Clickhouse高可用分布式数据库研究与实践
随着物联网IoT、5G时代的到来,设备感知、告警存储、业务交易等数据越来越大,大数据分析、联机分析(OLAP)成为非常重要的环节。由于市场上其他开源产品框架多样化,操作复杂等是当前面临的主要问题。
Clickhouse
什么是Clickhouse?
ClickHouse是Yandex公司开源的一个列式数据库管理系统(DBMS),而不是单一的数据库,在 ClickHouse 中,数据始终是按列存储的,主要用于在线分析处理查询(OLAP),与Hadoop、Spark相比,ClickHouse更轻量。相对行式数据库,如Mysql、Oracle、SqlServer等,是把同一行的数据放到相邻同一数据块种,而列式存储是把同一列的数据放到相邻同一数据块种,这样在进行计算类查询时,可以大大减少IO,返回结果更快。
面临的问题
随着公司业务高速发展,业务面越来越广,数据量也越来越复杂。现有Oracle数据库集群模式,存在一定缺陷:
-
集群难以扩容,并且存在一定的不可用性风险。
-
数据查询性能较慢,虽然可以通过分库分表分区进行优化,但操作复杂且需要更改业务代码。
-
针对在线分析处理查询无论从性能还是处理速度都无法满足需求。
架构

Clickhouse高可用分布式集群架构如上图:集群是由分区表、复制表及ZK组成。
复制表主要作为副本数据存在,通过在zk设置主节点表数据信息实现数据同步,分区表不存储数据,主要用来映射各节点数据集,从而达到针对所有节点数据进行查询目的。
核心特性优势
开源的列存储数据库管理系统,支持线性扩展,简单方便,高可靠。下图为与其他DBMS数据库的性能对比:

-
容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10亿级别。
-
支持数据复制和数据完整性 ClickHouse使用异步的多主复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据。在大多数情况下ClickHouse能在故障后自动恢复,少数复杂情况下需要手动恢复。
-
支持近似计算 用于近似计算的各类聚合函数,基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据,不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。
-
强有力的数据压缩 在一些列式数据库管理系统中(例如:InfiniDB CE 和 MonetDB) 并没有使用数据压缩。但是,若想达到比较优异的性能,数据压缩就起到了至关重要的作用。下图为Clickhouse与其他数据库压缩对比:
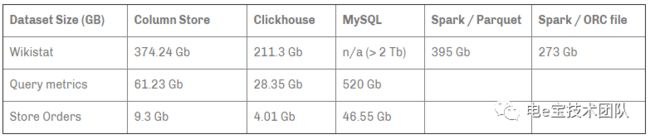
-
数据的磁盘存储
许多的列式数据库(如 SAP HANA, Google PowerDrill)只能在内存中工作,这种方式会造成比实际更多的设备预算。ClickHouse被设计用于工作在传统磁盘上的系统,它提供更低的存储成本。
-
支持SQL
ClickHouse支持基于SQL的声明式查询语言,兼容mysql协议。支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询,不支持窗口函数和相关子查询。
-
实时数据更新
ClickHouse支持在表中定义主键。为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在MergeTree中。因此,数据可以持续不断高效地写入到表中,并且写入过程中不会存在任何加锁的行为。
-
向量引擎
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。
-
多核心并行处理
ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询。
-
适合在线查询
在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
-
分布式处理
在ClickHouse中,数据可以保存在不同的shard上,每一个shard都由一组用于容错的replica组成,查询可以并行地在所有shard上进行处理。这些对用户来说是透明的。
不完美之处:
-
没有完整的事务支持。
-
不支持Update/Delete操作。
-
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
应用场景
-
绝大多数请求都是用于读访问的。例如:电费查询,用户信息查询,运营后台报表查询等业务场景。
-
数据只是进行插入,没有更新或修改类操作。例如:历史订单信息,用户操作记录等场景
-
表中包含大量列/字段。例如:用户行为操作信息。
-
在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)。例如:查询某个人历年交费订单中交费金额大于N元的记录,针对大数据量前提下可以满足高吞吐快速查询需求。
高可用分布式实践
Clickhouse副本是基于表级的,只有 MergeTree 系列里的表可支持副本且需要依赖ZK,所以服务器里可以同时有复制表和非复制表。
副本不依赖分片,每个分片有它自己的独立副本。对于 INSERT 和 ALTER 语句操作数据的会在压缩的情况下被复制。而 CREATE,DROP,ATTACH,DETACH 和 RENAME 语句只会在单个服务器上执行,不会被复制。

Clickhouse数据复制依赖ZooKeeper,“ZooKeeper 中该表的路径”对每个可复制表都要是唯一的,不同分片上的表要有不同的路径。
数据复制实验架构图:
创建了3个分片,每个分片2个副本,每个分片上创建了一张分布式表。
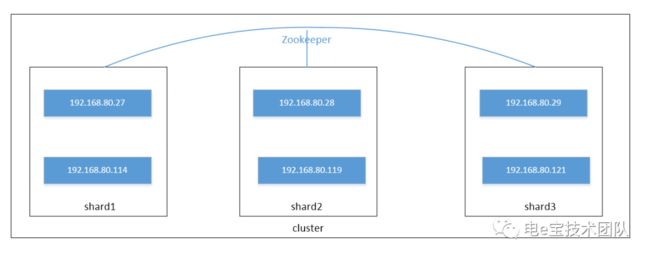
如下图为集群状态:

每个node节点创建复制表及分布式表
1、验证数据复制功能:
插入数据并进行查询:
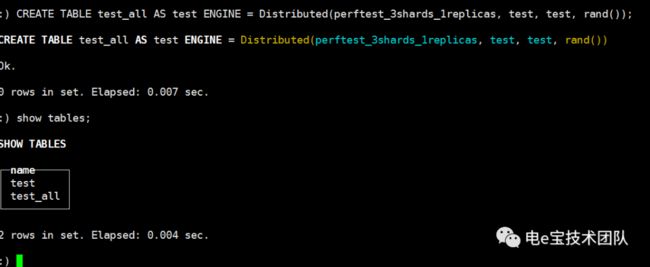
在另一副本节点查询:
结论:通过以上实验可以得出:通过创建复制表,可以实现副本之间数据实时同步。
2、验证分布式表查询功能:

测试数据:Select count(*) 300亿 数据 0.9秒

结论:从以上图中可以得出通过使用分布式表可以完成所有分片上数据查询,实现了分布式处理,并且在大数据量下可以大大提高查询速率。
生产中的实战
目前Clickhouse在APM应用性能监控中进行了实地应用实战,采用5节点的高可用分布式集群模式,目前数据保存为9天数据,单节点所占数据量在300G左右,在普通磁盘和配置服务器上数据处理可达18万条/s,其主要用来存储针对线上应用服务接口请求、SQL执行、业务链关系、线程信息、JVM信息、响应及吞吐等应用数据信息。并将其进行整合完成数据分析和展示。
结语
通过实践、分析、研究来看,Clickhouse在大数据量处理、分析、分布式查询、数据一致性以及扩展性、容错性上都有较好的表现,但Clickhouse只是针对海量数据(PB级)存在较大优势,同时还存在一些缺陷,针对数据无法进行UPDATE或DELETE操作,也不支持事务。Clickhouse的使用还要结合具体业务场景以及数据量级进行综合分析判断是否合适。
后续规划
目前Clickhouse在APM应用性能监控上进行了实战,在应用链路请求分析,数据SQL执行分析等方面进行了广泛应用,解决了在大数据量、复杂数据分析查询上进行应用多维度监控的效果,在后续中会根据ELK日志分析、电e宝查询业务等方面进行广泛推广使用。
