基于PythonDjango框架的电影推荐系统
目 录
摘 要 I
Abstract II
1绪论 1
1.1选题背景及意义 1
1.2国内外研究现状 2
1.3推荐算法研究 5
1.3.1协同过滤算法 5
1.3.2基于内容的推荐算法 5
1.3.4基于标签的推荐算法 6
1.4本文研究目标和研究内容 6
2相关技术介绍 7
2.1系统实现相关技术的研究 7
2.2 Python语言研究 9
2.3 Django框架研究 10
2.4 SQLite数据库研究 11
3系统分析 13
3.1需求分析 13
3.2可行性分析 13
3.2.1社会可行性分析 13
3.2.2 技术可行性分析 13
3.3用户功能需求 14
4系统设计 15
4.1系统总体架构 15
4.2电影爬虫的模型设计 16
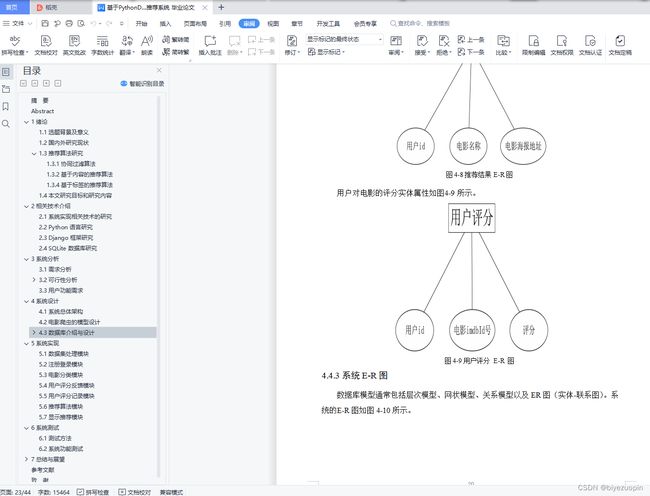
4.3数据库介绍与设计 17
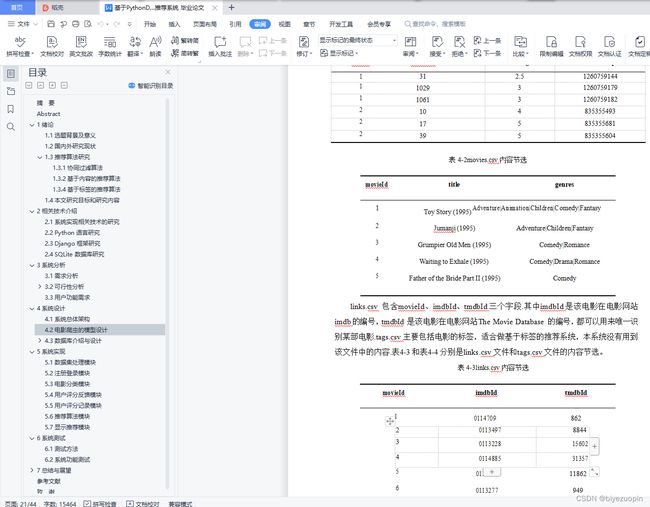
4.3.1实验数据集介绍 17
4.3.2数据库逻辑结构设计 19
4.4.3系统E-R图 20
4.4.4系统数据表设计 21
5系统实现 24
5.1数据集处理模块 24
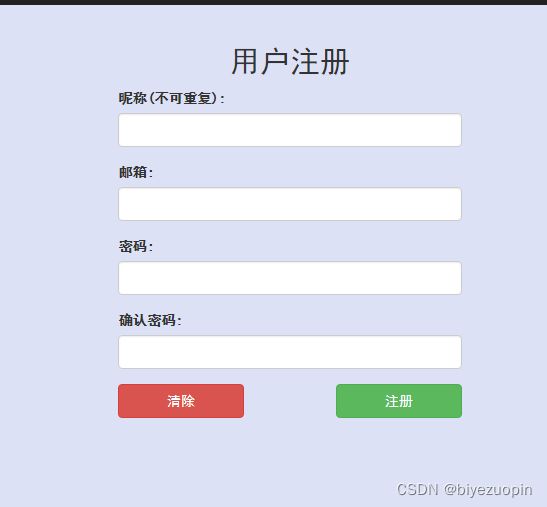
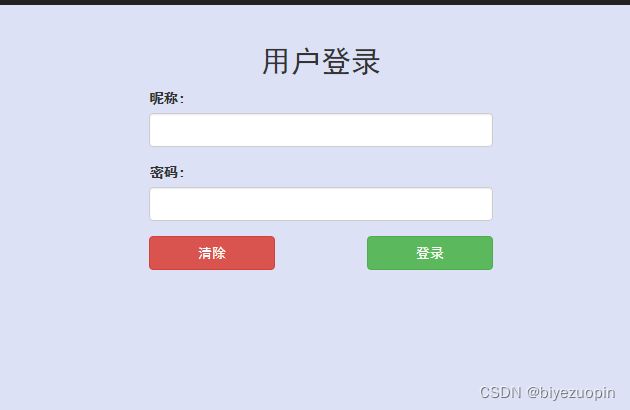
5.2注册登录模块 24
5.3电影分类模块 25
5.4用户评分反馈模块 27
5.5用户评分记录模块 29
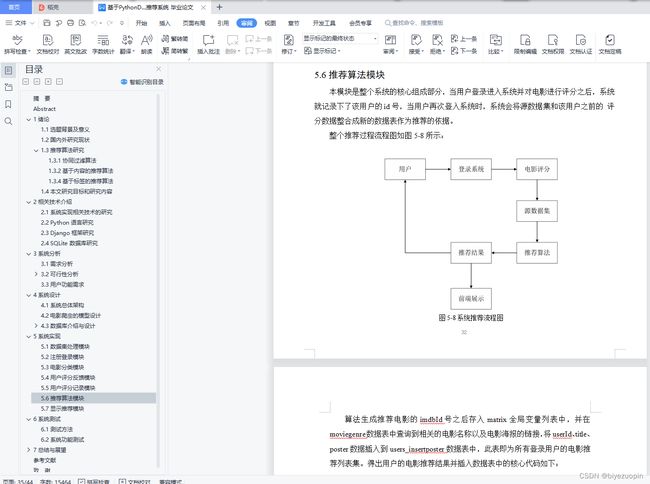
5.6推荐算法模块 31
5.7显示推荐模块 33
6系统测试 35
6.1测试方法 35
6.2系统功能测试 35
7总结与展望 36
7.1总结 36
7.2不足之处及未来展望 36
参考文献 38
致 谢 40
3系统分析
3.1需求分析
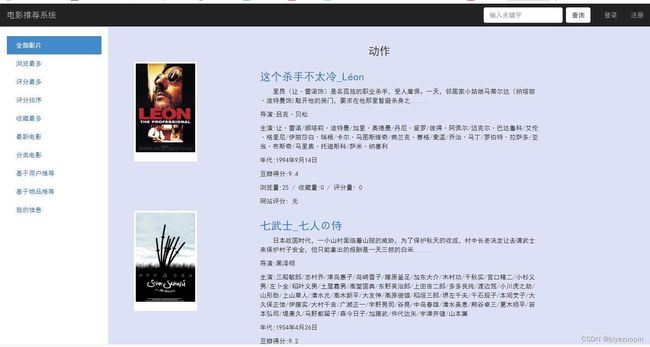
随着电影市场的迅速发展,每天都有大量电影上映。人们都希望可以高效的在海量电影库中找到自己可能会喜欢的电影.以节省寻找电影的时间。电影推荐系统能给用户带来便利.本文要实现的是一个面向用户的个性化电影推荐系统,根据 movielens数据集里面大量用户对电影的评分数据,通过计算用户相似性、电影相似性,实现为用户推荐符合其兴趣的电影。
本文实现的个性化电影推荐系统有以下几点基本需求:
(1)数据集:每个用户所评电影数量要多,尽量广泛涉及大量电影
(2)推荐算法:推荐效果要良好
(3)包括用户注册登录在内的整个 web系统
(4)系统要易于扩展和维护
现在中国大部分的家庭都喜欢在家里置办属于自己风格的家庭影院或者到电影院观看电影。但是,仍然有很多人喜欢在手机和电脑等设备看电影。因为移动设备比较方便,随时随地都可以享受到看电影的乐趣。所以,一个可以在移动设备或电脑观看电影的网站就非常重要了。电影网站为了提高劳动的效率、节约成本、提高服务质量,我就开发了此款网站。用以方便用户可以随时随地的在互联网上找到各种类型电影视频。通过这个网站,可以很快实现一些常用的服务,并保证无错、高效。比如,视频搜索,视频点播,以及视频下载等基本功能。让用户打开本网站就能立刻在线观看自己喜欢的视频,省掉安装家庭影院的一大笔资金,同时也避免了到电影院观看电影的麻烦步骤。
3.2可行性分析
3.2.1社会可行性分析
近年来,随着中国国民经济的不断发展,人民生活水平不断提高,人均可支配收入不断增加,人们的消费需求和消费也越来越多。据相关统计分析,在2014全国电影票房收入约100亿元,在2013,电影票房同比增长约44%,强劲增长的基础上,同比增长约60%。改革开放以来,全国城市票房已经增加了约10倍,平均涨幅超过35%。今年的房屋总量占比,国内电影票房达57亿元左右,占全年票房的55%左右。
3.2.2 技术可行性分析
1.细化网站目标。具体目标的技术可行性分析。电影信息摘要,了解网站建设的目标和具体要求,功能实现中的每一个具体的目标和功能的技术,同时也考虑到需要什么条件和多少人需要实现,并列出每个具体目标的内容,任务列表。
2.网站可用性分析。网站的设计要求使它易于使用,而不仅仅是一个简单的信息和安排数组。此要求与网站的布局和服务器的功能有关。
3、网站的互动分析。互动是现代网站发展的趋势,网站的互动性能可以提高网站的处理功能和存储容量的需求,内部结构设计可以相应调整。
4.网站的性能分析。网站的用户数量随着网站的性能和功能的不断变化,在保证网站性能的前提下,不断满足更多用户的需求,并不断地进行规划、设计和系统维护。站点的整体性能一般通过站点的响应时间和处理时间以及平均用户等待时间和系统输出来衡量。本文转载自http://www.biyezuopin.vip/onews.asp?id=13964因此,为了提高网站的性能,可以通过调查用户的数量和信息处理量来确定网站服务器的功能。
3.3用户功能需求
如图 3-1是系统中用户的用例图,有 5个用例,分别是注册、登录、注销、评分、查看推荐结果。
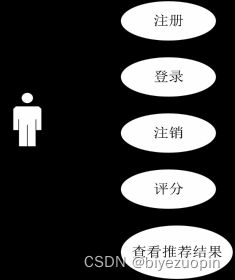
图3-1用户的用例图
4系统设计
4.1系统总体架构
本文从互联网上下载movielens数据集,经过数据重组和筛选,基于两种推荐算法得出推荐结果保存至SQLite数据库中,并通过Django框架进行前端展示.本系统采用B/S(浏览器/服务器)体系结构,用户通过浏览器就能和网站上的内容交互。
实现本系统主要需要以下几种编程语言:
(1)Python:进行后台开发,写推荐算法,和SQLite数据库交互,将用户的数据存储到数据库中,又将生成的推荐列表展示到前端页面。
(2)Html5:进行前端页面的开发。
(3)Css3:美化前端页面,特别是对电影分类板块做处理。
(4)Jquery:实现提交表单和首页中的星星评分效果。
import asyncio
import logging
import aiohttp
from bs4 import BeautifulSoup
from crawler_utils.utils import timer
base_url = 'https://movie.douban.com/top250'
results = {}
class Movie:
def __init__(self, id, title, description, star, leader, tags, years, country, director_description, image_link):
self.id = id
self.star = star
self.description = description
self.title = title
self.leader = leader
self.tags = tags
self.years = years
self.country = country
self.director_description = director_description
self.image_link = image_link
async def fetch(url):
async with aiohttp.ClientSession()as session:
async with session.get(url) as response:
print(response.status)
assert response.status == 200
return await response.text()
async def write_images(image_link, image_name):
async with aiohttp.ClientSession()as session:
async with session.get(image_link) as response:
assert response.status == 200
with open('movie_images/' + image_name + '.png', 'wb')as opener:
while True:
chunk = await response.content.read(1024)
if not chunk:
break
opener.write(chunk)
async def parse(html):
soup = BeautifulSoup(html, 'html.parser')
movies_info = soup.find('ol', {'class': 'grid_view'})
movies = []
for movie_info in movies_info.find_all('li'):
pic = movie_info.find('div', {'class': 'pic'})
picture_url = pic.find('img').attrs['src']
movie_id = pic.find('em').text
url = movie_info.find('div', {"class": "info"})
title = url.find('span', {'class': 'title'}).text
# 保存图片文件到本地
# if picture_url is not None:
# await write_images(picture_url, title)
info = url.find('div', {'class': 'bd'})
movie_detail = info.find('p')
quote = info.find('p', {'class': 'quote'})
if quote is not None:
description = quote.find('span').text
else:
description = ''
print(title + 'description is None')
star = info.find('div', {"class": 'star'}).find('span', {'class': 'rating_num'}).text
tags = movie_detail.text.strip().split('\n')[-1].split('/')[-1].split(' ')
tags = [tag.strip() for tag in tags]
years = movie_detail.text.strip().split('\n')[-1].split('/')[0].strip()
country = movie_detail.text.strip().split('\n')[-1].split('/')[1].strip()
temp = movie_detail.text.strip().split('\n')
try:
director_description = temp[0].split('/')[0].strip().split('\xa0')[0].split(':')[1]
except IndexError:
director_description = ''
try:
leader = temp[0].split('/')[0].strip().split('\xa0')[-1].split(':')[1]
except IndexError:
leader = ''
assert title is not None
assert star is not None
assert leader is not None
assert years is not None
assert country is not None
assert director_description is not None
assert tags is not None
assert picture_url is not None
assert movie_id is not None
movies.append(Movie(title=title, description=description, star=star, leader=leader, years=years, country=country, director_description=director_description, tags=tags, image_link=picture_url,
id=movie_id
)
)
next_page = soup.find('link', {'rel': 'next'})
if next_page is not None and next_page.attrs.get('href'):
next_link = base_url + next_page.attrs['href']
else:
print('finished!')
next_link = None
return movies, next_link
def write_movies(movies):
with open('movies.csv', 'a+')as opener:
if opener.tell() == 0:
opener.writelines(','.join(['id', 'title ', 'image_link ', 'country ', 'years ', 'director_description', 'leader', 'star ', 'description', 'tags', '\n']))
for movie in movies:
opener.write(','.join([movie.id, movie.title, movie.image_link, movie.country, movie.years, movie.director_description, movie.leader, movie.star, movie.description, '/'.join(movie.tags), '\n']))
async def get_results(url):
html = await fetch(url)
movies, next_link = await parse(html)
write_movies(movies)
return next_link
# results[url] = movie
async def handle_tasks(work_queue):
while not work_queue.empty():
current_url = await work_queue.get()
try:
next_link = await get_results(current_url)
print('put link:', next_link)
if next_link is not None:
work_queue.put_nowait(next_link)
except Exception as e:
logging.exception('Error for {}'.format(current_url), exc_info=True)
# async def main():
# async with aiohttp.ClientSession() as session:
# html = await fetch(session, url)
# links = await parse(html)
@timer
def envent_loop():
q = asyncio.Queue()
q.put_nowait(base_url)
loop = asyncio.get_event_loop()
tasks = [handle_tasks(q)]
loop.run_until_complete(asyncio.wait(tasks))
envent_loop()