexList是按照key排序(可以选择自己的排序规则),不是按照nodeid排序。
节点中的记录过大时发生分裂,将原节点从中间分裂成两个节点,并调父节点的数值
分裂活动只会分裂出同级的节点,且可能父节点
介绍一下只有一个节点时的分裂过程:
数据库在启动时会新建一个节点(叶子节点)作为root节点,分配的节点号pid = 0,申请的recordList空间是lmemb+1
(lmemb:叶子节点最多可以存储的记录数);
假设lmemb =2,则当存储到第三条记录时发生裂变
从recordList中间裂变成两个节点,其中pid=1是新生成的节点
检查原节点pid=0是否有父节点,如果没有则新生成非叶子父节点(如果有父节点,则将pid=1,key=key2加入到原父节点中)
对于非叶子节点的分裂和上述过称类似,一样从记录集合中间记录分裂成两个节点
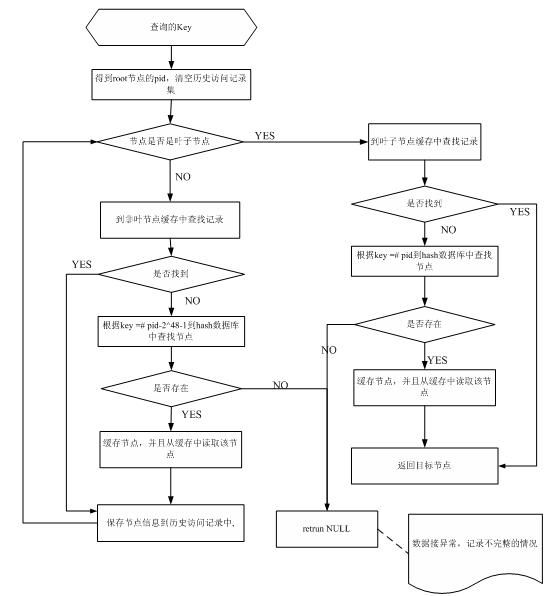
查询流程
其中查询Hash数据库的流程参考hash部分的查询流程
查询分两部分:
根据key值查询叶子节点leaf
根据key到leaf的记录集中查找记录
下图是介绍根据key值如何查询叶子节点leaf流程:
如果查找到leaf节点,则可以直接得到leaf中的记录集,比较记录key值,查找对应的record记录
写入流程
写入流程
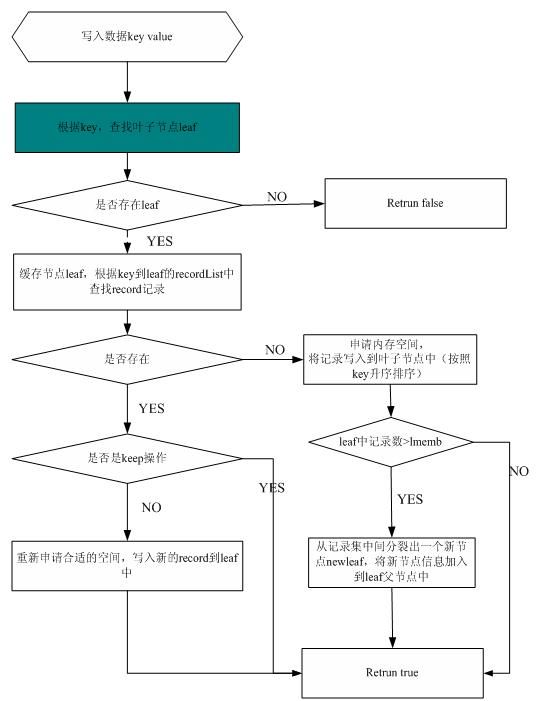
几点说明:
申请的空间均是在内存中申请的
当节点从缓存中删除时会释放申请的内存空间
关于通过key查询leaf流程和节点分裂方法参照3.2.3和3.3.2
节
支持范围查询和模糊查询,
范围查询中得到需要查处的key范围,
隐患
对于分配节点的id:
叶子节点的分配是从pid = bdb->lnum ++ ,bdb->lnum初始 0;
而非叶子节点的分配从(bdb->nnum++)+ (1LL<<48)+1,,bdb-> nnum初始 0。
当删除记录时均没有对lnum和nnum值进行回收管理。